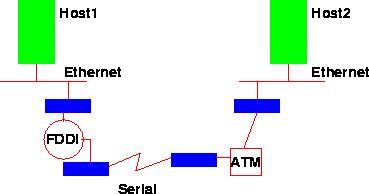
El nivel red tiene como misiones el ruteo, el manejo de congestión y de errores. Ahora el problema radica en poder conectar una máquina con otra pasando por múltiples redes y enlaces (ver Figura 4.1), incluso cambiando la representación física de los paquetes y el encapsulamiento de una red a otra.
En este capítulo nos centraremos fuertemente en IP (Internet Protocol), que es el protocolo del nivel red de TCP/IP. Los detalles corresponden a IPv4 (que es la versión actual del protocolo) pero en algunos casos mencionaremos las características relevantes de IPv6 que es la nueva versión. Los principios de ambos protocolos son idénticos, y la nueva versión sólo incluye mejoras de performance y escalabilidad en la implementación.
IP tiene dos principios básicos:
IP se basa en el concepto de una inter-red, que es una red de redes. Es decir, no conecto un computador con otro, sino una red con otras. Esto me permite factorizar una buena cantidad de información, puesto que solo debo identificar la red destino para rutear.
El modelo de la inter-red, lo podemos ver en la Figura 4.2
Figure 4.2: Modelo de una Inter-red
El Router (que es un computador que conecta dos redes entre sí) se encarga del cambio de formato físico y del ruteo entre ambas redes. Para lograr hacer esto requerimos las siguientes características para IP:
Para el nivel red, se define un espacio de direcciones de 32 bits, que serán usados en forma única para identificar cada computador conectado a la Inter-red (hoy (Marzo 1996) hay unos seis millones en Internet, pero este número se multiplica por dos cada ańo).
Para permitir ruteo fácil en base a la dirección IP, se dividen los bits en una dirección de red (bits superiores) y una dirección de host (bits inferiores).
La notación de las direcciones IP es en base a cuatro decimales separados por un punto (cada decimal codifica un byte: 0 - 255). Por ejemplo: 146.83.4.11
Inicialmente, las direcciones se separaron en clases A, B y C según
sus bits iniciales.![]() La idea era que la separación entre bits de red y bits de
host es en un byte distinto para cada clase (ver Figura 4.3).
La idea era que la separación entre bits de red y bits de
host es en un byte distinto para cada clase (ver Figura 4.3).
Al rutear, se debe separar el prefijo de red del sufijo de host. Luego, se rutea en base al prefijo. Sólo cuando ya estoy en la red correcta, utilizo el sufijo de host para encontrar la máquina destino en la red local. El número de bits del sufijo determina cuantos hosts puedo tener en la misma red: 256 para una clase C, 65.536 para una clase B y 16.777.216 para una clase A.
Los prefijos de red deben ser por lo tanto únicos en todo el mundo, por lo cual son asignados centralizadamente.
El ligar el ruteo a la dirección de la máquina implica que una máquina conectada a varias redes posee varias direcciones IP (una en cada red), lo que puede hacer que en un momento sea accesible por una dirección y no por otra.
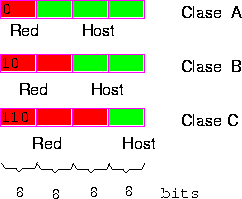
Figure 4.3: Clases de direcciones IP
Como obviamente 256 computadores es poco para la mayoría de las organizaciones, casi todas pedían una red clase B. Por otro lado 65.536 computadores es mucho para una sola red. Para dividir una red corporativa en múltiples redes internas, se usa el concepto de una sub-red, que considera los primeros bits de la parte host, como una extensión de la parte red, y los últimos como el verdadero host. O sea, en vez de dividir la dirección en red, host; la dividimos en red, sub-red, host. El número de bits en la sub-red es variable, y se define con una máscara de red, que es un conjunto de bits. Los bits en 1 definen el prefijo de red (red + sub-red) y los bits en 0 corresponden a la parte host. Por ejemplo, la clase B 146.83.0.0 la dividimos en redes con un máximo de 128 hosts cada una. Para esto el primer byte completo y un bit más son necesarios para el prefijo de red. La máscara es entonces: 255.255.255.128.
Esto me permite manejar la red como una sola entrada en las tablas de rutas de Internet, pero internamente sé que son múltiples redes interconectadas. La máscara de sub-red no requiere ser conocida fuera de la red local, puesto que hacia afuera somos una sola red (ver Figura 4.4).
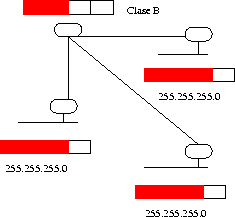
Figure 4.4: Ejemplo de sub-redes
Para separar la parte red y la parte host, entonces, primero uso el prefijo de la clase. Si corresponde a mi red, uso la máscara para terminar de extraer el prefijo de red.
En el ańo 1992 se generó un importante proyecto de cambios en el manejo y asignación de direcciones IP en Internet. Básicamente, existían tres riesgos de muerte del Internet a mediano plazo:
A esa altura casi la mitad de las direcciones clase B estaban asignadas. Al ritmo de crecimiento de ese momento, iban a terminarse en un par de ańos. Básicamente, toda organización normal, requería de una clase B, puesto que una clase C era insuficiente.
Claramente 32 bits no son suficientes para el crecimiento de Internet, y la tasa de pérdida que es parte de cualquier sistema de asignación que se utilice, dado que son prefijos de red, y las redes no están nunca totalmente utilizadas.
Los routers centrales de Internet deben mantener una tabla con una entrada para cada red conectada a Internet en el mundo entero. Actualmente, hay unas 60.000 redes, y cada vez resulta más difícil manejar ese tamańo, tanto en memoria como en ancho de banda para los protocolos de actualización.
Para resolver los problemas 1 y 3 se decidió desplegar un nuevo esquema de asignación y de manejo de las direcciones IP, de modo de disminuir el problema y darle tiempo al desarrollo de la nueva versión de IP (IP versión 6) que resolvería el punto 2.
Básicamente, una red clase A, B o C puede verse como una red con una máscara implícita. En el nuevo esquema, conocido como CIDR (Class-less IP), todas las redes se manejan con una máscara explícita para poder dividirlas en red/host y nos olvidamos de las clases. Por ello, podemos agrupar varias clases C contiguas, con una máscara común, extendiendo los bits de host hacia los de red, implementando lo que se conoce como super-redes. Por ejemplo, las clases C 200.0.0.0 y 200.0.1.0 pueden agruparse en una super-red 200.0.0.0 con máscara 255.255.254.0. Actualmente, las máscaras ya no se anotan así, y se prefiere escribir el número de bits de la parte red. En el ejemplo anterior, se habla de la red 200.0.0.0/23.
La existencia de super-redes ha permitido asignar el número de redes adecuado a cada institución sin sobrevender demasiado, disminuyendo el problema 1. Sin embargo, si las super-redes no son entendidas por los routers de Internet, exacerban el problema 3. Por ello, los nuevos protocolos de ruteo ya manejan este concepto, difundiendo redes agregadas, con un prefijo y una máscara. Esto me permite factorizar varias redes clases C agrupadas en una super-red, como una sola entrada en mi tabla de rutas.
Para poder manejar super-redes, sin embargo, se requiere un cambio mayor en la representación de las tablas de ruteo (el algoritmo de ruteo de IP se explica en la sección 4.4), porque (al contrario que en el caso de las sub-redes) ahora requiero conocer la máscara de red en todas partes, incluso fuera de la red misma. En IP sin clases (CIDR) se supone que toda máquina y Router manejan tablas con el prefijo de red y la máscara asociada, de modo de poder separar la parte red y la parte host de una dirección cualquiera. Un punto importante es que aunque mi Router no hable CIDR y utilice el sistema antiguo igual funcione. Esto se logra haciendo que ese Router maneje una entrada para cada clase C de la super-red en cuestión, sin factorización. Obviamente, perdemos la ventaja de CIDR, pero al menos funciona.
Los datos se empaquetan en un datagrama, que es la unidad utilizada para atravesar las redes en camino. La idea básica de un datagrama es equivalente a una carta envuelta en un sobre. Los datos del sobre van en el header del paquete y el contenido va como datos. Al igual que en la carta, la idea es que al irse ruteando por la red el datagrama queda intacto, sin modificarse ni el header ni el contenido.
Cada datagrama es independiente, por lo cual pueden rutearse por caminos distintos. Por otro lado, IP provee un servicio del mejor esfuerzo, es decir no garantiza la entrega. Los paquetes pueden llegar a su destino desordenados, duplicados, alterados o incluso perderse.
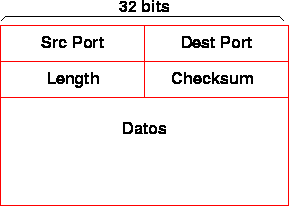
El encabezamiento contiene las direcciones IP del origen y del destino, así como el largo y un checksum del header. Los datos no se validan, por lo que el nivel trasporte tendrá que encargarse de ellos. El encabezamiento puede verse en la figura 4.5.

Figure 4.5: Header del paquete IP
Todos los campos del encabezamiento se representan en forma estándar, conocida como network order. En alguna máquinas, deberemos traducir los enteros para llevarlos la representación correcta para esa arquitectura.
El header puede contener opciones que lo hagan más largo, por ello lleva un campo con el largo del header. El campo Protocol indica el tipo del protocolo de transporte (UDP, TCP, ICMP) al que pertenece este paquete. El campo tipo de servicio nunca se ha implementado realmente, pero la idea era diferenciar ruteo según requisitos de ancho de banda y/o delay.
El campo TTL sirve para limitar el tiempo que un paquete vive en la red (en particular en caso de ciclos en las rutas). Cada vez que un paquete pasa por un router debe decrementarse. Si llega a cero, el datagrama debe ser descartado.
Teóricamente, un router no debe cambiar nada en el encabezamiento, de modo de mantener el sobre y el contenido intactos hasta el destino final. El TTL es la excepción a la regla, y esto complica todo, puesto que el checksum del header debe recalcularse y cambiarse en cada router. Esto hace casi imposible hacer un ruteo eficiente de paquetes IP. En IPv6 se ha rediseńado completamente el header de modo de hacerlo de tamańo fijo, sin checksum y las opciones típicamente sólo son analizadas en el destino final.
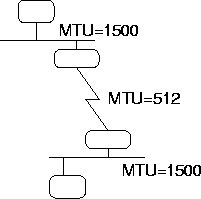
Figure 4.6: Necesidad de Fragmentar
El último problema que queda es determinar el tamańo del datagrama.
Obviamente quiero que sea lo más grande posible, pero debe caber en un
frame físico. Por otro lado, las redes por las que transitará pueden tener
tamańos de frames (MTU: Maximum Transfer Unit) distintos (ver 4.6).
Si un paquete
llega a un router y es muy grande para seguir su camino debo
fragmentarlo en unidades más pequeńas.![]()
Al fragmentar divido el datagrama en varios datagramas con (casi) el mismo header y los trozos de los datos en cada uno. El largo de cada datagrama es el que corresponde a cada fragmento. Cada uno de estos fragmentos será ruteado luego como un datagrama independiente.
El problema es que si el nivel transporte envía un datagrama, el receptor debe recibir también uno (y no varios más pequeńos). Para esto, el receptor final ``pega" los fragmentos para reconstruir el datagrama original. En esto se usan los otros campos del encabezado (ver Figura 4.5): el identificador es un valor único por cada datagrama enviado desde un mismo host. Los fragmentos llevan todos el identificador del datagrama original, permitiendo reconocerlos. El offset del fragmento indica la posición dentro del datagrama original donde van los datos de este fragmento. (Para ahorrarse espacio en el header, el offset va anotado contando de a 8 bytes, por lo que debe multiplicarse por ocho para obtener el verdadero valor.)
Finalmente, en el campo Flags se anota que son fragmentos y no un datagrama completo. Otro bit existe ( No more fragments) para el último fragmento, de modo de saber cuándo terminar (ver 4.7).
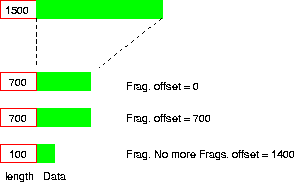
Figure 4.7: Fragmentos de un Datagrama
Al recibir el primer fragmento de un datagrama, se activa un timer de modo que al transcurrir demasiado tiempo esperando armarlo lo descarto generando un error. Esto descarta el datagrama completo, aunque se hayan recibido varios fragmentos en el intertanto. Típicamente la implementación consiste en una lista enlazada de fragmentos para cada datagrama (identificado por su campo identificador), donde se van agregando los fragmentos a medida que llegan. Esto se hace así puesto que desconocemos el largo total del datagrama, hasta que no recibimos el último fragmento.
Al detectarse un error relacionado con un datagrama, se envía un mensaje de error a la dirección IP de origen. Este mensaje va en un datagrama dirigido al layer IP propiamente tal, no a una aplicación de nivel superior. Por ello, se encapsula en un datagrama IP con valor protocolo (en el header) de ICMP. El datagrama original (que causó el error) va como dato.
Típicos paquetes de error son porque el TTL llegó a cero, porque no existen rutas a esa red, tiempo esperando fragmentos excedido, etc.
Cada router y cada host mantiene una tabla de rutas, puesto que incluso un host conectado a una sola red debe saber cómo llegar a los distintos destinos. Todo el ruteo de un datagrama se hace paso a paso ( hop-by-hop), decidiendo cada vez a qué router de la red local debo entregárselo para acercarme al destino final. El ruteo se hace igual para los datagramas generados internamente por una aplicación como para uno recibido desde la red.
Un router está conectado directamente a una o más redes, cuyos prefijos de red conocemos. En esas redes pueden haber otros routers que nos permiten ir más lejos.
El algoritmo de ruteo que toda implementación de IP debe realizar, se basa en una tabla de rutas. Esa tabla consiste de una entrada para una red y el router que debo usar para ir hacia ella. El router va representado por una dirección IP de una red a la cual yo estoy directamente conectado. En esa tabla también figuran todas las redes a las que estoy conectado las que se marcan con un tipo especial ( DIR).
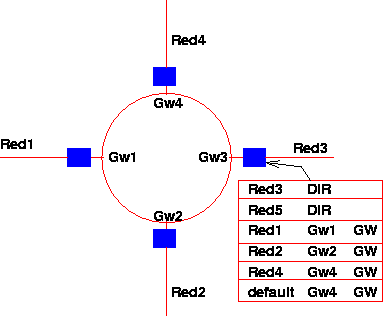
En la figura 4.4.1 pueden ver un host conectado a una red con más de un router y su tabla de rutas.
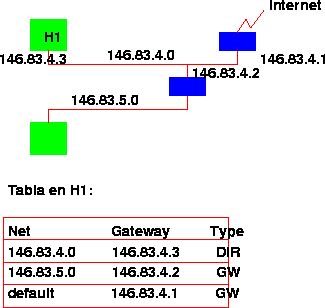
Figure 4.8: Ejemplo de Tabla de Rutas
Para evitar el tener la tabla de todas las redes de Internet en todas las máquinas conectadas, se usa una ruta default que nos indica nuestro router usual para todas las redes que no conozco. Esta ruta se representa con la red 0.0.0.0 y se usa en todos los routers para mostrar la ruta hacia el resto de Internet. Obviamente, se requiere que algunos Routers de la red (los principales) no tengan ruta default, y efectivamente manejen la tabla completa de las redes conectadas (se llaman Routers default-less). Desde cualquier punto de Internet, la cadena de rutas default deben llevarnos a un Router default-less para que el algoritmo funcione.
El algoritmo básico de ruteo IP es:
RouteIP(dgram, table)
{
IPnet = getnet(dgram.destIP);
Route = search(IPnet, table);
if( Route.type == DIR )
sendphys(dgram, dgram.destIP);
else if (Route != NOT_FOUND)
sendphys(dgram, Route.gateway);
else
{
Route = search(default, table);
if( Route != NOT_FOUND )
sendphys(dgram, Route.gateway);
else
error(dgram, "Net Unreachable");
}
}
El algoritmo anterior depende de la correctitud de las tablas de rutas utilizadas. Como estas tablas pueden contener errores, se incluyen algunos mecanismos básicos en IP para evitar dańos demasiado graves.
Por ello, los datagramas incluyen el campo TTL, de modo de impedir que un ciclo en las rutas no genere datagramas permanentemente girando en la red, consumiendo ancho de banda sin llegar a ningún lado. Al llegar este contador a cero, el datagrama debe destruirse y no seguir ruteándolo. Sin embargo, es bueno generar un mensaje de error para el origen, de modo de advertirle que sus datagramas se están perdiendo. Esto va en un datagrama ICMP (Time Exceeded) al origen.
Sin embargo, es probable que (si hay un ciclo en una dirección) haya un ciclo también en la dirección del origen. Si esto ocurre, el datagrama ICMP también verá su TTL llegar a cero, y deberá ser destruido. Obviamente, si genero otro ICMP en este caso, ocurrirá lo mismo. Por ello, se define en IP que nunca se genera un mensaje ICMP para reportar errores producidos por paquetes ICMP de reportes de errores.
En el caso de recibir un paquete que debe rutearse por la misma interfaz de red por la que llegó, un Router rutea bien el paquete, pero también genera un ICMP redirect hacia el host de origen, si el origen está en la misma red.
La última etapa consiste en entregar el datagrama a su máquina destino correcta, una vez que ya llegó a la red de destino. Esto no es trivial, puesto que solo conozco su dirección IP, y lo que requiero ahora es su dirección física. Por supuesto, este problema también se aplica al tener que enviar paquetes a routers en mi propia red, para que ellos continúen el ruteo. En definitiva, nuestro problema general es enviar un datagrama cualquiera a una máquina de mi red, conociendo sólo su dirección IP.
Obviamente, conozco la interfaz de red por donde debo enviar el datagrama y también conozco la forma de encapsular el datagrama en un frame físico de este tipo de red. Pero aún así, debo encontrar la dirección física del destinatario (dirección ethernet, NSAP ATM, número de Token Ring, etc). Esto es un protocolo de traducción de direcciones, que depende de la red física en cuestión. El protocolo más usado es ARP ( Address Resolution Protocol) en medios que soportan broadcast. La idea es muy simple, hago un broadcast de un paquete con protocolo ARP (esto no es un datagrama IP), que contiene mis datos (dirección IP y física) y la dirección IP que quiero resolver. Este paquete es recibido por todas las máquinas de la red, quienes verifican si tienen esa dirección IP registrada como propia o no. Sólo quien tenga esa dirección como propia debe responder, completando la información del paquete ARP y enviándolo directamente al origen.
Al recibir la respuesta, el origen agrega a una tabla local (en memoria) el par dirección IP, dirección física. Este cache de ARP sirve para no preguntar por cada paquete en caso de tráfico continuo. Sin embargo, los valores deben ir expirando en el tiempo para permitir cambios de asociaciones dinámicos.
En el caso de redes que no soportan broadcast, debemos tener tablas locales (mantenidas por personas) o un servidor ARP central a quien enviarle las preguntas (como un directorio). En este último caso, requiero que configuren a mano la dirección física de dicho servidor solamente.
ARP es uno de los problemas de IP en redes grandes, puesto que genera broadcasts que ningún filtro de nivel físico puede parar. Tormentas de broadcasts son frecuentes en redes con más de 100 máquinas.
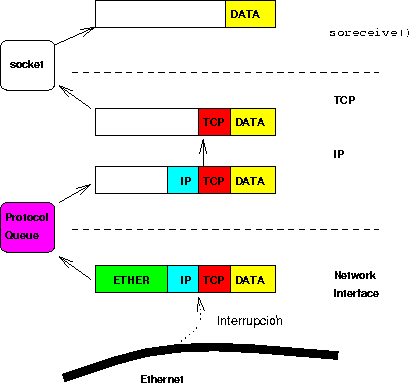
Figure 4.9: Layers y empaquetamiento
Existen algunas redes físicas que trivializan esta operación, por ejemplo en Token Ring las estaciones están numeradas en el orden del anillo, y puedo usar el último byte de la dirección IP para almacenar el número de la estación. En este caso, puedo traducir directamente, sin ningún protocolo de red. En el caso de IPv6, cuyas direcciones IP son de 128 bits, puedo usar los últimos 48 bits para poner la dirección ethernet y no requiero ARP.
Al encapsular un paquete IP en un paquete físico, termina el proceso de empaquetamiento y finalmente es emitido el datagrama a la red (ver Figura 4.9). Si el datagrama va dirigido a un host de esta red local, la dirección IP y la dirección física serán de la misma máquina. Sin embargo, si el datagrama va dirigido a un host de otra red, la dirección física corresponderá a la del router de esta red y no estará relacionada con el destino.
Hasta aquí hemos supuesto que las tablas de rutas existen, pero obviamente alguien tiene que configurarlas. En los hosts finales, típicamente es el administrador de sistemas quien configura la dirección IP de la máquina, la red local y el default gateway. Estas entradas se consideran rutas "estáticas".
Sin embargo, mantener una red de campus, donde varias redes locales se interconectan, requiere de múltiples tablas para mantener actualizadas. Al agregar o cambiar una red, debo hacer un cambio en cada router que me conecta con las redes locales (ver figura 4.4.4).
Claramente, esto se vuelve inmanejable muy rápido. Por ello, se requiere de protocolos automáticos que difundan las tablas y permitan mantener esta información en los routers. Por otro lado, queremos aprovechar la existencia de múltiples caminos posibles, para hacer un ruteo más tolerante a fallas, que pueda encontrar rutas alternativas en casos de caidas.
Como el ruteo en todo Internet es algo complejo, se decidió tener dos familias de protocolos distintos: Ruteo Interno y Ruteo Externo. El Ruteo Interno se encarga de mantener tablas de rutas correctas en redes de tamańo mediano (país, institución, etc), que son controladas por una administración común. El Ruteo Externo se encarga de rutear en Internet global, que es una enorme colección de redes internas.
Veremos en este capítulo los protocolos internos habituales.
El protocolo más simple y antiguo es RIP, que viene provisto por el demonio routed en Unix, y fue introducido en Berkeley para mantener tablas correctas en sus redes locales. Nunca fue concebido como un protocolo escalable de ruteo, a pesar que hoy se usa bastante en redes grandes.
La idea es mantener en la tabla de rutas (junto con la red y el gateway) una métrica que cuente la distancia a la que me encuentro de esa red. De esta forma, al recibir otras posibles rutas a la misma red, puedo elegir la más corta.
RIP es un protocolo de vectores de distancias, donde cada router puede verse como un nodo en un grafo, y las distancias son el número de nodos por los que debo pasar para llegar a mi destino. Cada router maneja su tabla de rutas, donde figuran todos los nodos del grafo y la distancia asociada (así como el gateway). Cada cierto tiempo, los routers envían esa tabla a todos sus vecinos. Al recibir la tabla de otro router, aprendo los caminos a redes que yo no conocía (y los agrego a mi tabla) y encuentro nuevos caminos a redes que ya conocía. Para elegir una ruta, comparo las métricas (al recibir una tabla, le sumo 1 a todas sus métricas, puesto que las redes están a un router más de distancia) y me quedo con la más pequeńa. En caso de igualdad, me quedo con la ruta antigua, para evitar cambios permanentes en las rutas.
Además de las rutas aprendidas por RIP, típicamente manejamos una ruta default igual como antes, y las rutas directas a las redes a las que estoy conectado (cuyas métricas son cero).
Para encontrar a los routers y poder intercambiar con ellos las tablas, RIP utiliza un esquema de broadcast. Un router que habla RIP, difunde vía broadcast a todas las redes a las que está conectado su tabla de rutas periódicamente. Al recibir un broadcast RIP, el router compara sus entradas con las recibidas y actualiza la tabla.
Sin embargo, para poder adaptarse a fallas o caídas de routers, hay que poder borrar rutas también. Como no puedo confiar que el router caído me avise, se define un intevalo de tiempo fijo en RIP entre broadcasts (30 segundos). Al transcurrir varios intervalos sin escuchar nada de un router (180 segundos) todas las rutas que fueron recibidas desde él se invalidan.
RIP tiene varias ventajas, probablemente la principal es que funciona solo, prácticamente sin configuración o ingeniería inicial. Basta habilitar RIP en el router, y aprende y difunde todas las rutas automáticamente. Esta misma sencillez es su principal defecto, puesto que satura la red con broadcasts innecesarios, utiliza métricas que no toman en cuenta capacidades de las distintas redes, etc.
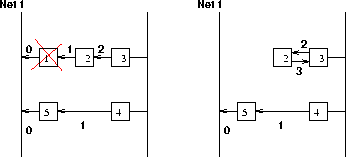
El principal problema de RIP es un defecto fundamental de cualquier protocolo de vector de distancias: al manejar sólo distancias, no puedo detectar los ciclos en las rutas. Al cambiar las rutas, es fácil caer en ciclos infinitos. Por ejemplo, en la Figura 4.11, podemos ver al router 1 que muere. El router 2 detecta esta muerte y elimina su ruta a la red Net1. En ese momento, recibe un broadcast del router 3, donde figura Net1 a distancia 2, por lo que agrega esa ruta (con distancia 3) apuntando al router 3. Obviamente, esto es un error, puesto que el router 3 debió haber cambiado la ruta a Net1 apuntando hacia el router 4. Este ciclo se mantendrá, pero la distancia se irá siempre incrementando.
Para evitar este efecto, en RIP se define que una métrica 16 es equivalente a infinito. Además, se implementan otras soluciones (como split horizon que no difunde por una interfaz las rutas aprendidas por esa misma). Sin embargo, estas soluciones siempre tienen efectos laterales negativos.
La familia contraria a los vectores de distancia busca optimizar las rutas en base a una visión completa de la red interna. Cada router maneja una visión del estado actual de la red y las conexiones, y calcula en base a ella las rutas óptimas para llegar a todas las redes que la conforman.
La idea es que todos los routers manejan información completa y consistente de la red completa (son algoritmos para redes internas, por lo que se supone que no son demasiado grandes). Para adaptarse a los cambios, cada router mantiene el estado de sus enlaces y de sus routers vecinos. Cuando uno ya no le responde, o un enlace se cae, simplemente marca ese enlace caido en su estado. Cada cierto tiempo, el router envía el estado de todos sus enlaces locales a todos sus vecinos quienes a su vez lo propagan a todos sus vecinos (es un algoritmo de inundación). Estos mensajes son cortos, y el período entre un envío y el siguiente puede ser muy largo, puesto que lo cambios de estado fuerzan una transmisión también.
Al recibir un mensaje de estado de un router, todos los routers actualizan su estado y si hubo un cambio, recalculan las rutas a todos los destinos desde donde están ellos, aplicando el algoritmo de Dijkstra Shortest Path First. Como cada router sólo envía sus enlaces, los mensajes no crecen en tamańo a medida que la red crece. Claro que la memoria requerida para los routers y el tiempo de procesador requerido para recalcular rutas es mucho mayor que para RIP.
Las ventajas principales de OSPF es que es un algoritmo que converge muy rápido frente a cambios en la red, está libre de ciclos y soporta varias extensiones como autentificación, balanceo de carga y redes virtuales (simulando enlaces que pasan a través de varias redes IP).
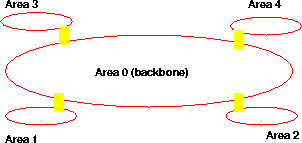
Una desventaja importante es el consumo de CPU, y es conocido que un enlace que sube y baja muy seguido causa grandes trastornos en el funcionamiento. Para aliviar un poco este defecto, OSPF soporta el concepto de áreas, que permite subdividir la red completa en varias áreas OSPF, dentro de las cuales se aplica el algoritmo OSPF completo. Cada una de estas áreas está conectada con un backbone (área 0) que es una red de interconexión. Esto permite que cada área sólo mantiene su propio estado, y los mensajes inundan sólo un área (ver Figura 4.12). La recomendación en OSPF es que un área no debe contener más de 200 routers.
El problema del ruteo global en Internet es un área de investigación aún hoy y es sumamente compleja, por lo que no vale la pena estudiarla en detalle acá. Sin embargo, el concepto utilizado para rutear en una red de este tamańo sigue basado en el algoritmo básico de ruteo hop-by-hop de paquetes IP. Existen varios routers en los principales puntos de interconexión, que no tienen rutas default y que manejan la tabla completa de todas las redes conectadas a Internet (que gracias a CIDR no son tantas como deberían).
Estas tablas son actualizadas para reflejar cualquier cambio en la accesibilidad de ellas, y por supuesto estos cambios son bastante frecuentes a nivel mundial. Todos los algoritmos anteriores (de ruteo interno) son imposibles de escalar a este nivel, básicamente por el nivel de detalle que manejan.
Para aliviar este problema, Internet ahora se maneja como un conjunto de Sistemas Autónomos (AS) en vez de un conjunto de redes IP. Un sistema autónomo es un conjunto grande de redes IP (típicamente todos los clientes de un proveedor) con un número único asignado por la IANA (Internet Assigned Numbers Authority) también responsable de la asignación de las direcciones IP.
El protocolo más usado hoy en día para el ruteo global es BGP-4, que soporta CIDR y sistemas autónomos. BGP-4 es un protocolo de vector de caminos, un derivado de vectores de distancias. Básicamente los routers ahora comunican por TCP (en vez de usar broadcasting) y se intercambian tablas de rutas con las distancias pero cada entrada viene con el camino que ha recorrido para llegar hasta este router. El camino es una lista de AS's, y si incluye mi AS, debo ignorar esa entrada (para evitar ciclos). Todas las entradas en mi tabla van acompańadas de su camino.
En general, se recomienda manejar por separado el ruteo interno del externo, y los routers que están en los bordes deben manejar dos tablas separadas: una para la lista de redes que deben anunciar por BGP y otra para las redes aprendidas por ruteo interno. Esto permite separar políticamente el ruteo, y evitar actuar como red de tránsito cuando no lo deseo.
El ruteo en Internet está en pleno desarrollo, y en IPv6 se espera rutear con otro protocolo (Domain Routing Protocol), manteniendo la idea de CIDR.
Existen dos transportes posibles en TCP/IP: UDP y TCP. Existen algunos otros no muy utilizados, pero siempre se pueden agregar más.
UDP ( User Datagram Protocol) permite básicamente darle acceso directo a los datagramas IP a las aplicaciones de usuario.
El datagrama IP va de un computador a otro. Ahora quiero que vayan de un programa a otro (si el computador es multi-proceso, debo diferenciar los destinos/orígenes dentro de un mismo computador). Para esto, se usa un número de port. El paquete UDP es entonces un datagrama IP con un encabezamiento agregado que comprende básicamente un port de origen y un port de destino. Además se incluye un checksum que incluye los datos (puesto que en IP solo verificamos el encabezado). En IPv6 UDP se conserva igual, y solo se modifica IP, pero se vuelve obligatorio siempre implementar el checksum (antes era opcional) incluyendo encabezado y datos. Como en IPv6 no hay checksum en IP, es obvio que no podemos dejar el encabezado desprotegido. Este checksum también incluye las direcciones IP.
Tal como en el nivel red se revisa la dirección IP de destino, en el nivel UDP se revisa el port de destino para decidir a qué proceso corresponde el datagrama (ver Figura 4.14).
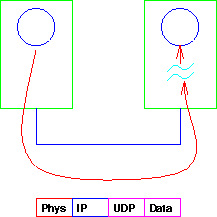
Figure 4.14: Paquete UDP dirigido a un port
Los ports son enteros de 16 bits, y los menores de 1024 se consideran oficiales, y los superiores son utilizados más libremente. TCP (el otro protocolo de transporte) también utiliza ports, pero el espacio es disjunto. Es decir un port 25 en TCP no tiene relación con el port 25 en UDP (aunque por razones de administración se trata de no asignar ports iguales a distintos servicios en ambos protocolos).
Un ejemplo de los ports UDP más conocidos (del archivo /etc/services):
echo 7/udp discard 9/udp sink null daytime 13/udp chargen 19/udp ttytst source time 37/udp timserver rlp 39/udp resource # resource location name 42/udp nameserver domain 53/udp bootps 67/udp # bootp server bootpc 68/udp # bootp client tftp 69/udp sunrpc 111/udp portmapper # RPC 4.0 portmapper TCP ntp 123/udp # Network Time Protocol netbios-ns 137/udp nbns netbios-dgm 138/udp nbdgm snmp 161/udp snmp-trap 162/udp biff 512/udp comsat who 513/udp whod # BSD rwhod(8) syslog 514/udp # BSD syslogd(8) talk 517/udp # BSD talkd(8) ntalk 518/udp # SunOS talkd(8) route 520/udp router routed # 521/udp too timed 525/udp timeserver netwall 533/udp # -for emergency broadcasts new-rwho 550/udp new-who # experimental rmonitor 560/udp rmonitord # experimental monitor 561/udp # experimental mount 635/udp # NFS Mount Service pcnfs 640/udp # PC-NFS DOS Authentication bwnfs 650/udp # BW-NFS DOS Authentication nfs 2049/udp # NFS File Service
Uno se podría preguntar żpara qué sirve un sistema de tranporte de datagramas? Efectivamente, los datos se pueden desordenar o perder (la alteración se impide vía el checksum). Sin embargo, ofrece una ventaja importante: eficiencia.
Hay dos tipos de aplicaciones típicas de UDP: cuando la eficiencia y bajo consumo de recursos es crucial (por ejemplo: NFS) o cuando requiero soportar múltiples destinatarios: broadcast o multicast.
El método de transporte más popular en Internet es TCP (Transmission Control Protocol), ya que provee una conexión punto a punto confiable y ordenada, tipo secuencia de bytes (equivalente a un pipe de Unix bi-direccional).
Por ello, TCP requiere una operación de connect que establece la conexión entre dos procesos. Una vez realizada la conexión, puedo leer y escribir en un descriptor tal como si fuese un pipe Unix.
Al igual que en UDP, el port me indica el servicio (o el proceso) con el que quiero conectarme. Una vez establecida la conexión, se utiliza la tupla [IP orig, port orig, IP dest, port dest] para identificar la conexión. Eso me permite tener múltiples conexiones a un mismo port (por ejemplo mail) sin confundirlas.
Manteniendo la separación entre layers, TCP maneja las conexiones sin que IP sepa nada al respecto. Por ello, cuando la conexión está establecida, eso quiere decir que los dos extremos tienen recursos reservados para ella, pero entre ambos los routers no conocen su existencia. Por lo tanto, toda la inteligencia de retransmisión, descarte de duplicados, etc, debe proveerla TCP mismo. Los routers no participan, sólo los computadores origen y destino.
TCP es un protocolo de ventanas, orientado a los bytes, no a los paquetes o mensajes. Para enviarlos, utiliza segmentos TCP que serán encapsulados en datagramas IP. Para adaptarse a los diferentes delays en las redes y a la varianza de ellos en Internet, TCP utiliza un esquema de ventanas correderas, cuya implementación además permite control de flujo. El protocolo es básicamente Go Back N.
Las ventanas de TCP son medidas en bytes (no en segmentos), y son de tamańo variable. Como la conexión es bi-direccional, existen dos ventanas en cada extremo para los flujos en ambas direcciones. El enviador mantiene un tamańo máximo de ventana, y transmite todos los segmentos pendientes hasta completar la ventana. Los acks enviados por el receptor se anexan como piggyback a los datos que viajan en dirección contraria o como paquetes TCP con sólo el header. El número de secuencia de los segmentos y de los acks siempre referencian un número de byte (posición en la secuencia).
El receptor sabe qué número de secuencia espera y descarta todos los paquetes fuera de rango. Al recibir un paquete erróneo, siempre responde con un ack con el número de secuencia esperado. Como siempre existe un timeout esperando un ack. Al ocurrir un timeout, no sabemos qué parte de la ventana se perdió. Lo usual entonces es retransmitir sólo el primer segmento de la ventana, esperando el ack. La llegada del ack indicará de donde continuar.
La ventana trata de aproximarse a un tamańo óptimo para mantener el flujo de datos sin nunca bloquearse esperando un ack. Por otro lado, TCP la utiliza para control de flujo (por ejemplo si la aplicación deja de leer y los datos siguen llegando). Junto con cada ack viaja un anuncio con el tamańo de la ventana del receptor, que indica qué tan ocupados están sus buffers (entre TCP y la aplicación). El emisor adapta su ventana a este tamańo, agrandándola o achicándola. Para achicar la ventana, TCP no puede disminuir su número de secuencia máximo ya transmitido, sino que no avanza más y espera que los acks recibidos vayan achicando la ventana por el otro lado.
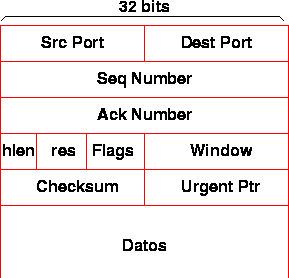
Un segmento TCP lleva un header y los datos (opcionales) como se muestra en la figura 4.15.
Los campos acknowledgement y window corresponden a datos del receptor hacia el enviador y el resto del enviador hacia el receptor. El checksum incluye las direcciones IP, los ports y el largo del paquete. Para evitar duplicar información, el largo del segmento se saca del largo del datagrama IP menos el largo del header (HLEN). Cuando se requiere enviar un ack y no hay datos pendientes, se envía un segmento vacío, sólo con el header.
El Urgent Pointer sirve para especificar datos que deben adelantar la secuencia normal para ser tratados inmediatamente por la aplicación (ej: control-C durante un telnet).
Al negociar una conexión, se intenta determinar el tamańo máximo de segmento que se enviará (MSS). La idea es determinar la MTU mínima que existe entre ambos computadores, y usar ese valor. Esto evita fragmentación utilizando paquetes lo más grandes posibles.
Originalmente, se utilizaba el valor 536 como máximo de segmento en Internet, y la MTU si era en la red local. Actualmente, se utiliza un algoritmo de path MTU Discovery, que envía paquetes IP grandes con la opción de No Fragmentar. Estos paquetes deben ser devueltos vía ICMP con un error si un router quiere fragmentarlos. En la nueva especificación, el router debe agregar al paquete ICMP su MTU, para que el algoritmo converja más rápido. Al recibir dichos mensajes, cambio el tamańo máximo de segmento al valor requerido, hasta llegar al destino. Durante el resto de la transmisión, TCP transmite todos sus segmentos con el bit de No Fragmentar. De este modo, aunque la ruta cambie alterando la MTU, TCP puede recuperarse y adaptar su MSS.
Manejar los timeouts de retransmisión es siempre complejo, porque requiere determinar el período de tiempo que demora un paquete en ir y un ack en volver. En el caso de la Internet es mucho más complejo, porque los atrasos son sumamente variables, en particular frente a congestión. Ningún protocolo con timeouts fijos sobrevive en Internet.
TCP fue revisado a fines de los '80 para optimizar su comportamiento y ha sido sintonizado para uso en Internet. Básicamente, el protocolo calcula todo el tiempo una aproximación al tiempo en ir y volver (RTT: Round Trip Time) al recibir un ack. La estimación es un promedio ponderado entre el valor anterior y la nueva estimación de modo de irse adaptando, pero no demasiado rápido (la varianza es muy alta por lo que no podemos usar sólo el último valor). La fórmula utilizada es:
RTT = (alpha * RTT) + ((1-alpha)*RTT_sample)
Actualmente, se utiliza típicamente un valor de alpha = 7/8 de modo de reaccionar lentamente a los cambios. Teniendo una estimación del tiempo promedio, normalmente se definía un timeout del doble de ese valor. Sin embargo, frente a fuerte congestión, la varianza del RTT aumenta, pudiendo incluso abarcar dentro de lo razonable el doble del RTT medio (carga sobre el 30% puede producir esto). Para evitar esto, TCP calcula también la desviación estándar del RTT (afortunadamente esto no requiere mucho cálculo) y usa la varianza multiplicada por el RTT como timeout. El código es:
DIFF = RTT_sample - RTT; RTT = RTT - alpha * DIFF; MDEV = MDEV + alpha * (abs(DIFF) - MDEV)
Un problema pendiente es cómo calcular RTT frente a retransmisiones, puesto que un ack puede corresponder al original o al retransmitido. El algoritmo de Karn, implementado en TCP, no actualiza RTT cuando se recibe el ack de un segmento retransmitido. Al mismo tiempo, el enviador multiplica por dos su timeout cada vez que retransmite un segmento. En general, se acepta un valor máximo de 120 segundos (lo que implica que será imposible usar las implementaciones actuales de TCP para comunicarse con Marte).
Otra optimización de TCP es para evitar empeorar situaciones de congestión con retransmisiones. El algoritmo se conoce como slow start y multiplicative decrease. Básicamente, el enviador maneja su ventana con dos límites: el tamańo que le informa el receptor y el tamańo de la ventana de congestión. Inicialmente, la ventana de congestión es igual a la del receptor. Pero al retransmitir un segmento, la ventana de congestión se disminuye a la mitad. En todo momento, el enviador actúa con un tamańo de ventana igual al mínimo entre la ventana del receptor y la ventana de congestión. Al seguir perdiendo datos, TCP sigue acortando la ventana y multiplicando los timeouts por dos. Eventualmente, se llega a un solo segmento y un timeout de 120 segundos. Aunque la máquina de destino haya dejado de responder, este nivel de retransmisión no contribuye a la saturación. Para evitar inestabilidades en las ventanas, la recuperación es lenta, y cada vez que se recibe un ack, la ventana de congestión se incrementa en un segmento, hasta llegar a la mitad del tamańo de la ventana del enviador. En ese nivel, TCP entra en una fase de evitar la congestión, y sólo continúa incrementando la ventana una vez que todos los segmentos en ella han recibido su ack.
Todos estos mecanismos, hacen de TCP un ``buen ciudadano" en Internet, pero también hacen que la performance se degrada mucho frente a enlaces con pérdidas de paquetes.
La interfaz estándar a TCP/IP, disponible en casi todos los sistemas operativos, son los sockets. En este capítulo nos orientaremos a Unix, pero la mayor parte de lo que diremos se aplica a todas las implementaciones.
La cantidad de parámetros a las funciones de sockets es mayor de lo necesario porque fueron diseńadas de modo de servir para múltiples protocolos y no sólo para TCP/IP. Por ello, hay que decir siempre de qué protocolo se trata y el largo de los parámetros. Por otro lado, las direcciones IP y los ports van siempre en formato de red, y deben manipularse con las funciones predefinidas para ello.
Los sockets pueden usarse tanto para TCP como para UDP,
Bind: 1 clase RPC+XDR+NFS 2 clases
Banda Ancha Multicast: 1 clase