Dado que en Unix un proceso pesado corre en un procesador virtual es posible implementar un sistema de threads que comparten el mismo espacio de direcciones virtuales en un proceso Unix. Un ejemplo de estos sistemas es el nano System (nSystem de ahora en adelante).
En vez de usar la palabra thread --que es difÚcil de pronunciar en castellano-- usaremos como sinµnimo la palabra tarea. Las tareas de nSystem se implementan multiplexando el tiempo de CPU del proceso Unix en tajadas de tiempo que se otorgan por turnos a cada tarea, de la misma forma en que Unix multiplexa el tiempo del procesador real para otorgarlo a cada proceso pesado.
De esta forma varios procesos Unix puede tener cada uno un enjambre de tareas que comparten el mismo espacio de direcciones, pero tareas pertenecientes a procesos distintos no comparten la memoria.
Los siguientes procedimientos de nSystem permiten crear, terminar y esperar tareas:
En la figura ![]() se observa que si una tarea A espera otra
tarea B antes de que B haya terminado, A se bloquea hasta que B
invoque nExitTask. De la misma forma, si B termina antes de que
otra tarea invoque nWaitTask, B no termina --permanece
bloqueada-- hasta que alguna tarea lo haga.
se observa que si una tarea A espera otra
tarea B antes de que B haya terminado, A se bloquea hasta que B
invoque nExitTask. De la misma forma, si B termina antes de que
otra tarea invoque nWaitTask, B no termina --permanece
bloqueada-- hasta que alguna tarea lo haga.
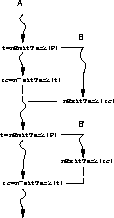
Figure: Creaciµn, espera y tÕrmino de tareas en nSystem
Como ejemplo veamos como se calcula un nºmero de Fibonacci usando las tareas de nSystem:
int pfib(int n)
{
if (n<=1) return 1;
else
{
nTask task1= nEmitTask(pfib, n-1);
nTask task2= nEmitTask(pfib, n-2);
return nWaitTask(task1)+nWaitTask(task2);
} }
La ejecuciµn de pfib(6) crea dos tareas que calculan concurrentemente pfib(5) y pfib(4). Como a su vez estos dos procedimientos crean nuevas tareas, al final se crea un Ãrbol de tareas.
Observe que esta soluciµn se introduce sµlo con motivos pedagµgicos. Ella es sumamente ineficiente como mecanismo para calcular un nºmero de Fibonacci, puesto que el sobrecosto natural introducido por la gestiµn de un nºmero exponencial de tareas es colosal. Para que esta soluciµn sea eficiente se necesitarÚa una implementaciµn de nSystem que usara procesadores reales para cada tarea creada, pero en la actualidad esto no es posible en ningºn multi-procesador de memoria compartida.
Supongamos que en el problema anterior se desea contar el nºmero de tareas que se crean. La soluciµn natural que se viene en mente es introducir una variable global count que se incrementa en cada llamada de pfib:
int count=0;
int pfib(int n)
{
count++;
if (...) ...
else ...
}
Esta soluciµn es errada. En efecto, la instrucciµn en C count++ se traduce por una secuencia de instrucciones de mÃquina del tipo:
Load count, Reg ; Reg= count Add Reg, 1, Reg ; Reg= Reg+1 Store Reg, count ; count= Reg
En la figura ![]() se aprecia cµmo la ejecuciµn en paralelo
de dos de estas secuencias puede terminar incrementando count
sµlo en 1. Esta situaciµn es un error porque no se contabiliza una
de las invocaciones de pfib.
se aprecia cµmo la ejecuciµn en paralelo
de dos de estas secuencias puede terminar incrementando count
sµlo en 1. Esta situaciµn es un error porque no se contabiliza una
de las invocaciones de pfib.

Figure: Ejecuciµn concurrente de una misma secciµn crÚtica
En el ejemplo hemos supuesto que ambas tareas se ejecutan en dos
procesadores reales. Sin embargo, hemos dicho que nSystem no
implementa paralelismo real sino que emula varios procesadores a
partir de un solo proceso multiplexando en tajadas el tiempo de CPU.
Esta forma de ejecutar procesos tambiÕn puede resultar en un nºmero
errado para count, cuando una tajada de tiempo de CPU se acaba
justo cuando un proceso està en medio del incremento de count
![]() .
.
Este tipo de problemas es muy comºn en los procesos que comparten algºn recurso, en este caso la variable count. El problema es que la utilizaciµn del recurso no es atµmica, se necesita una secuencia de instrucciones para completar una operaciµn sobre el recurso, en el ejemplo, la contabilizaciµn de una invocaciµn de pfib. El problema es que la ejecuciµn de esta operaciµn no debe llevarse a cabo concurrentemente en mÃs de una tarea en un instante dado, porque el resultado serà impredescible.
Una secciµn crÚtica es una porciµn de cµdigo que sµlo puede ser ejecutada por una tarea a la vez para que funcione correctamente. En el ejemplo la instrucciµn count++ (es decir su traducciµn a instrucciones de mÃquina) es un a secciµn crÚtica.
En nSystem se pueden implementar secciones crÚticas mediante mensajes. El envÚo de mensajes en nSystem se logra con los siguientes procedimientos:
La tarea que lo invoca queda bloqueada por max_delay miliseg, esperando un mensaje. Si el perÚodo finaliza sin que llegue alguno, se retorna NULL y *ptask queda en NULL. Si max_delay es 0, la tarea no se bloquea (nReceive retorna de inmediato). Si max_delay es -1, la tarea espera indefinidamente la llegada de un mensaje.
Con estos procedimientos el problema de la secciµn crÚtica se puede resolver creando una tarea que realiza el conteo de tareas.
int count=0; /* Contador de tareas */
/* Crea la tarea para el conteo y la tarea
* que calcula concurrentemente Fibonacci(n)
*/
int pfib(int n, int *pcount)
{
nTask counttask= nEmitTask(CountProc);
int ret= pfib2(n, counttask);
int end= TRUE;
nSend(counttask, (void*)&end);
*pcount= nWaitTask(counttask);
return ret;
}
/* Realiza el conteo de tareas */
int CountProc()
{
int end= FALSE;
int count=0;
do
{
nTask sender;
int *msg= (int*)nReceive(&sender, -1);
end= *msg;
count++;
nReply(sender, 0);
}
while (end==FALSE);
return count-1;
}
/* Calcula Concurrentemente Fibonacci(n) */
int pfib2(int n, nTask counttask)
{
int end= FALSE;
nSend(counttask, (void*)&end);
if (n<=1) return 1;
else
{
nTask task1=nEmitTask(pfib,n-1,counttask);
nTask task2=nEmitTask(pfib,n-2,counttask);
return nWaitTask(task1)+nWaitTask(task2);
} }
Esta soluciµn resuelve efectivamente el problema de la secciµn crÚtica, puesto que la ºnica tarea que incrementa el contador es counttask, y Õsta se ejecuta estrictamente en secuencia. En el fondo, la soluciµn funciona porque el contador ya no es una variable de acceso compartido. Aunque todas las tareas tienen acceso a este contador, sµlo una tarea lo accesa verdaderamente.
Es importante destacar que el siguiente cµdigo podrÚa no funcionar.
int *msg= (int*)nReceive(&sender, -1); nReply(sender, 0); end= *msg;
En efecto, al hacer nReply el emisor puede continuar y retornar de pfib2 y por lo tanto destruir la variable end que contiene el mensaje, antes de que se ejecute end=*msg;. Esto entregarÚa resultados impredescibles.
El paradigma que hay detrÃs de esta soluciµn es el de cliente/servidor. Se crea una tarea servidor ( counttask) que da el servicio de conteo, mientras que fibtask y las demÃs tareas que se crean para calcular Fibonacci son los clientes.
Nµtese que al introducir este servidor, ni siquiera con infinitos procesadores la soluciµn serÚa eficiente puesto que se establece un cuello de botella en el servidor. En efecto el servidor de conteo es estrictamente secuencial. Las dos tareas que se crean concurrentemente tienen que ser atendidas secuencialmente por el servidor.
Muchos procedimientos de biblioteca de Unix pueden continuar usÃndose en nSystem, sin embargo gran cantidad de procedimientos de biblioteca usan variables globales cuyo acceso se convierte en una secciµn crÚtica en nSystem. El cµdigo original de Unix no implementa ningºn mecanismo de control que garantice que una sola tarea està invocando ese procedimiento, puesto que Unix estÃndar no ofrece threads. Por lo tanto los procedimientos de biblioteca de Unix que usan y modifican variables globales no pueden ser invocados directamente desde nSystem. Para llamar estos procedimientos en nSystem hay que implementar un mecanismo de control de acceso entre tareas.
Durante el lanzamiento de nSystem se realizan algunas inicializaciones y luego se invoca el procedimiento nMain, el que debe ser suministrado por el programador. èste procedimiento contiene el cµdigo correspondiente a la primera tarea del programador. Desde ahÚ se pueden crear todas las tareas que sean necesarias para realizar el trabajo. El encabezado para este procedimiento debe ser:
int nMain(int argc, char *argv[])
{
...
}
El retorno de nMain hace que todas las tareas pendientes terminen y por lo tanto es equivalente a llamar nExitSystem. Es importante por lo tanto evitar que nMain se termine antes de tiempo.
Los siguientes procedimientos son parte de nSystem y pueden ser invocados desde cualquier tarea de nSystem.
Par'ametros para las tareas:
Entrada y Salida:
Los siguientes procedimientos son equivalentes a open, close, read y write en UNIX. Sus parÃmetros son los mismos. Los ``nano'' procedimientos sµlo bloquean la tarea que los invoca, el resto de las tareas puede continuar.
Servicios MiscelÃneos:
Veamos como se resuelve el problema del buffering usando tareas. Este mismo problema se resolverà en el prµximo capÚtulo usando interrupciones y canales.
nTask bufftask= nEmitTask(BuffServ);
void ReadBuff(int *pbuff)
{
nSend(bufftask, (void*)pbuff);
}
void BuffServ()
{
char pbuff2[512];
for(;;)
{
nTask clienttask;
char *pbuff;
nRead(0, pbuff2, 512);
pbuff= (char*)nReceive(&clienttask,-1);
bcopy(pbuff, pbuff2, 512);
nReply(clienttask, 0);
} }
Esta soluciµn permite efectivamente superponer la lectura de un dispositivo (por el descriptor Unix nºmero 0). En efecto, una vez que el servidor BuffServ entrega un bloque de datos, el cliente (la aplicaciµn) procesa este bloque al mismo tiempo que el servidor ya està leyendo el prµximo bloque. Con suerte cuando el servidor vuelva a recibir un mensaje pidiendo un nuevo bloque, ese bloque ya estarà disponible.
Observe que esta soluciµn tambiÕn necesita interrupciones para poder implementarse, sµlo que esta vez la gestiµn de las interrupciones la realiza nSystem y no el programador de la aplicaciµn.