Una Arquitectura Propuesta
Como en muchas cosas en el ambito de la computación, mientras
mas sepamos sobre algo, mejor podemos solucionar nuestros problemas.
En el caso de la creación de CG's, los computadores que se utilizan comunmente
son equipos de uso genérico (PC's), o a lo mas computadores genéricos con soporte
en hardware para ayudarle en el calculo gráfico
(ver arquitecturas existentes)
, pero no tenemos arquitecturas completas destinadas a CG's, por lo tanto vamos
a darnos a la entretenida tarea de diseńar una, pero totalmente orientada a la generación
de imagenes 3D de calidad fotográfica, es decir, vamos a crear hardware especializado
aprovechando que sabemos cual va a ser su función.
Para esto nos basaremos en el mejor y mas lento de los algoritmos de rendering que se han creado:
Ray Tracing. Este algoritmo tiene algunas caracteristicas importantes:
realiza una gran cantidad de calculo por cada punto de la pantalla (2d) que va a generar a partir
del un universo 3D dado, y que el calculo de cada punto es totalmente independiente del resto
de los puntos. Esto implica que podemos paralelizar el proceso de rendering tanto como queramos.
Entonces, las características que queremos (inicialmente) para nuestra máquina son:
- Poseer una memoria donde almacenar objetos (3d) que queremos proyectar en un plano 2D (rendering).
- Poseer un conjunto de mini-procesadores, funcionando en paralelo, que ejecuten el algoritmo
de RayTracing y entreguen el valor del Pixel calculado.
- Queremos ademas que a la imagen 2D generada se le apliquen filtros gráficos, como Anti-Aliassing.
En lo posible, que esto se realize lo mas rápido posible, aprovechandose del paralelismo anterior.
- Debe haber una CPU que organize todo el proceso, y que corra los "programas" de esta máquina.
- Una unidad de I/O (input/output) para el traspaso de información (ej: carga de archivos, salida de
imagen a pantalla).
Veremos un diagrama general de esta nueva máquina, y luego
revisaremos cada uno de estos puntos y crearemos harware ad-hoc para generar imágenes lo mas
rápido posible.
La Implementación
Crearemos un harware que cumpla con las condiciones antes descritas, optimizado para
velocidad, pero no preocupandonos mucho del costo. Debemos cuidarnos de hacer
un sistema relativamente "escalable", para poder darle mas poder en caso necesario
(para que no quede obsoleto muy rápido :).
Hay que notar que el siguiente hardware está concebido como una estación de trabajo
especializada en generación de gráficos 3D, pero también podría implementarse como
una tarjeta de expansión para máquinas multi propósito. Eso si, con los componentes típicos
utilizados actualmente sería una tarjeta bastante grande, cara y dificil de enfriar.
Haremos algunas suposiciones en algunas etapas del diseńo, las cuales serán descritas
en cada punto. Hay ciertas cosas que no están completamente implementadas, o
suficientemente detalladas, debido a que caen relativamente fuera del alcance de este informe.
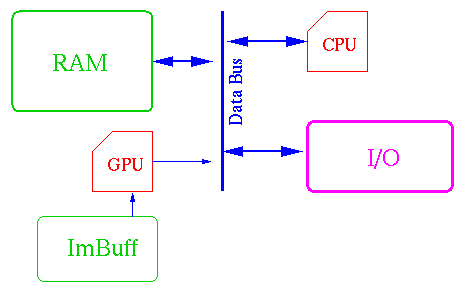
El diseńo global
Con los requerimientos que nombramos, podemos hacernos una idea global
de la máquina: Una gran memoria compartida, unida a un cluster de procesadores
especializados, un bus de salida de pixeles que pasan por un filtro gráfico y
una estructura de I/O.
Todo esto coordinado por una CPU.
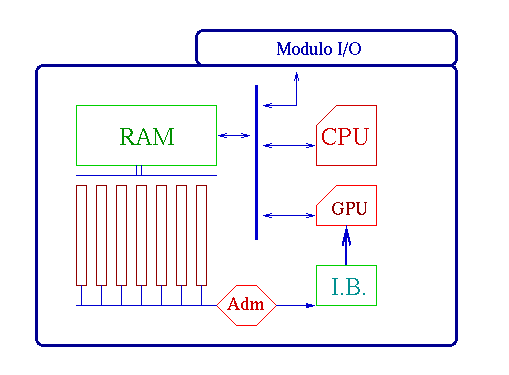
El cerebro del rendering:
El cluster de RPU's
Para aplicar nuestra idea de calcular pixeles en paralelo, tendremos una colección de
microprocesadores que sean capaces de ejecutar velozmente el algoritmo de RayTracing.
Para esto necesitamos que sean capaces de ejecutar instrucciones de punto flotante, mas algunas
instrucciones de control de flujo. A estos cuasi-FPU's los llamaremos RPU (Rendering Procesor
Unit), y le daremos el poder (en forma de microcódigo) de calcular un pixel en función de la
descripción de objetos en un universo 3D.
Por las siguientes razones agruparemos varias de estas RPU's en una sola placa desmontable:
- Haremos que cada RPU (en la misma placa) calcule pixeles cercanos. Esto es para
poder crear cache´s de lectura de la memoria central para cada placa.
- El algoritmo de RayTracing lo pondremos en una ROM (para abaratar el costo de cada RPU)
con un bus de instrucciones internos a cada placa. Para que no haya problemas con el uso
de este bus, pondremos un caché de instrucciones a cada RPU dentro de la placa.
- Tendremos un solo bus de salida de pixeles por cada placa. Esto abarata el costo y la
complejidad de la arquitectura, basandonos en el supuesto que las velocidades de transferencia
en el bus son despeciables con respecto a los tiempos de calculo de las RPU's.
- Usaremos un bus independiente para la entrada de datos, puesto que este es de uso mucho
mas intensivo que el bus de salida. De hecho, podemos optimizarlo para que varias (2 o 3)
RPU's puedan acceder al caché simultáneamente.
El siguiente diagrama ilustra todas estas ideas:
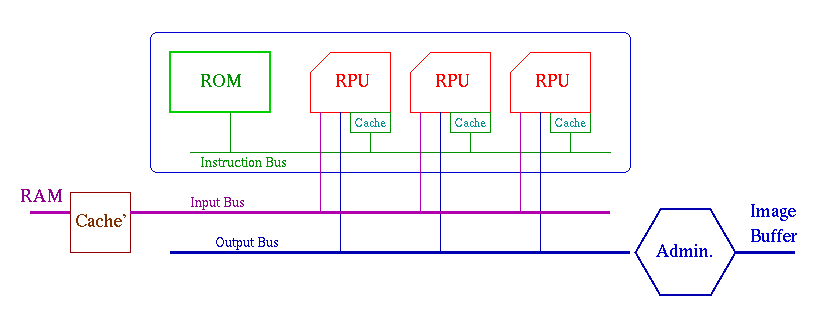
La memoria
Necesitamos un almacén de información (RAM) para contener las definiciones de objetos
de nuestro universo 3D, además de las instrucciones de los programas que serán ejecutados
en este computador, y como almacen de las imagenes 2D en su version definitiva (despues del rendering
y la aplicación de filtros).
Como veremos en el siguiente punto, los procesadores encargados del rendering NO neceitan escribir
en la RAM (pero si el programa, por eso que es RAM y no ROM), sólo necesitan leer, por lo
que diseńaremos la salida de datos de una forma especial:
La zona que contiene las definiciones de objetos será constantemente accesada por
las RPU's, por lo que a éstos últimos les agregaremos cachés de objetos. Como sabemos
que la información es solo leída por las RPU's no debemos complicarnos mucho
con las posibles colisiones de modificación (no necesitamos semaforos ni nada por el estilo para
mantener integridad, por lo menos en lo que se refiere a las RPU's).
En el unico caso en que esto cambia es cuando el programa principal necesita actualizar
los objetos en la RAM (ie: leer desde la unidad de I/O) en cuyo caso se detiene el funcionamiento
de las RPU's.
Otra área de la memoria (que puede ser independiente del área de memoria de objetos)
se encargará de contener al "programa" de esta máquina, el cual será ejecutado
por la CPU. Necesitamos, tambien, memoria para almacenar la imagen ya procesada (o
las imagenes en caso de crear animaciones). Obviamente necesita ser accesada
por el módulo de I/O.

Pixel Output
La misión de cada una de las RPU's es, a partir de un universo 3D, calcular el
color de un determinado pixel, luego de un complicado calculo. Necesitamos
agrupar todos los pixeles calculados por las RPU's en un solo lugar, para
poder darle los toques finales a la imagen.
Asumiremos que el tiempo traspaso de información (de un pixel) de RPU a memoria
es despreciable con respecto al tiempo de calculo, por lo que usaremos
un solo bus de salida para todas las placas de RPU's, controlado por
un administrador, y llevado hacia un Image Buffer previo
al pre-proceso a que será sometida la imagen (para generar la version final).
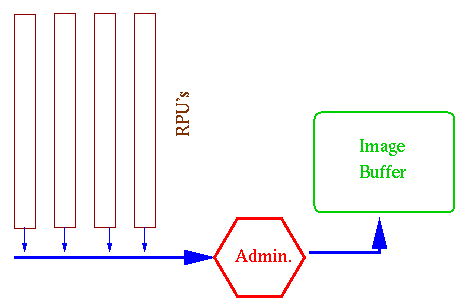
El Post Proceso
Generalmente, despues que el algoritmo de RayTracing genera una imagen,
se desea aplicar ciertos algoritmos gráficos que permiten mejorar/alterar
la calidad de esta. Por ejemplo podemos aplicar Anti-Aliasing, Blur,
filtros de colores, etc. Algunos de estos son bastante "pesados"
en cuanto a procesamiento, y además algunos de ellos son
poco paralelizables. Lo que si podemos hacer es aprovecharnos
de que la mayoria de estos filtros se basan en modificar un pixel
mirando los pixeles cercanos. Esto significa que podemos ir calculando
los efectos a medida que los pixeles llegan desde las RPU's (wooow!).
El aplicar filtros "pesados" podria formar un cuello de botella en el sistema.
Esto depende en gran medida de la cantidad y calidad de RPU's y de la cantidad
y complejidad de los filtros. Por lo tanto es bastante deseable que nuestro procesador
gráfico sea suficientemente poderoso. De hecho, es el pedazo de hardware mas poderoso
y complicado del sistema: necesita acceder al Image Buffer para detectar los pixeles
que han llegado, hay que calcular los algoritmos de los filtros, en donde se puede
necesitar mucho calculo de punto flotante. Debe ser programable y controlable por la CPU
del sistema. Debe tener acceso a la RAM de la máquina para almacenar la imagen definitiva, etc.
A este procesador le llamaremos nuestro GPU ("Graphics Processor Unit"), y su diseńo depende
en grán medida de pruebas empíricas, las cuales, obviamente, no podemos realizar todavía.
Un analisis de los algoritmos que deseamos aplicar podría llevarnos a decidir agregar
otro procesador poderoso que ayude en el calculo. Por ejemplo: En las imágenes 2D que se
generan a partir de mundos 3D se genera un efecto indeseable llamado "Aliasing". Existe un
algoritmo que lo elimina (llamado anti-aliasing) pero que requiere gran cantidad de calculo.
En particular, es complicado decidir en que parte de la imagen se debe aplicar. Por lo tanto
podríamos tener un procesador calculando donde aplicar anti-aliasing, y otro ejecutando el
algoritmo paralelamente.
Otro punto importante es que el diseńo del image buffer debe ayudar a la GPU a detectar
los pixeles que han cambiado desde el ciclo anterior. Un método posible es
"organizar" el buffer como una matriz de pixels (que equivalen a la imagen) y agregar
checksums en las columnas y filas, para poder detectar cuando y donde
se produjo algún cambio.

Nuestro (o nuestros) GPUs estarán conectados (como veremos mas adelante) al bus de datos
en que cuelgan la CPU, el módulo de I/O y obviamente la RAM.
Aqui podemos ver un diagrama completo del sub-sistema de post-procesamiento.
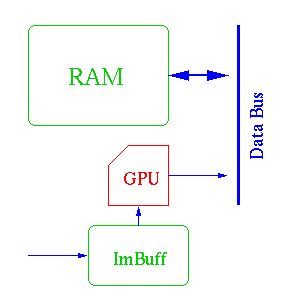
El Gran Bus
Tal como se especificó anteriormente, la memoria RAM tiene dos puertas de acceso: una de solo
lectura para los RPU's y otra de lectura y escritura. Esta última será para la CPU, la GPU y el
módulo de I/O.
La CPU debe coordinar el correcto funcionamiento del sistema. Debe decirle a los RPU's cuales
pixeles renderear, y debe decirle a la GPU cuales efectos calcular. Por lo tanto, su misión
es cada cierto tiempo dar "ordenes", lo cual practicamente no hace uso del bus de datos. En ciertos
momentos debe hacerlos: para traer a su caché de instrucciones el trozo de programa
que se está ejecutando, para modificar los objetos con el paso del tiempo (para hacer
animaciones), y prácticamente nada mas. Como tenemos tanto tiempo libre
existe la posibilidad de aprovechar la CPU ayudando a la GPU a realizar ciertos calculos, por
ejemplo interceptar los pixeles que van hacia la RAM, hacer un procesamiento de color, y luego
escribirlos en la RAM. Con estos procesos simples (filtros de color sencillos) es posible
coordinarse sin muchos problemas y no agota demasiado el bus de datos.
El módulo de I/O puede compartir el mismo bus de datos en el caso que no necesitemos
aplicaciones real-time. Es decir, si no nos molesta que la generación de imagenes para
una animación se tome su tiempo al escribir a disco, entonces podemos dejar que el módulo de I/O use
el bus de datos para leer de la memoria la imagen procesada y la almacene (y/o la muestre
en pantalla). En caso de necesitar aplicaciónes en real-time (juegos, y algunos otros)
exigiendonos mostrar en pantalla los resultados apenas se generan, entonces
necesitaremos un bus dedicado (una especie de DMA) para acceder a la memoria.
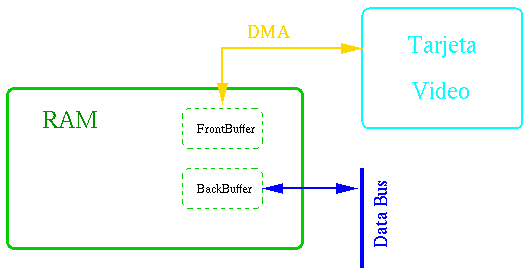
Para estos casos debemos tener un doble buffer en RAM para poder mostrar por pantalla
la última imagen generada, mientras que calculamos la siguiente. Esto significa
una RAM mas grande y un bus dedicado. Hay que destacar que para este tipo de
aplicaciones el módulo de I/O solo haria lectura en la RAM, por lo tanto
seguiriamos teniendo pocos conflictos de coordinación (solo la CPU y la GPU escriben).
En caso que el módulo I/O quiere escribir (cosa poco frecuente) podemos detener
temporalmente el acceso a la RAM. Otra alternativa es que el módulo de I/O se cuelgue
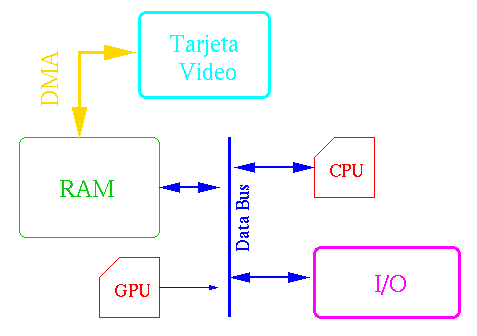
del bus de datos y que agreguemos otro periférico adicional que se encargue del
despliegue: una tarjeta de video con acceso directo a la memoria.
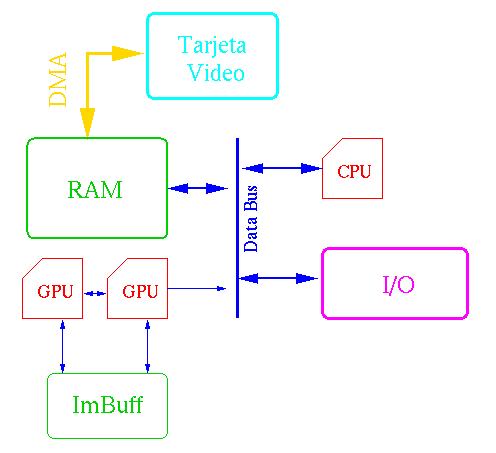
A continuación tenemos los diagramas con y sin DMA del módulo de I/O. Podemos
ver la versión con tarjeta de video y además un
pequeńo ejemplo de double buffering.
Diagrama sin el uso de DMA
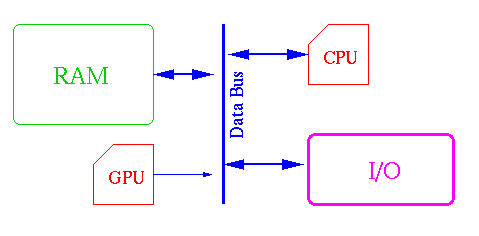
Diagrama con uso de DMA
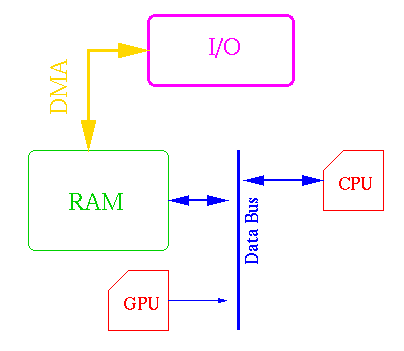
Diagrama con Tarjeta de Video
Doble Buffering
El Diagrama
Luego de ver como funciona cada parte, podemos hacernos una idea
de como se ve mas seriamente nuestra máquina de rendering. Notar las
distintas versiones, correspondientes a optimizaciones que,
aunque mejoran el performance, incrementan el costo y la complejidad.
Version standard
Version real-time
Comportamiento Esperado
Con la tecnologia actual no seria dificil construir esta máquina. De hecho
son pocas las cosas que tendríamos que "crear".
Las RPU's pueden ser procesadores multi propósito que se coordinan bien denstro de
las placas. La CPU también puede ser cualquiera en el mercado (no necesitamos
que sea poderosa). Incluso la GPU puede ser un chip multipropósito
suficientemente poderoso, utilizando el bus de direcciones para detectar los
cambios en el Image Buffer.
Prácticamente lo único que necesitamos es ensamblar todo y crear nuestra
memoria "matricial" para el image buffer, usando para la memoria central
cosas como SDRAM con una buena asministración.
PERO eso nos llevaría a un deterioro del performance, y si necesitamos
aplicaciones en real-time, tendremos que optar por componentes
especificos (ver optimizaciones).
Si utilizamos componentes suficientemente rápidos, mas una buena cantidad de memoria y
una tarjeta de video dedicada, podríamos llegar a cumplir el sueńo de obtener animaciones
generadas por Ray Tracing en tiempo real, es decir por lo menos 30 fps
(30 imagenes por segundo).
En caso que solo nos interese generar las animaciones para almacenarlas en disco
(como sucede con la mayoria del harware gráfico serio (silicon graphics, etc)), podemos
acelerar mucho el proceso con respecto a las máquinas existentes, y obviamente con una mejor
calidad. El poder probablemente pueda compensar el costo que significa una arquitectura
especializada.
Un punto importante en cuanto a desempeńo es el hecho de que nuestra máquina sea escalable:
esto nos permite tener máquinas con un decente precio de entrada, a la cual se le puede
aumentar el poder sin muchos preoblemas. En el siguiente punto veremos esto.
Algunas Optimizaciones
Inevitablemente en el momento en que se diseńó esta nueva arquitectura se tuvieron
en consideracion las posibles optimizaciones y se aplicaron de inmediato, ej: el doble
bus de las placas de RPU's, o sus cachés. Por lo tanto no queda mucho por decir.
Sin embargo hay algunos aspectos que tienen que ver mas con la implementación que con
el diseńo. Aquí nombraremos algunos:
- Tanto para el procesador central (CPU) como para todo el resto de los procesadores
(GPU, RPU's) el acceso a memoria es bastante directo, por lo tanto no necesitamos
todo el overhead que produce manejar direcciones virtuales. Este sistema no está
diseńado para correr múltiples procesos. Si queremos que esta optimización sea efectiva, nos
veremos obligados a nuestro procesadores sean creados especialmente para esta máquina
(mejor aun, pero mas caro).
- El hecho de que tengamos placas de RPU's nos permiten muchas optimizaciones. Algunas
de las no nombradas es que permite hacer crecer la máquina muy fácilmente. Si queremos
mas poder de Rendering, simplemente agregamos mas placas (como quien agrega RAM en un PC), y
la CPU se encarga de dividir el peso del cálculo.
- Otro punto con respecto a las placas es que el algoritmo que ejecutarán las RPU's se
encuentra en una pequeńa ROM. Por lo tanto, si posteriormente se logran hacer avances
significativos en el algoritmo de RayTracing, podemos conseguir placas con las nuevas versiones de
la ROM. Una alternativa mas complicada (en cuanto a diseńo) es que en lugar de tener una ROM por
cada placa, pongamos una RAM, y asi la CPU podría cargar el código del rendering en estas RAM's
y hacer todo el "upgrade" por software. Esto, aunque poderoso, es bastante "caro" puesto que
necesitamos un control mucho mas estricto sobre las placas. Quizá un bus especial. Puede
ser muy práctico, pero los avances parecieran no ser tan rápidos como para justificar el costo
extra.
- Mientras la RAM principal (memoria compartida) puede ser RAM tradicional (SDRAM, por ejemplo)
aunque muy bien administrada, la memoria para la Image Buffer debería ser especial, para
facilitarnos el hecho de detectar el cambio de pixeles. Ahora, si arreglamos esto un poquito podemos
deshacernos de este problema: Debido a que cada RPU sabe las coordenadas del pixel que está calculando,
cuando obtiene el color del pixel envía una estructura completa (con color y coordenadas), tal
que la GPU al detectar la llegada del nuevo paquete, averigue la coordenada y la existencia
de los piexeles de entorno. El mapa de los pixeles que han llegado lo puede hacer
el administrador del bus en algun area no usada del Image Buffer. Así podemos utilizar
cualquier tipo de memoria para el Image Buffer y, lo que es mas importante, hacerla crecer
si es que necesitamos mayores resoluciones o mas bits por pixel.
- La CPU tiene mucho tiempo libre, asi que podemos asignarle trabajo de la GPU en tareas sencillas.
La coordinación es fácil (es parte del mismo programa).
- El hecho de tener varias GPU's nos podria ayudar mucho en el caso de producirse
cuellos de botellas (aunque esto, en teoría, es poco probable). Si queremos agregar varias
GPU's tendremos que crear algun tipo de memoria para que se puedan coordinar, y que
debe ser de lectura y escritura para todoas las GPU's.
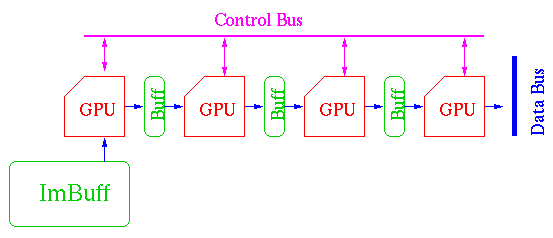
El costo de la coordinación haria que el desempeńo logrado no sea tan bueno como
esperamos. Ahora, siempre existe la alternativa de crear harware específico para
cada filtro, y que estos se monten en una línea de post-procesamiento (serialmente)
con memorias intermedias. Esta solucion es MUY cara, pero poderosa.
Siguiente: Posibles Usos