Como dijimos anteriormente el scheduling de procesos intenta lograr algún objetivo particular como maximizar la utilización del procesador o atender en forma expedita a usuarios interactivos. Para lograr estos objetivos se usan diversas estrategias que tienen sus ventajas y desventajas. A continuación se explican las estrategias más utilizadas.
Ésta es una estrategia para procesos non-preemptive. En ella se atiende las ráfagas en forma ininterrumpida en el mismo orden en que llegan a la cola de procesos, es decir en orden FIFO.
Esta estrategia tiene la ventaja de ser muy simple de implementar. Sin embargo tiene varias desventajas:
Por ejemplo supongamos que llegan 3 ráfagas de duración 24, 3 y 3.
Si el orden de llegada es 24, 3 y 3, el tiempo promedio de despacho es:
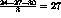
Si el orden de llegada es 3, 3 y 24, el promedio es:
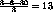
Observe que aun cuando esta estrategia es non-preemptive esto no impide que en medio de una ráfaga de CPU pueda ocurrir una interrupción de E/S que implique que un proceso en espera pase al estado listo para correr.
En principio si se atiende primero las ráfagas más breves se minimiza el tiempo promedio de despacho. Por ejemplo si en la cola de procesos hay ráfagas que van a durar 5, 2, 20 y 1, estas ráfagas deberían ser atendidas en el orden 1, 2, 5 y 20. El tiempo promedio de despacho sería:
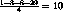
Se demuestra que este promedio es inferior a cualquier otra permutación en el orden de atención de las ráfagas. Pero desde luego el problema es que el scheduler no puede predecir el tiempo que tomará una ráfaga de CPU.
Sin embargo es posible calcular un predictor del tiempo de duración de una ráfaga a partir de la duración de las ráfagas anteriores. En efecto, se ha comprobado empíricamente que la duración de las ráfagas tiende a repetirse. El predictor que se utiliza usualmente es:
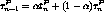
En donde:

Típicamente 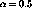 . Con esta fórmula se pondera especialmente
la duración de las últimas ráfagas, ya que al expandir esta fórmula
se obtiene:
. Con esta fórmula se pondera especialmente
la duración de las últimas ráfagas, ya que al expandir esta fórmula
se obtiene:
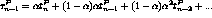
De este modo cuando hay varios procesos en la cola de procesos listos para correr, se escoge aquel que tenga el menor predictor.
SJF puede ser non-preemptive y preemptive. En el caso non-preemptive una ráfaga se ejecuta completamente, aún cuando dure mucho más que su predictor. Desde luego, la variante non-preemptive se usa sólo en sistemas batch.
En el caso preemptive se establece una cota al tiempo de asignación del procesador. Por ejemplo la cota podría ser el segundo predictor más bajo entre los procesos listos para correr. También hay que considerar el caso en que mientras se ejecuta una ráfaga, llega una nueva ráfaga con un predictor menor. En este caso, la ráfaga que llega debería tomar el procesador.
En esta estrategia se asocia a cada proceso una prioridad. El
scheduler debe velar porque en todo momento el proceso que está
corriendo es aquel que tiene la mayor prioridad entre los procesos que
están listos para correr. La prioridad puede ser fija o puede ser
calculada. Por ejemplo SJF es un caso particular de scheduling con
prioridad en donde la prioridad se calcula como  .
.
El problema de esta estrategia es que puede provocar hambruna (starvation), ya que lo procesos con baja prioridad podrían nunca llegar a ejecutarse porque siempre hay un proceso listo con mayor prioridad.
Aging es una variante de la estrategia de prioridades que resuelve el problema de la hambruna. Esta estrategia consiste en aumentar cada cierto tiempo la prioridad de todos los procesos que se encuentran listos para correr. Por ejemplo, cada un segundo se puede aumentar en un punto la prioridad de los procesos que se encuentran en la cola ready. Cuando el scheduler realiza un cambio de contexto el proceso saliente recupera su prioridad original (sin las bonificaciones).
Desde este modo, los procesos que han permanecido mucho tiempo en espera del procesador, tarde o temprano ganarán la prioridad suficiente para recibirlo.
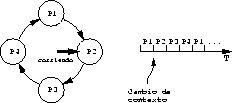
Es una estrategia muy usada en sistemas de tiempo compartido. En
Round-Robin los procesos listos para correr se organizan en una
lista circular. El scheduler se pasea por la cola dando tajadas
pequen as de tiempo de CPU ( time slicing): de 10 a 100
milisegundos. Esta estrategia se aprecia en la figura ![]() .
.
Esta estrategia minimiza el tiempo de respuesta en los sistemas interactivos. El tiempo de respuesta es el tiempo que transcurre entre que un usuario ingresa un comando interactivo hasta el momento en que el comando despliega su primer resultado. No se considera el tiempo de despliegue del resultado completo. Esto se debe a que para un usuario interactivo es mucho más molesto que un comando no dé ninguna sen al de avance que un comando que es lento para desplegar sus resultados. Por esta razón el tiempo de respuesta sólo considera el tiempo que demora un comando en dar su primer sen al de avance.
Esta estrategia se implementa usando una cola FIFO con todos los procesos que están listos para correr. Al final de cada tajada el scheduler coloca el proceso que se ejecutaba al final de la cola y extrae el que se encuentra en primer lugar. El proceso extraído recibe una nueva tajada de CPU. Para implementar la tajada, el scheduler programa una interrupción del reloj regresivo de modo que se invoque una rutina de atención (que pertenece al scheduler) dentro del tiempo que dura la tajada.
Si un proceso termina su ráfaga sin agotar su tajada (porque pasa a un modo de espera), el scheduler extrae el próximo proceso de la cola y le da una nueva tajada completa. El proceso que terminó su ráfaga no se coloca al final de la cola del scheduler. Este proceso queda en alguna estructura de datos esperando algún evento.
Una primera decisión que hay que tomar es qué taman o de tajada asignar. Si la tajada es muy grande la estrategia degenera en FCFS con todos sus problemas. Al contrario si la tajada es muy pequen a el sobrecosto en cambios de contexto es demasiado alto.
Además si la tajada es muy pequen a aumenta el tiempo promedio de despacho. En efecto, si se tienen dos ráfagas de duración t. El tiempo medio de despacho de ambas ráfagas en FCFS será:
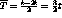
En cambio en RR con tajada mucho más pequen a que t, ambas ráfagas serán despachadas prácticamente al mismo tiempo en 2t, por lo que el tiempo medio de despacho será:
Una regla empírica que da buenos resultados en Round-Robin es que se fija el taman o de la tajada de modo que el 80% de las ráfagas deben durar menos que la tajada y por lo tanto se ejecutan sin cambios de contexto de por medio.
El segundo problema que hay que resolver es donde colocar los procesos
que pasan de un estado de espera al estado listo para correr. Es
decir en que lugar agregar estos procesos en la lista circular de
Round-Robin (ver figura ![]() ).
).
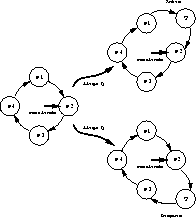
Figure: Inserción de procesos en Round-Robin
Cuando un proceso llega, las dos únicas posibilidades son agregarlo antes del proceso en ejecución o agregarlo después.
La primera posibilidad se implementa agregando el proceso que llega al final de la cola del scheduler. Este proceso deberá esperar una vuelta completa antes de que lo toque su tajada. Esto tenderá a desfavorecer a los procesos intensivos en E/S debido a que sus ráfagas terminan mucho antes que la tajada, teniendo que esperar la vuelta completa después de cada operación de E/S. En cambio, los procesos intensivos en CPU agotarán completamente su tajada antes de tener que esperar la vuelta completa.
En la segunda posibilidad el proceso que llega se agrega en primer lugar en la cola del scheduler (es decir la cola ya no es siempre FIFO). Esta variante tiene un comportamiento más errático. Veamos qué sucede en los siguientes casos: