Justificación
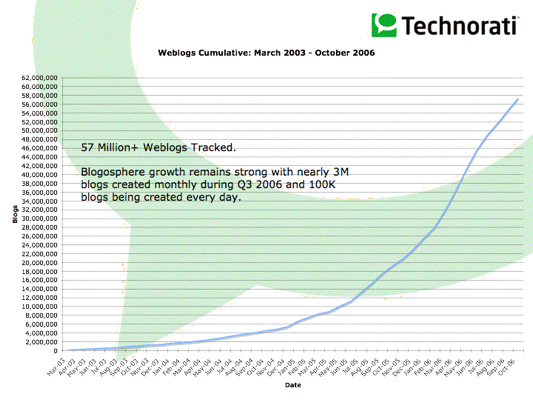
El nuevo escenario de la Web presenta a ésta como un meta-medio de comunicación. Ahora es la comunidad la que genera (y consume) sus propios contenidos, a través de los weblogs (blogs) o suscribiéndose a los distintos feeds de noticias en linea disponibles.Esta corriente ha tenido un explosivo crecimiento en los últimos años, provocando una proliferación de fuentes de información. Existe una gran cantidad de contenidos, noticias, artículos. Y con el crecimiento de la cantidad de fuentes, el flujo de nuevos contenidos que produce la red produce un escenario donde al usuario común cada día le cuesta más aprovechar la información disponible. Esto genera la necesidad de mejorar de alguna manera la forma en que ese gran flujo de información es presentado al usuario.
|
Se desearía tener la capacidad de percibir, de alguna manera, cuales son los principales temas tratados en la blogósfera, en general, o en algún dominio en particular (por ejemplo, para un cierto tema, o para un país). Se quisiera, más precisamente, disponer de un meta-editor periodístico, que logre identificar cuales son los titulares con las últimas noticias, o que muestre cuales son los tópicos de moda en el conjunto de weblogs. Pero ese meta-editor, debiera ser un agente acorde a la filosofía de la Web2.0, es decir, se base en una forma de periodismo participativo, realizando un diseño editorial social.
El caso de estudio a analizar, corresponderá al conjunto de blogs y canales de noticias de Chile, a través del sitio web orbitando.com. Este sitio realiza un polling2.1 de artículos RSS relacionados con el país, recogiendo artículos de blogs, noticias de medios online, y feeds con resultados de búsquedas relacionadas con Chile, tratando de ser una ventana a la blogósfera chilena2.2. Actualmente, este sitio reúne más de 2000 canales, y posee un registro histórico de más de 1 millón de artículos.
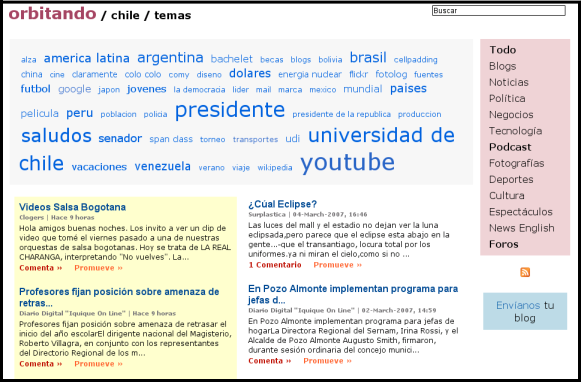
El proyecto consistirá en realizar una segmentación del conjunto de artículos, agrupándolos según diversas dimensiones: temporal, geográfica, popularidad, temática. En especial, se desea dar énfasis al concepto de ``cercanía temática'', para lo cual se buscarán formas de medir la similaridad entre distintos artículos. Utilizando aquella función de similaridad (o de distancia entre documentos), se irán agrupando, formando clusters que representarán los distintos tópicos. De este conjunto de tópicos, se elegirán los principales (los más populares), y de cada uno de ellos, se mostrará un artículo que sirva de representante de su grupo. En este caso, se mostrará su titular, como una forma de mostrar el tema del tópico.
El modelo inspirador, es el de un editor de un medio de prensa escrito, el cual recibe un conjunto de artículos y noticias, y cada día debe ordenar los temas, elegir los temas principales, evitar redundancias en lo que se publica, categorizar y ordenar las notas. Lo que se quiere hacer en este caso, es algo similar, pero basándose en toda la información disponible bajo el modelo de información sindicada.
El primer desafío a abordar, corresponde a la transformación de los artículos en vectores que permitan construir un espacio vectorial donde se pueda realizar la tarea de minado de datos. Para ello, se recurrirá a las técnicas propuestas por la minería de texto, en particular, al proceso de transformar documentos en vectores, según el modelo de espacio vectorial[11]. Sin embargo, esta transformación no es suficiente, ya que es necesario tomar en cuenta la no estacionalidad de los artículos [9]. Esto implica considerar la variable temporal, junto a los demás atributos que se consideren como parte de cada artículo.
Una vez configurado este espacio vectorial de artículos, la siguiente tarea es la de realizar la segmentación. Se recurrirá a la técnica de clustering2.3, la cual permite agrupar los vectores según su grado de similaridad. Para realizar esta tarea, se dispone de una serie de algoritmos que pueden facilitar esta labor. En primer lugar se deberá elegir el algoritmo a utilizar, tomando en consideración principalmente la naturaleza incremental del problema. A continuación, se deberá precisar la función de similaridad o distancia, que permita comparar documentos.
Finalmente, se elegirán los principales clusters del espacio, y se llevará el título de uno de sus artículos (un representante de cada grupo) para ser mostrado en una especie de nube de titulares, que buscará mostrar en el sitio web (orbitando.com) los principales temas de su dominio, ya sea toda la colección, o algúna categoría en particular. A su vez, ese titular será un enlace a un conjunto de artículos relacionados con el tópico, los cuales se mostrarán utilizando algún tipo de ranking (correspondiente a un ranking interno de su cluster) para permitir al usuario hacer un seguimiento de la noticias/tema de su interés.
 dcc.uchile.cl
dcc.uchile.cl