En este nivel, suponemos que dos computadores están comunicados directamente por un "cable" bidireccional. Esto puede ser un circuito virtual, un cable serial, una conexión telefónica con modems, una ethernet, una FDDI, etc.
Suponemos que podemos hacer un 'write' de algunos bytes en ese cable y al otro lado pueden hacer un 'read'.
En el esquema OSI de layers, el nivel de datos se encarga de simular un canal de comunicaciones punto a punto libre de errores. Veremos después que, en la práctica, este no es el mejor lugar para hacer ese rol. Sin embargo, es el mejor lugar donde estudiarlo, y los protocolos y algoritmos que veremos se usan en la práctica, pero en otro nivel.
La idea es que el 'write' y el 'read' son llamadas al nivel físico para enviar los datos, pero lo podemos ver como un 'pipe' bidireccional que conecta ambas máquinas. El problema es que este 'pipe' puede tener errores: puede perder bytes y puede alterar bytes.
Par fines de este curso, vamos a suponer que el nivel físico nos entrega las siguientes primitivas:
char Pgetc(); void Pputc (char c); void Pflush();
Las acciones son las esperadas, Pgetc lee el próximo byte del link, Pputc escribe un byte. Sin embargo, por razones de eficiencia, los bytes acumulados con Pputc no se envían realmente hasta que se llama a Pflush. Los paquetes físicos no pueden ser de más de MAX_PACK bytes, así que no puedo hacer más de MAX_PACK llamados a Pputc sin llamar a Pflush.
Para poder detectar errores en los datos, la técnica más usual es encapsular los datos en un formato (Frame) que permita sincronizarse y descartar los errores. La técnica tradicional es agregar bytes a los datos, en particular un checksum. Un checksum es un número calculado en base a los datos (como un dígito verificador) que se envía junto con ellos. Al recibir los datos, el checksum se recalcula, y si no calza se sabe que hubo un error, y el Frame debe ser descartado.
Dividir los datos en Frames no es tan fácil, porque todos los bytes (también los del Frame) pueden perderse. Por ejemplo, poner primero el largo y luego los bytes puede ser peligroso, porque el largo se puede perder y uso como largo un byte de datos y luego no puedo volver a sincronizarme. Por ello, el checksum debe incorporar también los datos del Frame. Sin embargo, aun así, si debo descartar un Frame (cuyo largo no es confiable) żcómo sé dónde empieza el siguiente?
Una técnica clásica es usar bytes delimitadores de comienzo ( SOH) y fin ( EOP) de Frame. Estos son bytes especiales que sirven para sincronizarme. Sin embargo, estos bytes (tengan el valor que tengan) pueden aparecer también en los datos, y no debo confundirlos con los delimitadores. Para ello, utilizo otro byte especial ( ESC) que 'escapa' el sentido mágico de estos bytes. Entonces, si aparece un SOH en los datos, envío ESC, SOH. Un nuevo problema, claro, es qué hago si aparece ESC en los datos, y en ese caso envío ESC, ESC (un escape escapado). Obviamente, todo se puede perder, desde los delimitadores, los ESC, etc. Pero el receptor siempre podrá detectarlo. El tener delimitadores permite no tener que enviar el largo, pero por razones de eficiencia (administración de memoria) muchas veces se envía el largo también. Un ejemplo de formato de Frame se puede ver en la Figura 3.1.

Figure 3.1: Ejemplo de un Frame
El determinar cuántos bytes enviar en un Frame puede ser delicado. El rango va entre 0 y MAX_PACK (incluyendo los delimitadores y los ESC necesarios). Una línea con muchos errores puede preferir Frames pequeńos (la probabilidad de perderlos es menor), pero es más eficiente enviar Frames grandes (si no se pierden).
En general se considera el Framing como una sub-capa de la capa Datos.
Al usar Framing, los errores del medio físico (pérdidad de bytes y alteración de bytes) aumentan: ahora podemos perder Frames completos. Parte de la misión será ahora retransmitir los Frames perdidos, lo que también puede traernos la recepción de Frame duplicados o en desorden. Esto implica protocolos bastante complejos si se quiere ser eficiente.
Existen varios algoritmos de redundancia para detección y corrección de errores en una secuencia de bits. Por ejemplo, al enviar un byte por líneas seriales, típicamente se usaban 7 bits de datos y el octavo se usaba como bit de paridad (1 si el número de bits en 1 es par, 0 si es impar, o vice-versa). Esto permite detectar todos los errores de un bit. Además, si yo supiera cual bit se alteró o perdió, podría corregirlo, deduciéndolo a partir del bit de paridad (esto se usa en los arreglos de discos redundantes RAID, porque yo sé cuál disco falló).
El problema es que tampoco queremos aumentar demasiado la información que se transmite, por lo que se usan esquemas aceptados con una buena probabilidad de detectar los errores habituales. En general, es mucho más eficiente retransmitir los Frames con errores que anexar información de corrección a todos.
Por ejemplo, CRC (cyclic redundancy code) calcula 16 bits de checksum, detecta todos los errores de uno y dos bits, todos los errores de 16 o menos bits contiguos, y el 99% de los errores de bits contiguos más largos. La idea es que los errores no son realmente aleatorios en las redes, sino que vienen acumulados en bits contiguos.
Cuando el cálculo se hace en software, se trata que no consuma mucha CPU. Un ejemplo de checksum tomado de IP:
short checksum(b, n)
unsigned char *b;
int n;
{
int i, cc, sum;
for( i=0, sum=0 ; i<n ; i++ )
sum += b[i];
cc = (sum >> 16) + (sum & 0x0000ffff);
cc += (cc >> 16);
return( (short) ~ (cc & 0x0000ffff) );
}
Si queremos simular un enlace punto a punto fiable y sin errores, debemos retransmitir los frames perdidos. Intentaremos hacer un protocolo trivial primero, y veremos que no existe nada trivial con respecto a los protocolos de retransmisión.
Supongamos un layer de Framing que me permite enviar secuencias de bytes de un lado al otro. La interfaz es:
int Fread( char *buf, int size ); void Fwrite( char *buf, int size ); void Freset();
Como se pueden perder o alterar bytes, Fread me retorna size o -1 si pasa mucho tiempo sin recibir nada (timeout). Supondremos una interfaz tipo stream de bytes, no de paquetes. Es decir de qué tamańo son los frames es transparente a este nivel, Fwrite parte la secuencia en varios frames si es necesario, y Fread los pega. El tamańo del Fread y del Fwrite no tiene porqué ser el mismo, la comunicación se ve como un pipe (esto es resuelto en la capa Frame). Sin embargo, se pueden perder, alterar, etc. La función Freset permite ignorar un trozo restante de paquete, y esperar el próximo.
Un protocolo stop and wait es lo más simple que existe. La idea es transmitir un grupo de bytes y esperar que el otro lado me indique que los recibió. Sólo una vez que recibí su respuesta decido que puedo seguir enviando. Suponemos que el flujo de datos es en una sola dirección, aunque la comunicación es bi-direccional (para permitir que me indiquen que los datos llegaron). Por lo tanto hay flujo de datos y flujo de control. Los paquetes de control que usamos en este caso son muy simples: sólo indican que recibieron los datos bien. Este paquete se conoce como un Ack (de acknowledgement).
Para la aplicación, queremos darle una interfaz tipo pipe, confiable y sin errores. Para ellos usaremos la interfaz:
void Dread( char *buf, int size ); void Dwrite( char *buf, int size );
Pensemos cómo implementar estas funciones. Si no hubiese errores de ningún tipo, Dread llamaría a Fread y Dwrite a Fwrite y no habría más problemas.
Al haber errores, Dwrite debe enviar los datos y luego esperar el Ack. Si no llega despues de un tiempo, retransmite los datos y vuelve a esperar el Ack.
En Dread espero un paquete de datos. Cuando llega, reviso si está correcto, usando checksum. Si está bien, envío el Ack y retorno.
El nivel datos requiere un formato de empaquetamiento de los bytes (además del que ya provee el Frame) para poder entenderse y detectar los errores. Usaremos el esquema de la Figura 3.2.
El campo tipo es para distinguir los paquetes de datos de los paquetes de control (aunque en este primer caso no se requiere). El campo largo es un short int con el tamańo del paquete y luego los datos. Al final se anexa el checksum de verificación. Cuando es un Ack, no se envía el largo, sino directamente el checksum (para evitar que un error me haga llegar un Ack inexistente).
Una primera versión del envío es:
#define TYPE 0 /* char */
#define SIZE 1 /* short */
/* Tamano del header en bytes */
#define HEADER_SIZE 3
/* Tamano de un Ack (sin checksum) */
#define ACK_SIZE 1
#define TDATA 'D'
#define TACK 'A'
Dwrite( buf, size )
char *buf;
int size;
{
short cc;
int outsize;
char InBuf[ACK_SIZE+sizeof(short)];
/* Armamos el paquete de salida en OutBuf */
OutBuf[TYPE] = TDATA;
bcopy( buf, OutBuf + HEADER_SIZE, size );
bcopy( &size, OutBuf + SIZE, sizeof(short) );
cc = checksum( OutBuf, size + HEADER_SIZE );
bcopy( &cc, OutBuf+size+HEADER_SIZE, sizeof(short) );
outsize = size + HEADER_SIZE + sizeof(short);
for(;;)
{
Fwrite( OutBuf, outsize );
/* Espero el ACK */
if( Fread(InBuf, ACK_SIZE + sizeof(short)) != ACK_SIZE + sizeof(short) )
{
Freset();
continue;
}
if( InBuf[TYPE] != TACK)
{
Freset();
continue;
}
bcopy( InBuf+ACK_SIZE, &cc, sizeof(short) );
if( checksum( InBuf, ACK_SIZE ) != cc )
{
Freset();
continue;
}
return;
}
}
Notar el manejo del buffer con bcopy, lo que es clásico en estos programas.
La función de lectura de datos es más compleja por el manejo de los buffers de datos. El número de bytes que me piden al nivel datos no tiene porqué ser el mismo que recibo desde el nivel Físico, por lo que debo tener un buffer intermedio para manejar los bytes que sobran de una lectura a otra. Para esto uso una función que se encarga de retornarme un paquete de datos Dget_Packet.
Aparte de esto, el resto del código es simple, cada paquete de datos recibido correcto debe generar su Ack, y debo esperar tantos paquetes como sea necesario para completar los bytes que me piden:
char Dpbuf[MAX_DPACK];
int Dpsize = 0;
char *Dpcp = Dpbuf;
char Ack[] = { TACK, ' ' , ' ' };
Dread( buf, size )
char *buf;
int size;
{
for(;;)
{
if( Dpsize >= size )
{
bcopy( Dpcp, buf, size );
Dpcp += size;
Dpsize -= size;
return;
}
if( Dpsize > 0 )
{
bcopy( Dpcp, buf, Dpsize );
size -= Dpsize;
buf += Dpsize;
Dpcp = Dpbuf;
Dpsize = 0;
}
/* El resto debo leerlo */
Dpsize = Dget_packet( Dpbuf );
Dpcp = Dpbuf + HEADER_SIZE;
}
}
int Dget_packet( buf )
char *buf;
{
short size;
short cc;
/* Trato de obtener un paquete correcto */
for(;;)
{
if( Fread( buf, HEADER_SIZE ) != HEADER_SIZE )
{
Freset();
continue;
}
if( buf[TYPE] != TDATA )
{
Freset();
continue;
}
bcopy( buf+SIZE, &size, sizeof(short) );
if( size > MAX_DATA || size <= 0 )
{
Freset();
continue;
}
if( Fread(buf+HEADER_SIZE, size+sizeof(short) ) != size+sizeof(short))
{
Freset();
continue;
}
bcopy( buf+size+HEADER_SIZE, &cc, sizeof(short) );
if( checksum( buf, size+HEADER_SIZE ) != cc )
{
Freset();
continue;
}
/* Esta OK, envio Ack */
cc = checksum( Ack, ACK_SIZE );
bcopy( &cc, Ack+ACK_SIZE, sizeof(short) );
Fwrite( Ack, ACK_SIZE+sizeof(short) );
/* Retorno el paquete de datos */
return(size);
}
}
Este protocolo, que parece simple y correcto, no funciona. La retransmisión se basa en timeouts del lado del emisor. Si se pierde el paquete (o se altera, lo que es equivalente), o se pierde el Ack, el paquete será retransmitido. Si se retransmite por pérdida de paquete está bien. Pero si se retransmite por pérdida de Ack, el otro lado aceptará un paquete duplicado como correcto.
Esto se corrige agregando un número de secuencia al paquete de datos, que en este caso basta que sea un bit de modo de detectar los duplicados. El problema ahora es que los ACK's pueden confundirse (reflexionar un esquema que produzca esto). La solución es también agregar un número de secuencia a los ACK's.
El protocolo corregido implica transmitir el paquete con el bit correspondiente y esperar el Ack retransmitiendo hasta recibirlo. En el lado receptor debo recordar el bit del último paquete recibido bien, así ignoro nuevos paquetes con el mismo bit. Sólo acepto el paquete siguiente, con el bit invertido.
A pesar de ignorar estos paquetes duplicados, no puedo dejar de enviar el Ack correspondiente para que el enviador deje de retransmitirlos.
Propuesto: modifique el código anterior para tener un Stop and Wait correcto.
Este protocolo considera un emisor y un receptor. No funciona en un esquema en que se alternen los roles (por ejemplo: pedir un servicio y recibir una respuesta). Al tener datos en ambas direcciones, puedo recibir un paquete de datos al esperar un Ack y tengo que considerarlo para evitar quedar bloqueados ambos lados a la vez. Veremos en el próximo ejemplo como permitir flujo en ambas direcciones. Propuesto: Considere un diálogo trivial: envío un byte al receptor quien me contesta con otro byte igual. Encuentre un escenario, usando Dread y Dwrite, con pérdida de paquetes, que deje a ambos procesos bloqueados en Dwrite esperando un Ack.
Hay varias optimizaciones interesantes: por ejemplo en vez de esperar un timeout para retransmitir, el receptor podría ayudar enviando un Nack (Negative Acknowledgement) cuando recibe un paquete con errores, apurando la retransmisión. Pero lo más importante es eliminar los largos tiempos de bloqueo que presenta este protocolo. En general, los canales de comunicación tienen un retardo que no es despreciable (el ejemplo más típico es el satélite, donde la ida y vuelta es más de medio segundo). Por lo tanto, puedo transmitir muchos paquetes en el cable durante el tiempo que me toma llegar al otro lado y esperar el Ack de vuelta. Por supuesto, en el caso de transmitir varios paquetes antes de recibir los Acks, debo cuidar de no saturar la capacidad del receptor, lo que se denomina Control de Flujo. En Stop and Wait, esto es automático, puesto que sólo requiero almacenar un paquete cada vez.
En general, Stop and Wait sólo se usa si la simplicidad del algoritmo es lo principal y la eficiencia no interesa.
Los protocolos de comunicación avanzados intentan sacar el mayor provecho posible del enlace, en particular en casos de retardos no despreciables, que son bastante frecuentes. La idea entonces es no esperar el Ack para transmitir el próximo paquete, sino seguir transmitiendo un tiempo. Para ello, cada paquete lleva un número de secuencia, y los Acks también de modo de saber a qué paquete corresponden. El número de paquetes que tengo derecho a transmitir sin haber recibido Ack se conoce como el tamańo de mi ventana.
Obviamente, si no hay errores, este protocolo es mucho más eficiente que Stop-and-Wait, puesto que utilizo lo más que puedo el ancho de banda disponible (si logro que el tamańo de la ventana llene el cable), no teniendo que detenerme nunca. Si hay errores, depende cómo manejemos la retransmisión, la eficiencia que podamos lograr.
El receptor también maneja una ventana. En el caso que los errores no sean demasiado frecuentes, se estila un protocolo simple que usa una ventana de recepción de tamańo 1 (Go-Back-N). Cuando se esperan tasas de errores importantes, se usa una ventana de tamańo mayor (Selective Repeat), lo que permite recibir paquetes adelantados y guardarlos dentro de la ventana hasta completar el trozo faltante.
Si la ventana del enviador y del receptor son de tamańo 1, nos encontramos con Stop and Wait.
Al tener una ventana más grande en el enviador, el hecho de transmitir paquetes en secuencia, sin esperar los Acks secuenciales, introduce un nuevo error: paquetes en desorden. Como siempre, debemos garantizar que los paquetes que entregamos a la aplicación mantienen el orden original.
Estos protocolos manejan timeouts por paquetes y almacenan múltiples paquetes que fueron transmitidos pero cuyo Ack aun no llega (por si hay que retransmitirlos). Esto produce una actividad del nivel Datos que se produce en paralelo con la aplicación. Por ejemplo, la aplicación sigue generando datos mientras el nivel Datos puede estar recibiendo timeouts o Acks.
Esto lleva a que el nivel Datos ya no puede ser una sub-rutina simple de la aplicación (como en el caso previo). Por ejemplo, si la aplicación no llama más al nivel Datos (porque ya le pasó todos los datos), igual debo terminar de procesar los Acks y retransmitir los paquetes perdidos.
Por ello, el nivel Datos se considera ahora como un proceso paralelo, que se comunica y sincroniza con la aplicación. Para hacer más simple esto, las primitivas Dread y Dwrite se mantienen, pero ahora se comunican con el proceso Dlayer quien recibe entonces tres eventos:
Hay datos de la aplicación para ser leídos. Para obtener los datos usamos int FromUpperLayer(char *buf). Vienen máximo MAX_DATA bytes en el buffer. Estos datos fueron escritos con Dwrite por la aplicación.
Hay datos del nivel físico para ser leídos usando Fread. Una vez obtenidos los datos correctamente, si corresponde, se entregan a la aplicación usando ToUpperLayer(char *buf, int size).
Pasó más del tiempo esperado.
Para manejar estos eventos, el proceso Dlayer usa la función Get_next_event(int timeout) que retorna alguno de los valores anteriores. Si se invoca con timeout < 0 no hay timeout, y se bloquea hasta que exista otro evento.
La interacción entre los layers y Dlayer puede verse en la figura 3.3.
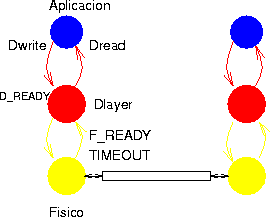
Figure 3.3: Eventos del proceso Dlayer
La idea es ir transmitiendo los paquetes de la ventana, hasta el tamańo máximo acordado. Al ir recibiendo los ACK's, la ventana se va corriendo y puedo enviar el resto de los paquetes, sin pasar el tamańo máximo.
Cada paquete tiene un timeout asociado. Cuando se cumple un timeout, decido que la transmisión de la ventana falló, y retransmito la secuencia completa. Esto me permite tener un receptor simple, con una ventana de tamańo 1. Basta con que recuerde el número de secuencia del próximo paquete que debe recibir.
Si el número de errores es bajo, este protocolo es muy eficiente con ventanas grandes. Al aumentar la tasa de errores, las ventanas deben ser más pequeńas.
En pseudo-código el receptor es:
for(;;)
switch(Get_next_event(-1))
{
case F_READY:
<<Leer proximos datos con Fread>>
<<Ver que esten correctos>>
if( buf[SEQN] == ExpectedSeqN )
{
AckBuf[SEQN] = ExpectedSeqN;
Fwrite(AckBuf, ACK_SIZE );
ExpectedSeqN++;
ToUpperLayer(buf+DATA, buf[size]);
}
}
El emisor es más complejo pues debe administrar su ventana de paquetes. En particular, el tamańo de la ventana es variable, y crece hasta
El emisor es más complejo pues debe administrar su ventana de paquetes. En particular, el tamańo de la ventana es variable, y crece hasta llegar a WINDOW_SIZE, donde debe estabilizarse. Para evitar recibir más paquetes de la aplicación, debemos crear una nueva primitiva DisableUpperLayer(). Para habilitar el envío, usaremos EnableUpperLayer().
Debemos manejar el número de secuencia del primer paquete cuyo ACK aun no recibimos ( ExpectedAck) y el arreglo de paquetes de nuestra ventana. En general esto se maneja como un arreglo circular y los números de secuencia van entre 0 y WINDOW_SIZE-1. En el pseudo-código simplemente incrementaremos los contadores.
Al recibir un timeout, el enviador debe retransmitir todos los paquetes de la ventana.
timeout = -1;
win_size = 0;
ExpectedAck = 0;
SeqN = 0;
for(;;)
{
switch(Get_next_event(timeout))
{
case D_READY:
size = FromUpperLayer(buf);
<<Armo el paquete Data Link, con checksum y Header (incluye SeqN)>>
<<Pongo el paquete en window[Last], con la hora actual>>
Fwrite(window[Last].buf, window[Last].size);
SeqN++;
Last++;
win_size++;
if( win_size == WINDOW_SIZE )
DisableUpperLayer();
break;
case F_TIMEOUT:
for(i = First; i < Last; i++)
{
<<Pongo hora actual en el paquete>>
Fwrite(window[i].buf, window[i].size);
}
break;
case F_READY:
Fread(Ackbuf, ACK_SIZE);
if( Ackbuf[SEQN] == ExpectedAck )
{
win_size--;
First++;
ExpectedAck++;
EnableUpperLayer();
}
break;
}
if( win_size > 0 ) timeout = window[First].time + TIMEOUT;
else timeout = -1;
}
Nos quedan dos preguntas: al recibir un ACK fuera de rango, debo ignorarlo? Y en el receptor, al recibir un paquete con secuencia distinto al que espero, no debo enviar un ACK? La primera es por razones de eficiencia, la segunda puede hacer que el protocolo no funcione. Reflexionar.
Si uso un arreglo circular, los números de secuencia van a repetirse, por lo cual debo cuidar que nunca sean ambiguos. Por ejemplo, un ACK retrasado, nunca debe confundirse con un ACK que no ha llegado. Pensar cómo hacer que eso sea imposible. Básicamente, si uso números de secuencia desde cero a N, la ventana tiene un tamańo máximo N (aunque hay N+1 números de secuencia posibles).
En una implementación real, el receptor y el emisor se implementan juntos, puesto que el flujo es bi-direccional. Esto complica el código, ya que un paquete puede ser un ACK o de datos.
En general, las reglas de implementación de Go-Back-N, para los paquetes o ACKs fuera de los esperados son:
En este caso, la idea es no retransmitir más que los paquetes perdidos. Para ello, el receptor también tiene una ventana, donde almacena los paquetes llegados adelantados. Esta ventana es del tamańo máximo de la ventana del enviador para asegurarse de nunca perder paquetes demás. Al recibir un paquete, el receptor revisa su número de secuencia para colocarlo en el buffer correspondiente en su ventana. Al ir llenando los primeros buffers, pueden ir pasándose a la aplicación.
Al recibir un timeout, se retransmite el paquete al que le corresponde, pero no el resto. En este caso, no podemos asumir los ACKs adelantados como validando los paquetes anteriores, puesto que el receptor envía los ACKs en cuanto recibe bien un paquete.
Por otro lado, debo tener más cuidado con los números de secuencia. Al tener varios buffers en el receptor, al avanzar la ventana voy a tener un overlap con los números anteriores. Supongan que recibo toda la ventana correcta y mis ACKs se pierden. El emisor me restransmite la ventana y yo ya la avancé. Como los números de secuencia se re-usan, voy a aceptar los duplicados como correctos. Debo entonces definir que el tamańo máximo de la ventana es la mitad del largo de la secuencia, para asegurar que no haya overlap entre una ventana y la siguiente.
Algunas optimizaciones son interesantes, por ejemplo usar NACKs en caso de paquetes erróneos. También, cuando hay flujo en dos direcciones, puedo poner los ACKs en un campo de los paquetes de datos (piggybacking) en vez de usar paquetes distintos.
Estos esquemas también se aplican en caso de varias aplicaciones compartiendo el nivel Datos. Basta multiplexar, anotando a cual conexión pertenece cada paquete.
