- Situación actual de la web
- Minería de texto: transformación de documentos a vectores
- Minería de datos: técnicas de clustering
Antecedentes
Situación actual de la web
El desarrollo de la sindicación de contenidos, tanto de blogs como de noticias online, motivado la necesidad de contar con herramientas que sean capaces de satisfacer necesidades derivadas de esta situación. Es así como han surgido una diversidad de servicios en la forma de portales web, que buscan satisfacer las necesidades de información y comunicación de la comunidad. Asi han surgido sitios que funcionan como buscadores de artículos de blogs: technorati.com, topix.net, blogalaxia.com, icerocket.com. O también, sitios que reunen contenido sindicado de diversas fuentes: digg.com, blogniscient.com, memeorandum.com, meneame.net. En este último caso, estos sitios combinan la sindicación, con la interacción con la comunidad de usuarios, por ejemplo, permitiendo a estos votar o rankear los distintos artículos publicados.
En el ámbito de sitios web (tradicionales), los desarrollos tecnológicos realizados a través de la minería web5.1, han estado centrados en el dominio de los buscadores, tales como Yahoo! o Google. El desarrollo de esta disciplina ha llevado a los resultados que se observan en el presente: page-rank5.2, clustering online de resultados de búsqueda, técnicas para eliminar el web-spam en los resultados arrojados, entre otros.
A pesar de todos estos avances, para el caso de artículos RSS, no existe un mayor desarrollo en esta área. Hasta ahora, la mayoría de los resultados obtenidos tienen relación con realizar búsquedas en el dominio de los blogs o de las noticias online, utilizando esquemas similares a los de páginas web tradicionales, por ejemplo, asignando un ranking a los diversos canales de origen. Otra aplicación en esta área, es la clasificación de artículos, permitiendo discriminar de cierta manera los contenidos disponibles. Por último, existen unos pocos casos de clustering y ranking de artículos, tales como blogniscient.com o newsmap.
El problema de rankear artículos tiene diversas formas de ser abordado. La solución más utilizada actualmente, es la de delegar en la comunidad este trabajo, a través de sistemas de votación. Es lo que hacan sitios como digg o meneame. Otro enfoque para este tema, es el utilizado por blogniscient. Aquí se utiliza el llamado ``Article Ranking System'', el cual es un desarrollo que busca rankear los artículos para mostrar los ``mejores resultados'' en cada categoría disponible.
Minería de texto: transformación de documentos a vectores
La minería de texto es el área de las ciencias aplicadas dedicada a la transformación de información textual (los documentos de entrada), en conocimiento. Este conocimiento puede ser el hallazgo de patrones en una colección, o la clasificación de documentos en categorías, por citar dos ejemplos.
La tarea fundamental de la minería de texto, para el caso en estudio, es el de la transformación de documentos en vectores. Para ello, se dispone del Modelo de Espacio Vectorial (VSM)[11]. Este modelo busca representar documentos en forma de vectores, transformando un documento de texto en un vector que refleje la frecuencia de las palabras que lo componen dentro de él. Dicha transformación dará lugar a un espacio vectorial, compuesto por los vectores representantes del conjunto de documentos de la colección en estudio, y cuyas dimensiones serán los términos encontrados en la colección. Para ello, cada documento se reduce de su forma original, a un vector de la forma:
donde
A su vez, el peso de un término dentro de un documento, puede ser calculado de varias maneras. El método más utilizado es el llamado tf-idf, que calcula la frecuencia del término dentro del documento versus la popularidad del término en toda la colección, teniendo:
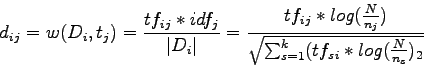
donde
Lo expuesto anteriormente, es la forma pura del modelo de espacio vectorial. Este método admite muchas variantes, fundamentalmente al momento de elegir el conjunto de términos a utilizar. Por ejemplo, es recomendable reducir el ``ruido'' eliminando las stopwords5.3, o borrando las eventuales etiquetas de marcado. Tambien se pueden eliminar abreviaturas, o no considerar faltas de ortografía, etc. De esta manera, se puede mejorar la representación vectorial de cada documento, y a la vez, reducir la dimensionalidad del espacio resultante. Una aplicación de estas ideas es el modelo TVSM (Topic-based Vector Space Model)[12] que propone utilizar tópicos en lugar de solo palabras. Este modelo se basa en las ideas anteriores, utilizando incluso steamming5.4 de palabras.
Minería de datos: técnicas de clustering
El clustering es la técnica que permite realizar la segmentación de un conjunto de datos, con el fin de encontrar patrones ocultos. El proceso que se realiza es el de clasificación, pero de manera no-supervisada. Esto significa que un algoritmo de clustering será capaz de descrubrir las clases ocultas en el conjunto de datos, y a su vez, catalogar cada instancia en alguno de estos grupos, formando agrupaciones según patrones comunes.Existen muchos algoritmos de clustering, que permiten realizar la tarea de diversas maneras. Estos algoritmos se podrían dividir en dos clases:
- Algoritmos de particionamiento.
- Algoritmos jerárquicos.
Algoritmos de particionamiento:
Realizan la tarea de dividir el conjunto de datos en clases, asignando una pertenencia (o probabilidad de pertenencia) a cada uno de los elementos del espacio. Esta asignación se irá perfeccionando a medida que itera el algoritmo. Ejemplos de este caso son los algoritmos de k-means, isodata, k-medianas, E-M, SOM, entre otros.A modo de ejemplo, el algoritmo de k-means supone una cantidad dada de clusters, y buscará localizar las k-medias de los clusters en el ``centro de masa'' de cada grupo. En el primer paso, se asignan en forma aleatoria las posiciones de las k-medias, y cada una de las instancias será asignada a alguna de las medias recién ubicadas, midiendo la cercanía de los vectores a cada media. En el siguiente paso, nuevamente se reubicarán las k-medias, esta vez buscando acercarse al centro de cada uno de sus grupos recién definidos, y luego de eso, se volverá a asignar cada vector del conjunto a la media más cercana en el espacio. El algoritmo se detendrá en el momento en que se haya alcanzado suficiente estabilidad en la posición de las medias de los clusters.
Algoritmos jerárquicos:
Se pueden clasificar en dos tipos: aglomerativos o divisivos. Los algoritmos aglomerativos, comienzan con tantos clusters como instancias tenga el conjunto de datos. En cada paso, se van agrupando clusters, a partir de los clusters y las instancias formadas hasta el momento. Por su parte, los algoritmos divisivos realizan el proceso inverso: comienzan con un único cluster que abarca todo el conjunto, y en cada iteración se van separando. El algoritmo se detendrá según algún criterio de parada (por ejemplo, el número o calidad de los clusters). Ejemplos de este caso son los algoritmos de HAC, COBWEB, entre otros.El caso del algoritmo HAC (Hierarchical Agglomerative Clustering), corresponde a la representación de los datos mediante un árbol o dendrograma, el cual se irá formando a medida que avanza el algoritmo. Para un conjunto de n instancias, se tendrá n clusters, cada uno asociado a un elemento. A continuación, se elegirá unir los dos clusters más cercanos, según alguna regla de distancia inter-clusters. Ejemplos de esta regla puede ser la distancia entre las medias de los clusters, o bien, la distancia entre los bordes de cada cluster (es decir, entre los elementos más externos de cada grupo). De esta manera, el par de clusters elegidos se unirá para formar uno solo en el nivel superior del árbol. Finalmente, el algoritmo se detendrá cuando se satisfaga algún criterio de detención.
La operación de clustering se basa en la noción de distancia o similaridad5.5 entre vectores. Por lo tanto, una vez elegido el algoritmo, se deberá decidir acerca de la noción de distancia a utilizar. Para la distancia entre documentos, la principal medida de distancia corresponde a la llamada distancia coseno, la cual mide el coseno del ángulo formado entre los vectores. De esta manera:
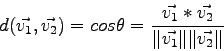
medirá la similaridad entre ![]() y
y ![]() .
.
Con respecto al clustering de artículos, el problema a abordar plantea la necesidad de encontrar un algoritmo que cumpla con los requerimientos del sistema, esto es, que permita realizar el clustering incremental necesario para agrupar los artículos que constatemente alimentarán al sistema. Esto, junto con definir una noción de distancia que permita tomar en cuenta tanto la similaridad de documentos, junto a los demás atributos (principalmente, la temporalidad).
 dcc.uchile.cl
dcc.uchile.cl