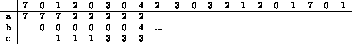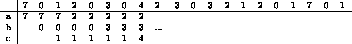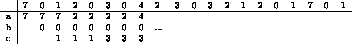Cuando la memoria real de un computador se hace insuficiente, el núcleo del sistema operativo puede emular una memoria de mayor taman o que la memoria real, haciendo que parte de los procesos se mantengan en disco. A este tipo de memoria se le denomina memoria virtual, pues es una memoria inexistente, pero que para cualquier proceso es indistinguible de la memoria real.
El mecanismo que implementa la memoria virtual se denomina paginamiento en demanda y consiste en que el núcleo lleva a disco las páginas virtuales de un proceso que tienen poca probabilidad de ser referenciadas en el futuro cercano. Un proceso puede continuar corriendo con parte de sus páginas en disco, pero con la condición de no accesar esas páginas.
La realización de un sistema de memoria virtual se hace posible gracias al principio de localidad de las referencias: un proceso tiende a concentrar el 90% de sus accesos a la memoria en sólo el 10% de sus páginas. Sin embargo, para que un proceso pueda accesar una palabra, es necesario que la página que contiene esa palabra deba estar completamente residente en memoria. Aún así, empíricamente se observa que un proceso puede pasar períodos prolongados en los que accesa sólo entre un 20 al 50% de sus páginas. El resto de las páginas puede llevarse a disco mientras no son usadas.
Las páginas residentes en disco se marcan en la tabla de páginas del proceso con el bit V en cero, de modo que si el proceso las referencia se produce una interrupción. Esta interrupción se denomina page-fault. En la rutina de atención de un page-fault, el núcleo debe cargar en memoria la página que causó el page-fault, por lo que el proceso queda suspendido mientras se realiza la lectura del disco. Cuando esta operación concluye, el proceso se retoma en forma transparente sin que perciba la ausencia temporal de esa página.
La duración de la suspensión del proceso es del orden del tiempo de acceso del disco, es decir entre 8 a 20 milisegundos.
Toda la dificultad del paginamiento en demanda está en decidir qué páginas conviene llevar a disco cuando la memoria se hace escasa. La idea es que la página que se lleve a disco debe causar un page-fault lo más tarde posible. Por lo tanto se puede deducir que el sistema de paginamiento ideal debe llevar a disco aquella página que no será usada por el período de tiempo más largo posible.
Desde luego, en términos prácticos el núcleo no puede predecir por cuanto tiempo una página permanecerá sin ser referenciada, por lo que es necesario recurrir a estrategias que se aproximen al caso ideal. Estas estrategias se denominan estrategias de reemplazo de páginas.
Las estrategias de reemplazo de páginas son realizadas por el núcleo del sistema operativos. La componente de código del núcleo que se encarga de esta labor podríamos definirlo como el scheduler de páginas.
Antes de estudiar estas estrategias examinemos el impacto que tiene una tasa elevada de page-faults en el desempen o de un proceso. Para hacer este análisis consideremos los siguientes parámetros.

Entonces el tiempo promedio de acceso a una palabra en memoria es:

Si la tasa de page-faults es 1 page-fault cada 1000 accesos, el tiempo
promedio por acceso es 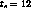 microsegundos, es decir 200 veces más
lento que el tiempo de acceso de una palabra residente en la memoria.
Esta diferencia abismante se debe a que el tiempo de carga de una
página es 200 mil veces el tiempo de acceso a una palabra en memoria
real.
microsegundos, es decir 200 veces más
lento que el tiempo de acceso de una palabra residente en la memoria.
Esta diferencia abismante se debe a que el tiempo de carga de una
página es 200 mil veces el tiempo de acceso a una palabra en memoria
real.
Por supuesto no es razonable que en un sistema con memoria virtual una aplicación corra 200 veces más lento que cuando corre en un sistema sin memoria virtual. Para que la penalización de la memoria virtual no exceda más del 10% del tiempo de acceso de una palabra es necesario que:

Es decir a lo más un page-fault por cada 2 millones de accesos a la memoria.
A continuación describiremos y evaluaremos las distintas estrategias. Veremos que estas estrategias presentan problemas ya sea de implementación o también de desempen o.
Consiste en llevar a disco aquella página que no será usada por el período de tiempo más largo. Esta estrategia es óptima, pero desde luego, no se puede implementar. Sólo sirve para comparar cifras.
: Reemplazo de páginas para la estrategia ideal
La tabla ![]() muestra el funcionamiento de esta estrategia
ante una traza de accesos a memoria. Esta traza es una lista ordenada
con los accesos que hace un proceso a sus páginas virtuales. La
tabla muestra por cada acceso a la memoria cuáles son las páginas
virtuales que se encuentran en la memoria real. Se observa que con
esta estrategia ocurren 9 page-faults en total.
muestra el funcionamiento de esta estrategia
ante una traza de accesos a memoria. Esta traza es una lista ordenada
con los accesos que hace un proceso a sus páginas virtuales. La
tabla muestra por cada acceso a la memoria cuáles son las páginas
virtuales que se encuentran en la memoria real. Se observa que con
esta estrategia ocurren 9 page-faults en total.
Entre las páginas virtuales residentes, se elige como la página a reemplazar la primera que fue cargada en memoria.
: Reemplazo de páginas para la estrategia FIFO
En la tabla ![]() se observa el funcionamiento de esta
estrategia. En total ocurren 15 page-faults. Aun cuando esta
estrategia es trivial de implementar, la tasa de page-faults es
altísima, por lo que ningún sistema la utiliza para implementar
paginamiento en demanda
se observa el funcionamiento de esta
estrategia. En total ocurren 15 page-faults. Aun cuando esta
estrategia es trivial de implementar, la tasa de page-faults es
altísima, por lo que ningún sistema la utiliza para implementar
paginamiento en demanda![]() .
.
LRU significa Least-Recently-Used. La estrategia consiste en llevar a disco la página que ha permanecido por más tiempo sin ser accesada. El fundamento de esta estrategia es que estadísticamente se observa que mientras más tiempo permanece una página sin ser accesada, menos probable es que se accese en el futuro inmediato.
: Reemplazo de páginas para la estrategia LRU
En la tabla ![]() se observa el funcionamiento de esta estrategia.
En total ocurren 12 page-faults. Si bien, es posible implementar esta
estrategia, sería necesario conocer en qué instante fue accesada
cada página. Se podría modificar el Hardware para que coloque esta
información en la tabla de páginas en cada acceso, pero en la
práctica ningún procesador lo hace. Por lo demás, si esta
información estuviese disponible, de todas formas, habría que
recorrer todas la páginas en cada page-fault, lo que sería demasiado
caro.
se observa el funcionamiento de esta estrategia.
En total ocurren 12 page-faults. Si bien, es posible implementar esta
estrategia, sería necesario conocer en qué instante fue accesada
cada página. Se podría modificar el Hardware para que coloque esta
información en la tabla de páginas en cada acceso, pero en la
práctica ningún procesador lo hace. Por lo demás, si esta
información estuviese disponible, de todas formas, habría que
recorrer todas la páginas en cada page-fault, lo que sería demasiado
caro.
Esta estrategia es una aproximación de LRU. El fundamento es que no es necesario escoger exactamente la página LRU, sino que es suficiente elegir una página que lleva harto tiempo sin ser accesada.
La estrategia usa el bit R de la tabla de página y que el hardware coloca en 1 cuando la página es accesada. El scheduler de páginas coloca en 0 este bit y lo consulta cuando estima que ha transcurrido el tiempo suficiente como para que aquella página sea reemplazada si no ha sido accesada, es decir si el bit R continúa en 0.
La estrategia del reloj ordena las páginas reales circularmente como
si fueran los minutos de un reloj (ver figura ![]() ). Un
puntero sen ala en cada instante una de las páginas. Inicialmente
todas las páginas parten con R en 0. Luego de cierto tiempo algunas
páginas han sido accesadas y por lo tanto su bit R pasa a 1.
). Un
puntero sen ala en cada instante una de las páginas. Inicialmente
todas las páginas parten con R en 0. Luego de cierto tiempo algunas
páginas han sido accesadas y por lo tanto su bit R pasa a 1.

Figure: Ordenamiento de las páginas en la estrategia del reloj.
Cuando ocurre un page-fault se ejecuta el siguiente procedimiento:
La idea es que la página elegida para ser reemplazada no ha sido accesada por una vuelta completa del reloj. La estrategia considera que este tiempo es suficiente como para suponer que la página no será accesada en el futuro inmediato.
El tiempo que demora el puntero en dar una vuelta depende de la tasa de page-faults. Mientras mayor sea esta tasa, menor será el tiempo en dar la vuelta y por lo tanto el scheduler reemplazará páginas que llevan menos tiempo sin ser accesadas. Al contrario, si la localidad de los accesos a memoria es buena, la tasa de page-faults será baja y el tiempo de una revolución del puntero aumentará. Esto quiere decir que el scheduler tendrá que reemplazar páginas que llevan más tiempo sin ser accesadas.
Una situación anómala se produce cuando todas las páginas tienen el bit R en 1 y por lo tanto el puntero avanza una vuelta completa antes de encontrar el primer bit R en 0. Esto ocurre cuando transcurre mucho tiempo sin que ocurran page-faults y todas las páginas alcanzan a ser accesadas. Esto no es realmente un problema, puesto que ocurre precisamente cuando la tasa de page-faults es muy baja. Una mala decisión en cuanto a la página reemplazada, causará un impacto mínimo en el desempen o del proceso.
Esta estrategia es fácil de implementar eficientemente con el hardware disponible y funciona muy bien con un solo proceso. En caso de varios procesos, la estrategia se comporta razonablemente en condiciones de carga moderada, pero veremos que se comporta desastrosamente cuando la carga es alta.
El problema de la estrategia del reloj es que puede provocar el fenómeno de trashing. Este fenómeno se caracteriza por una tasa elevadísima de page-faults que hace que ningún proceso pueda avanzar. De hecho, la CPU pasa más del 90% del tiempo en espera de operaciones de lectura o escritura de páginas en el disco de paginamiento.
Una vez que un sistema cae en el fenómeno de trashing, es muy difícil que se recupere. La única solución es que el operador logre detener algunos procesos. Esto podrá realizarse con mucha dificultad porque incluso los procesos del operador avanzarán ``a paso de tortuga''.
La explicación de este fenómeno está en la combinación de la estrategia del reloj con un scheduling de procesos del tipo Round-Robin. Las páginas del proceso que se retoma han permanecido largo tiempo sin ser accesadas y por lo tanto es muy probable que el scheduler de páginas las haya llevado a disco. Por lo tanto, cuando un proceso recibe una tajada de tiempo, alcanza a avanzar muy poco antes de que ocurra un page-fault.
El fenómeno de trashing se produce exactamente cuando el puntero del scheduler de páginas comienza a dar vueltas más rapidas que las vueltas que da el puntero del scheduler Round-Robin de los procesos.
Esta estrategia elimina el problema del trashing combinando paginamiento en demanda con swapping. La idea es mantener para cada proceso un mínimo de páginas que garantice que pueda correr razonablemente, es decir con una tasa de page-faults baja. Este mínimo de páginas se denomina working-set.
Si el scheduler de páginas no dispone de memoria suficiente como para tener cargados los working-set de todos los procesos, entonces se comunica con el scheduler de mediano plazo para que éste haga swapping de procesos. Es decir se llevan procesos completos a disco.
Se define 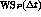 como el conjunto de páginas
virtuales del proceso P que han sido accesadas en los últimos
como el conjunto de páginas
virtuales del proceso P que han sido accesadas en los últimos
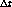 segundos de tiempo virtual del proceso P.
segundos de tiempo virtual del proceso P.
La estrategia del working-set calcula para un proceso P el valor
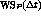 cada vez que el proceso P completa
cada vez que el proceso P completa 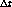 segundos de uso de la CPU. Este cálculo se realiza de la siguiente
forma:
segundos de uso de la CPU. Este cálculo se realiza de la siguiente
forma:
Se consulta el bit R de cada página q residente en memoria real del proceso P:
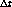 segundos
y por lo tanto no pertenece al working-set de P. La página se agrega
al conjunto C que agrupa las páginas candidatas a ser reemplazadas,
de todos lo procesos.
segundos
y por lo tanto no pertenece al working-set de P. La página se agrega
al conjunto C que agrupa las páginas candidatas a ser reemplazadas,
de todos lo procesos.
Cuando ocurre un page-fault se ejecuta:
Observe que en esta estrategia si una página pasa al conjunto C, el
tiempo transcurrido desde su último acceso está comprendido entre
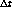 y
y 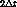 .
.
Además para que un proceso tenga la oportunidad de correr eficientemente se debe cumplir que su working-set sea inferior al taman o de la memoria real.
A continuación veremos que esta estrategia se puede optimizar de diversas formas.
Cuando ocurre un page-fault la estrategia elige una página a reemplazar. La pausa que se introduce en el proceso que causó el page-fault es doble, porque primero es necesario llevar a disco la página elegida y luego cargar de disco la página del page-fault.
Sin embargo, no es necesario llevar a disco las páginas que ya hayan sido llevadas una vez a disco y no han sido modificadas desde entonces. Esto ocurre especialmente con las páginas de código.
Para evitar llevar nuevamente estas páginas a disco se realiza lo siguiente:
Esto resuelve el problema de las páginas de código. Sin embargo, resta un conjunto elevado de páginas que todavía hay que llevarlas a disco antes de reemplazarlas. Este tiempo se puede suprimir haciendo que las páginas que se agregan a C (el conjunto de páginas candidatas a ser reemplazadas) se escriban asincrónicamente en disco. Con suerte, cuando producto de un page-fault se escoja esa página para ser reemplazada, ya se tendrá una copia en disco.
Aún así, si el conjunto C es pequen o y la tasa de page-faults es alta, es poco probable que una página alcance a ser escrita en disco. Por esta razón los sistemas operativos tratan de mantener en el conjunto C un 20% de las páginas de la memoria real. Esto garantiza que siempre habrán páginas listas para ser reemplazadas sin que sea necesario llevarlas primero a disco.
Si el taman o de C está muy por debajo de ese 20%, entonces se comienza a hacer swapping de procesos. Es decir se llevan procesos completos a disco. Al contrario, si se supera ese 20%, se pueden cargar aquellos procesos que estén en el disco.
El taman o del working-set de un proceso depende de tres factores:
Mientras mejor sea la localidad menor será el taman o del working-set y por lo tanto menos memoria real necesitará el proceso para correr eficientemente.
Este es un factor que depende únicamente de las características del proceso. El sistema operativo no puede controlar este factor.
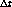 entre cálculos del working-set.
entre cálculos del working-set.
Mientras mayor sea esta cifra, mayor será la probabilidad de que una
página haya sido accesada y por lo tanto mayor será el working-set.
De hecho, el taman o del working-set crece monotamente junto con
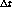 .
.
Este factor sí debe ser controlado por el scheduler de páginas del sistema operativo.
En la práctica, el taman o de una página es fijo para una arquitectura dada y no se puede modificar (4 KB en una Intel x86). Pero si fuese posible reducirlo a la mitad, intuitivamente se puede deducir que el taman o del working-set en número de páginas crecería a un poco menos del doble. Esto se debe a que el proceso accesa frecuentemente sólo una de las mitades de una página.
Ahora si se considera el taman o en bytes del working-set (calculado como número de páginas multiplicado por el taman o de la página), a menor taman o de página, menor es el taman o del working-set. Esto significa que el proceso necesita menos memoria real para correr eficientemente. Sin embargo, por otra parte, al disminuir el taman o de página aumenta el número de las páginas y por lo tanto aumenta el sobrecosto asociado al cálculo de los working-set, lo que resulta negativo en términos de desempen o.
Por lo tanto no es trivial determinar el taman o adecuado para las páginas. Pero ésta no es una decisión que efrenta el conceptor del sistema operativo. Es el disen ador de la arquitectura el que fija este valor.
Es decir que el único factor que puede controlar el scheduler de
páginas es el valor de 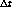 . Este valor se hace variar en
forma independiente para cada proceso en función del sobrecosto
máximo tolerado para el paginamiento en demanda. El principio es que
este sobrecosto depende de la tasa de page-faults, y esta última
depende a su vez de
. Este valor se hace variar en
forma independiente para cada proceso en función del sobrecosto
máximo tolerado para el paginamiento en demanda. El principio es que
este sobrecosto depende de la tasa de page-faults, y esta última
depende a su vez de 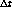 .
.
Por ejemplo si cada page-fault cuesta una pausa de 10 milisegundos y la tasa de page-faults de un proceso es de 50 páginas por segundo, entonces por cada segundo de tiempo de uso del procesador se perdería medio segundo en pausas de page-faults. Es decir el sobrecosto de la memoria virtual para el proceso sería de un 50%. Esto muestra que el sobrecosto de la memoria virtual depende de la tasa de page-faults.
La idea es entonces aumentar o disminuir el valor de 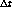 para
ajustar la tasa de page-faults a un nivel fijado como parámetro del
sistema. Si se aumenta
para
ajustar la tasa de page-faults a un nivel fijado como parámetro del
sistema. Si se aumenta 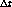 , aumenta el taman o del working-set
y entonces disminuye la tasa de page-faults.
, aumenta el taman o del working-set
y entonces disminuye la tasa de page-faults.
Al lanzar un proceso no es necesario cargar su binario de inmediato en la memoria real. La carga de binarios en demanda ( demand loading) consiste en cargar progresivamente las páginas de un binario a medida que el proceso las visita.
Esto se implementa de la siguiente forma:
El objetivo de esta técnica es mejorar el tiempo de respuesta al cargar binarios de gran taman o. Si se carga un binario de 3 MB, probablemente se requiere sólo un 10% de sus páginas para entregar los primeros resultados. Para disminuir el tiempo de respuesta, la carga en demanda lee de disco sólo este 10%, lo que resulta más rápido que cargar los 3 MB completamente.
Como dijimos anteriormente la localidad de los accesos a la memoria es un factor que depende únicamente del proceso. En particular depende de los algoritmos que utilice el proceso para realizar sus cálculos.
Los procesos que manipulan matrices u ordenan arreglos usando quick-sort son ejemplos de procesos que exhiben un alto grado de localidad en sus accesos. Al contrario, los procesos que recorren aleatoriamente arreglos de gran taman o exhiben pésima localidad en los accesos.
La programación orientada a objetos (OOP) produce programas que tienen mala localidad. Este tipo de programas crea una infinidad de objetos de pequen o taman o que se reparten uniformemente en el heap del área de datos del proceso. Si bien existe una buena localidad en el acceso a los objetos, frecuentemente una página contiene al menos uno de los objetos que están siendo accesados. Por lo tanto, a la larga son pocas las páginas que no quedan en el working-set.
El problema de la localidad en OOP se podría resolver utilizando
páginas de taman o similar al de los objetos![]() . Sin embargo aquí caemos
nuevamente en un sobrecosto desmedido para administrar un número
elevado de páginas.
. Sin embargo aquí caemos
nuevamente en un sobrecosto desmedido para administrar un número
elevado de páginas.