La segmentación es un esquema para implementar espacios de direcciones virtuales que se usaba en los primeros computadores de tiempo compartido. Pese a que hoy en día se encuentra en desuso, es interesante estudiar la segmentación por su simplicidad.
Como se vió en capítulos anteriores, cada proceso tiene su propio
espacio de direcciones virtuales, independiente del resto de los
procesos. Este espacio de direcciones virtuales se descompone en
cuatro áreas llamadas segmentos (ver figura ![]() ):
):

Figure: Segmentos del espacio de direcciones virtuales de un proceso.
En una organización segmentada, los segmentos residen en
un área contigua de la memoria real del computador. La figura
![]() muestra un posible estado de la memoria de un computador
con los distintos segmentos de varios procesos.
muestra un posible estado de la memoria de un computador
con los distintos segmentos de varios procesos.
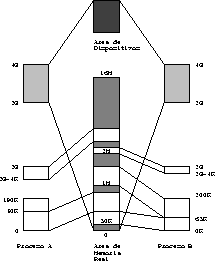
Figure: Ejemplo de ubicación de los segmentos de dos procesos en
la memoria real.
En la figura se observa que el segmento sistema contiene una imagen de toda la memoria real del computador. Esta es una técnica muy usada en la implementación de Unix.
Cuando un proceso accesa la memoria siempre suministra una dirección en su espacio de direcciones virtuales. El procesador debe traducir esa dirección a su posición efectiva en la memoria real del computador, es decir a su dirección real.
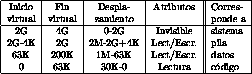
Para traducir las direcciones virtuales a direcciones reales, el procesador posee una tabla de segmentos con 4 filas. Cada una de estas filas describe uno de los 4 segmentos del programa en ejecución. Para cada segmento se indica:
La siguiente tabla muestra el contenido de la tabla de segmentos
para el proceso B de la figura ![]() .
.
En cada acceso a la memoria un proceso especifica una dirección virtual. El hardware del procesador traduce esta dirección virtual a una dirección real utilizando un conjunto de registros del procesador que almacenan la tabla de segmentos del proceso en ejecución.
Esta traducción se lleva a cabo de la siguiente forma: el hardware del procesador compara la dirección virtual especificada con la base y el límite de cada uno de los segmentos:
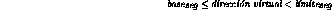
Si la dirección (virtual) cae dentro de uno de los segmentos entonces la dirección real se obtiene como:

Si la dirección no cae dentro de ninguno de los segmentos entonces se produce una interrupción. En Unix usualmente el proceso se aborta con un mensaje no muy explicativo que dice segmentation fault. El Hardware es capaz de realizar eficientemente esta traducción en a lo más un ciclo del reloj del microprocesador.
El núcleo del sistema operativo se encarga de colocar valores apropiados en la tabla de segmentos, y lo hace de tal forma que una dirección virtual jamás pertenece a dos segmentos. Sin embargo, es importante hacer notar que una misma dirección real sí puede pertenecer a dos segmentos asociados a procesos distintos.
Cada proceso tiene su propia tabla de segmentos almacenada en su descritor de proceso. El procesador mantiene solamente en registros internos la tabla de segmentos del proceso que está corriendo.
Cuando el núcleo decide efectuar un cambio de contexto, tiene que cambiar el espacio de direcciones virtuales del proceso saliente por el del proceso entrante. Para realizar este cambio, el núcleo carga la tabla de segmentos del procesador con la tabla de segmentos que se encuentra en el descriptor del proceso entrante.
El núcleo crea y destruye segmentos cuando se crea o termina un proceso o cuando se carga un nuevo binario (llamadas al sistema fork, exit y exec en Unix). El núcleo administra la memoria para estos segmentos en un área de la memoria denominada heap (montón). Esta estructura es similar al heap que utiliza malloc y free para administrar la memoria de un proceso.
Por conveniencia, el núcleo separa en dos heaps independientes la administración de la memoria para segmentos y la administración de la memoria para sus propias estructuras de datos como los descriptores de proceso, colas de scheduling, colas de E/S, etc.
En un heap hay trozos de memoria ocupada y trozos libres. Los trozos libres se enlazan en una lista que es recorrida, de acuerdo a alguna estrategia, cuando se solicita un nuevo trozo de memoria. Cuando se libera un trozo, se agrega a la lista. Esto hace que el heap se fragmente progresivamente, es decir se convierte en un sin número de trozos libres de pequen o taman o.
Para disminuir la fragmentación, al liberar un trozo se revisan los trozos adyacentes en el heap para ver si están libres. Si alguno de ellos está libre (o los dos), entonces los trozos se concatenan.
Las estrategias más conocidas para realizar la búsqueda en la lista de trozos libres son:
La estrategia best-fit tiene mal desempen o debido a que al partir el mejor trozo, el trozo que queda libre es demasiado pequen o. Será muy difícil que se pueda entregar ese pequen o trozo en un pedido subsecuente. Esto hace que la lista de trozos libres se va poblando de trozos demasiado pequen os que aumentan el costo de recorrer la lista.
De estas estrategias, first-fit es la que mejor funciona, pero organizando los trozos libres en una lista circular. La idea es evitar que se busque siempre a partir del mismo trozo, puesto que esto tiende a poblar el comienzo de la lista con trozos pequen os, alargando el tiempo de búsqueda. En esta variante, al hacer una búsqueda se memoriza el último trozo visitado en la lista circular. Al hacer una nueva búsqueda se comienza por el trozo siguiente al trozo memorizado.
A medida que se solicitan y liberan trozos de memoria en un heap, inevitablemente el heap se va fragmentando. La mejores estrategias como first-fit disminuyen la rapidez de fragmentación, pero no la evitan.
En un heap como el que utiliza malloc y free para administrar la memoria de un proceso, el problema de la fragmentación no tiene solución. Pero no se trata de un problema grave, puesto que un proceso Unix puede hacer crecer su espacio de datos, cuando ninguno de los trozos disponibles es del taman o solicitado.
En el núcleo sin embargo, cuando se trata de administrar la memoria
de segmentos, no existe la posibilidad de hacer crecer la memoria real
del computador. En cambio, el núcleo sí puede compactar el
heap dedicado a los segmentos (ver figura ![]() ). Para
ello basta desplazar los segmentos hasta que ocupen un área de
memoria contigua en el heap. Así la lista de trozos libres se reduce
a uno solo que contiene toda la memoria disponible en el heap.
). Para
ello basta desplazar los segmentos hasta que ocupen un área de
memoria contigua en el heap. Así la lista de trozos libres se reduce
a uno solo que contiene toda la memoria disponible en el heap.
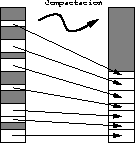
Figure: Compactación de la memoria real.
Al desplazar los segmentos de un proceso, las direcciones reales cambian, por lo que hay que modificar sus desplazamientos en la tabla de segmentos del proceso, pero las direcciones virtuales manejadas por el proceso no cambian. Esto significa que si un objeto ocupaba una dirección virtual cualquiera, después de desplazar los segmentos del proceso, su dirección virtual sigue siendo la misma, a pesar de que su dirección real cambió. Esto garantiza que los punteros que maneja el proceso continuarán apuntando a los mismos objetos.
Observe que la solución anterior no funciona para malloc y free, puesto que si se compacta el heap de un proceso Unix, sí se alteran las direcciones virtuales de los objetos. Después de compactar habría que entrar a corregir los punteros, lo que es muy difícil de hacer en C, puesto que ni siquiera se puede distinguir en la memoria un entero de un puntero.
Por esta misma razón es conveniente separar en el núcleo la administración de los segmentos del resto de las estructuras que pueda requerir el núcleo. Si se desplazan segmentos, es simple determinar cuales son los desplazamientos que hay que modificar en los descriptores de proceso. En cambio si se desplazan estructuras como colas o descritores de proceso, es muy complicado determinar desde que punteros son apuntadas estas estructuras.
Existen lenguajes de programación, como Lisp, Java y Smalltalk, que sí permiten implementar compactación. Estos lenguajes se implementan haciendo que cada objeto en el heap tenga una etiqueta que dice qué tipo de objeto es, por lo que un compactador puede determinar si el objeto tiene punteros que deberían corregirse. En todo caso, esta compactación es responsabilidad del proceso y no del núcleo, por la misma razón que en C malloc y free son parte del proceso.
La segmentación es un esquema simple para implementar espacios de direcciones virtuales, necesarios para poder garantizar protección entre procesos. A pesar de ser simple, permite implementar una serie de optimizaciones que permiten administrar mejor la memoria del computador que hasta el día de hoy es un recurso caro y por lo tanto escaso. A continuación se describen estas optimizaciones.
Cuando se va a crear un proceso, es imposible determinar a priori cuanta memoria se requiere para la pila. Si se otorga un segmento de pila muy pequen o, puede ocurrir un desborde de la pila. Por otro lado, si se otorga memoria en exceso se malgasta un recurso que podría dedicarse a otros segmentos.
En un sistema segmentado se puede se puede implementar un mecanismo de extensión de la pila en demanda. Este mecanismo consiste en asignar un segmento de pila pequen o y hacerlo crecer sólo cuando la pila se desborda. En efecto, el desborde de la pila ocurre cuando el puntero a la pila se decrementa más alla de la base del segmento de la pila. Cuando se intente realizar un acceso por debajo de este segmento se producirá una interrupción.
Esta interrupción hace que se ejecute una rutina de atención del núcleo que diagnostica el desborde de la pila. Entonces el núcleo puede solicitar un segmento más grande, copiar la antigua pila al nuevo segmento, liberar el antiguo segmento, modificar el desplazamiento del segmento pila en la tabla de segmento y retomar el proceso interrumpido en forma transparente, es decir sin que este se de cuenta de que desbordó su pila.
Con este mecanismo la memoria que necesita un proceso para su pila se asigna en demanda: la memoria se asigna a medida que el proceso la necesita.
La misma estrategia se puede usar para el segmento de datos. Sin embargo, en el caso de los datos, no es fácil distinguir un desborde del área de datos de la utilización de un puntero mal inicializado y que contiene basura.
Por esta razón en Unix ``se prefiere'' que un proceso solicite explícitamente la extensión de su segmento de datos usando la primitiva sbrk(size), en donde size es la cantidad de bytes a agregar a su segmento de datos. Observe sin embargo que el núcleo no está obligado a entregar exactamente esa cantidad. Por restricciones de implementación, el segmento podría crecer en más de lo que se solicita.
El mecanismo de implementación de esta extensión es esencialmente análogo al mecanismo de extensión de la pila.
En Unix la llamada al sistema fork crea un clone de un proceso. El clone es independiente del primero, pero se crea con una copia del código, de los datos y de la pila de proceso que hace fork. Ambos procesos comparten los mismos descriptores de archivo abiertos al momento de invocar fork. Sólo se diferencian por que el fork del proceso original retorna el identificador del proceso clone creado, mientras que el fork del clone retorna 0.
Esta llamada al sistema se implementa duplicando los segmentos de
datos y pila (ver figura ![]() ). El segmento de código
puede compartirse entre ambos procesos, pues normalmente un proceso no
debería modificar su código. Por lo tanto el segmento de código se
marca con el atributo de solo lectura. Si un proceso intenta
modificar sus datos, se producirá una interrupción que abortará el
proceso que falla.
). El segmento de código
puede compartirse entre ambos procesos, pues normalmente un proceso no
debería modificar su código. Por lo tanto el segmento de código se
marca con el atributo de solo lectura. Si un proceso intenta
modificar sus datos, se producirá una interrupción que abortará el
proceso que falla.
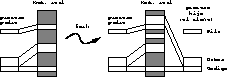
Figure: Implementación de fork.
Lamentablemente esta implementación es muy ineficiente para el uso típico de fork. Esta llamada se usa principalmente en el intérprete de comandos cuando el usuario ingresa un nuevo comando. El intérprete hace un fork para crear un clone de sí mismo, desde donde de inmediato llama a exec con el nombre del comando. El fork necesita duplicar los segmentos de datos y pila para crear el clone, pero estos segmentos serán inmediatamente destruidos con la llamada a exec que creará otros 3 segmentos.
Es importante hacer notar que los primeros micro-computadores basados en la Z80 y luego la 68000 no ofrecían hardware para segmentación, por lo que en ellos era imposible implementar fork, y por lo tanto Unix. La 8088 ofrece un esquema de segmentos de taman o fijo en 64 KB y sin protección, por lo que era posible implementar Unix en el PC original, siempre y cuando los usuarios se conformaran con procesos de no más de 3*64 KB (después de todo, los primeros Unix corrían en 64 KB) y aceptaran que procesos maliciosos pudiesen botar el sistema completo.
Si al crear un nuevo segmento, el núcleo no encuentra un trozo del taman o solicitado, el núcleo compacta el heap de segmentos. Si aún así no hay memoria suficiente, el núcleo puede llevar procesos completos al disco. Esto se denomina swapping de procesos.
Para llevar un proceso a disco, el núcleo escribe una copia al bit de cada segmento en una área denominada área de swap. Luego, la memoria ocupada por esos segmentos se libera para que pueda se ocupada para crear otros segmentos. El descriptor de proceso continúa en memoria real, pero se reemplaza el campo desplazamiento en la tabla de segmentos del proceso por una dirección que indica la ubicación de cada segmento en el área de swap. Además el proceso pasa a un estado especial que indica que se ubica en disco y por lo tanto no puede ejecutarse.
El scheduler de mediano plazo decide qué proceso se va a disco y qué proceso puede regresar a la memoria del computador, de acuerdo a alguna estrategia. Esta estrategia tiene que considerar que llevar un proceso a disco y traerlo cuesta al menos un segundo. Por esto no conviene llevar procesos a disco por poco tiempo. Se llevan por al menos 10 segundos.
En un sistema computacional hay muchos procesos demonios que pasan inactivos por largos períodos, como por ejemplo el spooler para la impresión si nadie imprime. Este tipo de procesos son los primeros candidatos para irse a disco.
Cuando todos los procesos en memoria están activos (sus períodos de espera son muy cortos), la medida de llevar procesos a disco es de emergencia. Si un proceso interactivo (un editor por ejemplo) se lleva a disco por 10 segundos, la pausa introducida será tan molesta para el usuario afectado que incluso llegará a temer una caída del sistema. Pero de todas formas, como alternativa es mejor que botar el sistema o destruir procesos al azar.
Los procesos ligeros comparten un mismo espacio de direcciones. El problema es que su pila se ubica en el heap del proceso y por ende es de taman o fijo e inextensible. Si un proceso ligero desborda su pila, se caen todos los procesos que comparten ese mismo espacio de direcciones.
En un esquema segmentado el núcleo puede ofrecer procesos
semi-ligeros en donde se comparte el área de código y de datos (como
los procesos ligeros) pero no se comparte la porción del espacio de
direcciones que corresponde a la pila (ver figura ![]() ).
).
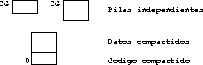
Figure: Procesos semi-ligeros.
Cada proceso semi-ligero tiene un segmento de pila asignado en el mismo rango de direcciones. Si un proceso semi-ligero desborda su pila, el núcleo puede extender automáticamente su pila, como si fuesen procesos pesados.
Los procesos semi-ligeros tienen dos inconvenientes con respecto a los procesos ligeros:
A pesar de que el cambio de contexto es caro, todavía se puede decir que son procesos ligeros debido a que se pueden comunicar eficientemente a través del envío de punteros al área de datos. Pero observe que es erróneo enviar punteros a variables locales a un proceso semi-ligero.
Apesar de que un sistema segmentado aporta soluciones y optimizaciones, persisten algunos problemas que solo se resuelven con paginamiento. Estos problemas son: