Las implementaciones clásicas de Unix administran los procesos en un esquema similar al de nSystem. La estrategia de scheduling de procesos es un poco más elaborada pues implementa procesos con prioridades y al mismo tiempo intenta dar un buen tiempo de respuesta a los usuarios interactivos, algo que no es fácil de lograr debido a las restricciones que impone la memoria del procesador.
Más interesante que la estrategia de scheduling es estudiar, primero, a partir de qué momento los procesos comienzan a compartir parte de su espacio de direcciones, y segundo, cómo se logra la exclusión en secciones críticas.
Cuando un proceso ejecuta una aplicación el procesador se encuentra en modo usuario, y por lo tanto algunas instrucciones están inhibidas. Si se ejecutan se produce una interrupción que atrapa el núcleo.
Los segmentos del espacio de direcciones que son visibles desde una aplicación son el de código, datos y pila.
Cuando ocurre una interrupción el procesador pasa al modo sistema e invoca una rutina de atención de esa interrupción. Esta rutina es provista por el núcleo y su dirección se rescata del vector de interrupciones, el que no es visible desde un proceso en modo usuario.
Las llamadas al sistema siempre las ejecuta el núcleo en el modo sistema. La única forma de pasar desde una aplicación al modo sistema es por medio de una interrupción. Por lo tanto las llamadas al sistema se implementan precisamente a través de una interrupción.
Cuando se hace una llamada al sistema como read, write, etc., se invoca un procedimiento de biblioteca cuya única labor es colocar los argumentos en registros del procesador y luego ejecutar una instrucción de máquina ilegal (instrucción trap). Esta instrucción causa la interrupción que el núcleo reconoce como una llamada al sistema.
Al pasar a modo sistema, comienza a ejecutarse código del núcleo.
El espacio de direcciones que se ve desde el núcleo contiene los
mismos segmentos que se ven desde una aplicación: código, datos y
pila. Pero además se agrega un nuevo segmento: el segmento
sistema. Este segmento se aprecia en la figura ![]() .
.
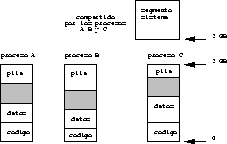
Figure: El espacio de direcciones en modo sistema.
El segmento sistema es compartido por todos los procesos. Es decir no existe un segmento sistema por proceso, sino que todos los procesos ven los mismos datos en este segmento. Si un proceso realiza una modificación en este segmento, los demás procesos verán la modificación.
El segmento sistema contiene el código del núcleo, el vector de interrupciones, los descriptores de proceso, la cola de procesos ready, las colas de E/S de cada dispositivo, los buffers del sistema de archivos, las puertas de acceso a los dispositivos, la memoria de video, etc. Enfín, todos los datos que los procesos necesitan compartir.
Por simplicidad, es usual que las implementaciones de Unix ubiquen los segmentos de la aplicación por debajo de los 2 gigabytes (la mitad del espacio direccionable) y el segmento sistema por arriba de los 2 gigabytes. Además en el segmento sistema se coloca toda la memoria real del computador. De esta forma el núcleo no solo puede ver la memoria del proceso interrumpido, sino que también pueden ver la memoria de los demás procesos.
Cada proceso pesado tiene asociado en el núcleo un proceso ligero
encargado de atender sus interrupciones (ver figura
![]() ). Este proceso ligero tiene su pila en el segmento
sistema y comparte sus datos y código con el resto de los procesos
ligeros que corren en el núcleo.
). Este proceso ligero tiene su pila en el segmento
sistema y comparte sus datos y código con el resto de los procesos
ligeros que corren en el núcleo.
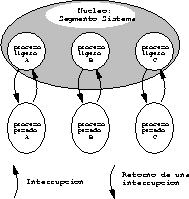
Figure: Procesos ligeros en el núcleo
Es en este proceso ligero en donde corre la rutina de atención de cualquier interrupción que se produzca mientras corre una aplicación en el modo usuario, sea esta interrupción una llamada al sistema, un evento de E/S relacionado con otro proceso, una división por cero, etc.
Conceptualmente, una llamada al sistema es un mensaje síncrono que envía el proceso pesado al proceso ligero en el núcleo. De igual forma el retorno de la rutina de atención corresponde a la respuesta a ese mensaje que permite que el proceso pesado pueda continuar.
Los procesos del núcleo se ejecutan con las interrupciones inhibidas y por lo tanto no pueden haber cambios de contexto no deseados. De esta forma se logra la exclusión en las secciones críticas del núcleo. Los cambios de contexto sólo ocurren explícitamente.
Para implementar este esquema, el hardware de los microprocesadores modernos ofrece dos punteros a la pila, uno para el modo usuario y otro para el modo sistema y su intercambio se realiza automáticamente cuando ocurre una interrupción. Desde luego, en el modo usuario, el puntero a la pila del modo sistema no es visible, mientras que en el modo sistema sí se puede modificar el puntero a la pila del modo usuario.
Cuando un proceso Unix pasa al modo sistema, le entrega el control a su respectivo proceso ligero en el núcleo. Este último corre con las interrupciones inhibidas, comparte el segmento sistema y tiene acceso a toda la máquina. Por lo tanto conceptualmente es similar a una nano tarea en nSystem que inhibe las interrupciones con START_CRITICAL(), comparte el espacio de direcciones con otras nano tareas y tiene acceso a todo el procesador virtual.
Es decir, un proceso pesado en Unix que llama al sistema o es interrumpido se convierte en un proceso ligero ininterrumpible en el núcleo. Luego, los algoritmos y estrategias que se vieron para nSystem pueden ser usados para implementar mensajes, semáforos, E/S, etc. en un monoprocesador bajo Unix.
El esquema presentado tiene la ventaja de ser simple de implementar. Sin embargo tiene la desventaja de que el sistema permanece largos períodos con las interrupciones inhibidas, lo que puede ser inaceptable para sistemas de control automático. Este tipo de sistemas requieren a veces respuestas rápidas a eventos, en el rango de unos pocos micro-segundos.
Ejemplos de sistemas que usan este esquema son Unix SCO, Berkeley Unix y Linux.
Un multiprocesador puede correr varios procesos Unix en paralelo. Todos los procesadores comparten la memoria real del computador, pero la visión conceptual de un proceso Unix sigue siendo la misma: un solo procesador en donde corre un programa. Es decir que los múltiples procesos Unix que corren en un multiprocesador no comparten sus espacios de direcciones.
En este esquema hay un reloj regresivo por procesador. De modo que el tiempo de cada procesador se puede multiplexar en tajadas de tiempo que se otorgan por turnos a los distintos procesos que estén listos para correr. Cada vez que ocurre una interrupción del reloj regresivo, la rutina de atención debe colocar el proceso en ejecución en la cola global de procesos ready, extraer un nuevo proceso y ejecutarlo.
El problema se presenta cuando la interrupción se produce simultáneamente en dos procesadores. Entonces los dos procesadores modificarán paralelamente la cola global de procesos, con el peligro de dejar la cola en un estado inconsistente.
Cuando todos los procesadores ejecutan instrucciones en el modo usuario, no hay secciones críticas puesto que los procesos que corren en cada procesador no comparten sus espacios de direcciones. De igual forma si sólo uno de los procesadores se encuentra en el modo sistema, no hay peligro de modificación concurrente de una estructura de datos compartida.
El peligro de las secciones críticas se presenta cuando hay 2 o más procesadores reales en el modo sistema al mismo tiempo, es decir en el núcleo compartiendo el mismo segmento sistema.
Por lo tanto, la forma más simple de implementar Unix en un multiprocesador es impedir que dos procesadores puedan correr simultáneamente en el modo sistema.
El problema es cómo impedir que dos procesadores ejecuten en paralelo código del núcleo. La solución estándar en un monoprocesador que consiste en inhibir las interrupciones no funciona en un multiprocesador. En efecto, sólo se pueden inhibir las interrupciones externas a la CPU, es decir las del reloj regresivo y las de E/S. Un proceso en el modo usuario puede realizar llamadas al sistema con las interrupciones externas inhibidas.
Es decir que si dos procesos que se ejecutan en procesadores reales llaman al sistema al mismo tiempo, ambos entrarán al núcleo y habrá dos procesadores corriendo en el modo sistema. Esto originará problemas de sección crítica.
Para impedir que dos procesadores pasen al modo sistema simultáneamente por medio de una llamada al sistema, se coloca un candado ( lock) a la entrada del núcleo. Cuando un procesador entra al núcleo cierra el candado. Si otro procesador intenta entrar al núcleo tendrá que esperar hasta que el primer proceso abra el candado al salir del núcleo.
El candado es una estructura de datos que posee dos operaciones:
Lock(&lock): Si el candado está cerrado espera hasta
que esté abierto. Cuando el candado esta abierto, cierra el
candado y retorna de inmediato.
Unlock(&lock): Abre el candado y retorna de inmediato.
El candado se cierra al principio de la rutina de atención de las interrupciones por llamadas al sistema. Es decir cuando el procesador ya se encuentra en el modo sistema, pero todavía no ha realizado ninguna acción peligrosa. Si el procesador encuentra cerrado el candado, se queda bloqueado hasta que el candado sea abierto por el procesador que se encuentra en el modo sistema. Mientras tanto el procesador bloqueado no puede ejecutar otros procesos, pues dado que la cola ready es una estructura de datos compartida, no puede tener acceso a ella para extraer y retomar un proceso.
El candado se abre en la rutina de atención justo antes de retornar a la aplicación.
Observe que no es razonable implementar el candado antes de que la aplicación pase al modo sistema, puesto que nadie puede obligar a una aplicación a verificar que el candado está abierto antes de hacer una llamada al sistema.
La siguiente implementación es errónea. El candado se representa mediante un entero que puede estar OPEN o CLOSED.
void Lock(int *plock)
{
while (*plock==CLOSED)
;
*plock=CLOSED;
}
void Unlock(int *plock)
{
*plock= OPEN;
}
El problema es que dos procesadores pueden cargar simultáneamente el valor de *plock y determinar que el candado esta abierto y pasar ambos al modo sistema.
Para implementar un candado, la mayoría de los microprocesadores ofrecen instrucciones de máquina atómicas (indivisibles) que permiten implementar un candado. En sparc esta instrucción es:
swap dir. en memoria, reg
Esta instrucción intercambia atómicamente el contenido de la dirección especificada con el contenido del registro. Esta instrucción es equivalente al procedimiento:
int Swap(int *ptr, int value)
{
int ret= *ptr;
*ptr= value;
return ret;
}
Sólo que por el hecho de ejecutarse atómicamente, dos procesadores que tratan de ejecutar en paralelo esta instrucción, serán secuencializados.
Veamos como se puede usar este procedimiento para implementar un candado:
void Lock(int *plock)
{
while (Swap(plock, CLOSED)==CLOSED)
mini-loop(); /* busy-waiting */
}
void Unlock(int *plock)
{
*plock= OPEN;
}
Observe que si un procesador encuentra el candado cerrado, la operación swap se realiza de todas formas, pero el resultado es que el candado permanece cerrado. En inglés, un candado implementado de esta forma se llama spin-lock.
Si el candado se encuentra cerrado, antes de volver a consultar por el candado se ejecuta un pequen o ciclo que dure algunos micro-segundos. Esto se hace con el objeto de disminuir el tráfico en el bus de datos que es compartido por todos los procesadores para llegar a la memoria. Para poder entender esto es necesario conocer la implementación del sistema de memoria de un multiprocesador que incluye un caché por procesador y un protocolo de coherencia de cachés.
Se ha presentado una solución simple para implementar Unix en un multiprocesador. La solución consiste en impedir que dos procesadores puedan ejecutar simúltanemente código del núcleo, dado que comparten el mismo segmento sistema.
Este mecanismo se usa en SunOS 4.X ya que es muy simple de implementar sin realizar modificaciones mayores a un núcleo de Unix disen ado para monoprocesadores, como es el caso de SunOS 4.X. Este esquema funciona muy bien cuando la carga del multiprocesador está constituida por procesos que requieren mínima atención del sistema.
La desventaja es que en un multiprocesador que se utiliza como servidor de disco en una red, la carga está constituida sobretodo por muchos procesos ``demonios'' que atienden los pedidos provenientes de la red (servidores NFS o network file system). Estos procesos demonios corren en SunOS sólo en modo sistema. Por lo tanto sólo uno de estos procesos puede estar ejecutándose en un procesador en un instante dado. El resto de los procesadores está eventualmente bloqueado a la espera del candado para poder entrar al modo sistema.
Si un procesador logra extraer un proceso para hacerlo correr, basta que este proceso haga una llamada al sistema para que el procesador vuelva a bloquearse en el candado por culpa de que otro procesador esta corriendo un proceso NFS en el núcleo.
Para resolver definitivamente el problema de las secciones críticas en el núcleo de un sistema operativo para multiprocesadores se debe permitir que varios procesadores puedan ejecutar procesos ligeros en el núcleo. Además estos procesos deben ser interrumpibles. Los procesos ligeros del núcleo deben sincronizarse a través de semáforos, mensajes o monitores.
Un semáforo del núcleo se implementa usando un spin-lock. Éste es un candado a la estructura de datos que representa el semáforo. Las operaciones sobre semáforos las llamaremos kWait y kSignal para indicar que se llaman en el kernel (núcleo).
void kWait(kSem sem)
{
Lock(&sem->lock);
if (sem->count>0)
{
sem->count--;
Unlock(&sem->lock);
}
else
{
currentTask()->status= WAIT_SEM;
PutTask(sem->queue, currentTask());
Unlock(&sem->lock);
/* Retoma otra tarea */
ResumeNextReadyTask();
}
}
El principio es que el candado permanece cerrado sólo cuando un procesador está manipulando el semáforo. Si el contador está en 0, el proceso se coloca en la cola del semáforo, se abre nuevamente el candado y el procesador llama al scheduler para retomar un nuevo proceso. En ningún caso, el procesador espera en un spin-lock hasta que el contador del semáforo se haga positivo. De esta forma, el tiempo que permanece cerrado el candado es del orden de un microsegundo, muy inferior al tiempo que puede permanecer cerrado el candado que permite el acceso al núcleo en SunOS 4.X.
Observe que cuando hay varios procesadores corriendo, no se puede tener una variable global que apunta al proceso en ejecución. Además, el scheduler debe tener otro candado asociado a la cola de procesos ready, para evitar que dos procesadores extraigan o encolen al mismo tiempo.
El código para kSignal es:
void kSignal(Sem sem)
{
Lock(&sem->lock);
if (EmptyQueue(sem->queue))
{
sem->count++;
Unlock(&sem->lock);
}
else
{
nTask wait_task= GetTask(sem->queue);
Unlock(&sem->lock);
wait_task->status= READY;
/* ready_lock es el candado para
la ready_queue */
Lock(&ready_lock);
PushTask(ready_queue, current_task);
PushTask(ready_queue, wait_task);
Unlock(&ready_lock);
/* wait_task no necesariamente es la
primera en la cola! Por qué? */
ResumeNextReadyTask();
}
}
Ejemplos de sistemas operativos que usan este esquema son Solaris 2, Unix System V.4, Window NT y Mach (Next y OSF/1). Se dice que el núcleo de estos sistemas es multi-threaded, porque pueden correr en paralelo varios threads en el núcleo, a diferencia de la implementación clásica en donde corre un solo thread en el núcleo, y además es ininterrumpible.