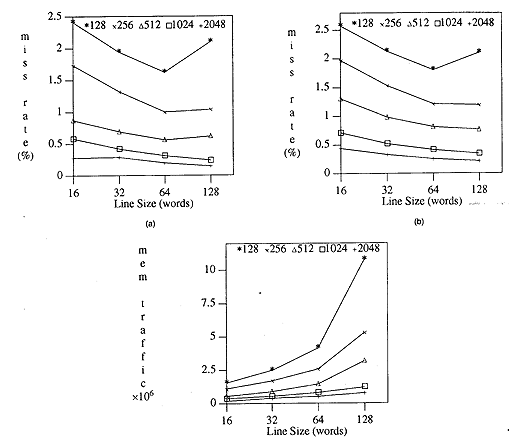
tasa de faltas para caché de mapeo directo (c) tráfico de memoria para caché LRU fully associative.
1.- Resumen
Existen dos mètodos basicos de prefetching
(pre-carga) de instrucciones en memoria: Fall-Through y Target. El método
Fall-Through está pensado para el acceso secuencial a las lineas,
teniéndose como parámetro la distancia desde el fin de la
línea actual, donde se inicia la pre-carga de la línea siguiente.
El método Target tambien funciona para accesos no secuenciales.
Se utiliza una tabla de predicción, y un aspecto clave es el algoritmo
de predicción utilizado por la tabla. Ambos algoritmos aumentan
el desempeño en forma notoria. Cuando son combinado en un algoritmo
híbrido, las mejoras son aún mayores. Una caché para
instrucciones utilizando un algoritmo híbrido de prefetching, presenta
un desempeño de dos a cuatro veces mejor que el de una caché
sin prefetching. Un buen método de prefetching no sólo debe
ser exacto, sino que además la precarga debe iniciarse lo suficientemente
temprano para dar tiempo a las instrucciones de retornar desde la memoria
principal. Para medir esto, se define una "eficiencia de prefetching",
que refleja el tiempo de carga desde memoria que es ahorrado gracias al
prefetching. Los mejores métodos de prefetching (en términos
de tasa de faltas) presentan además una gran eficiencia, ahorrando
aproximadamente un 90% de la pérdida de tiempo por línea
pre-cargada. Otro factor de desempeño interesante es el tráfico
de memoria, sin prefetching, las líneas más largas dan una
mejor tasa de aciertos; con prefetching en cambio, las lineas más
cortas muestran una tasa de aciertos mejor. Debido a que las lineas cortas
producen un menor tráfico de memoria, las cachés con prefetching
de mejor desempeño, presentan mucho menor tráfico de memoria
que las mejores memorias caché sin prefetching del mismo tamaño
2.- Introducción
Podemos derivar una expresión simple para medir la pérdida de desempeño debido a faltas en la caché. Medimos el sesempeño como el promedio de CPI (ciclos de reloj por instrucción). Sea MPI (faltas por instrucción), la medida de la tasa de faltas de la caché, y sea CPM (ciclos de reloj por falta) el costo por falta en la caché. Si CPIfalta es el promedio de de CPI pérdidos debido a la falta de una instrucción en la caché, entonces CPIfalta = CPM*MPI.
Los microprocesadores RISC tienden a mostrar menores costos por faltas en la caché, especialmente su utilizamos además una caché secundaria. De todas formas, el CPI de estos microprocesadores es también menor que en los superescalares tradicionales.
Sea CPI100 el desempeño
cuando hay acierto en la caché de instrucciones el 100% de las veces.
La pre-carga de líneas de instrucciones en caché puede reducir
la pérdida de desempeño, pero para ahorrar el costo total
de carga desde memoria (es decir, convertir una falta en un acierto), la
pre-carga debe se iniciada aproximadamente CPM/CPI100 instrucciones
antes.
3.- Estrategias de pre-carga
Existen dos técnicas básicas de pre-carga, cada una orientada a diferentes situaciones. El primer caso es cuando se cargan líneas de código consecutivas, como sería el caso de un código "lineal" (i.e. sin saltos), o código que presenta saltos con distancia pequeña. En este caso, utilizamos la técnica fall-through, en donde la linea consecutiva a la actual es cargada cierto tiempo antes que ésta termine. El otro tipo de pre-carga está orientado a saltos a líneas no consecutivas, como sería el caso de llamadas/retornos a procedimientos, o saltos de mayor longitud.Este tipo de estrategía es llamada target prefetching. Estos tipos de pre-carga no son mutuamente excluyentes, y se consideran estrategias híbridas que combinan ambos.
Método Fall-Through: Con el método fall-through, se invoca la pre-carga sólo cuando la secuencia de instrucciones falla dentro de una distancia específica desde el fin de una línea de instrucciones. Ésta distancia es medida en palabras , y la definimos como distancia fetchahead (algo así como distancia de carga anticipada). En general, mientras más corta es la distancia fetchahead hasta el final de la línea, más probable es que la línea sea usada. Por otro lado existe una posibilidad alta de que la instrucción no sea retornada desde memoria lo suficientemente pronto para evitar el costo de la falta.
Método Target: El método
fall-through no funciona bien cuando un programa presenta muchos y cortos
llamados a sub-rutinas, situación muy probable de ocurrir debido
a la utilización de lenguajes como C o lenguajes orientados a objetos,
que privilegian las llamadas a procedimientos. Para ayudar la pre-carga
en estos casos, se puede implementar una tabla de predicción de
línea siguiente. Por ejemplo, una tabla simple podría contener
un índice por cada líneade instrucción activa de la
caché. La entrada de la tabla contendría la dirección
de memoria de la linea que más recientemente siguió a la
linea activa. La unidad de carga de instrucciones puede comenzar una pre-carga
basada en el contenido de la tabla de predicción y el valor actual
del contador de programa.
4.- Pruebas
Para medir la efectividad de los métodos
de prefetching, se llevaron a cabo las siguientes pruebas:
|
|
| Desempeño de la caché sin prefetching:
(a) tasa de faltas para caché LRU fully associative, (b)
tasa de faltas para caché de mapeo directo (c) tráfico de memoria para caché LRU fully associative. |
 |
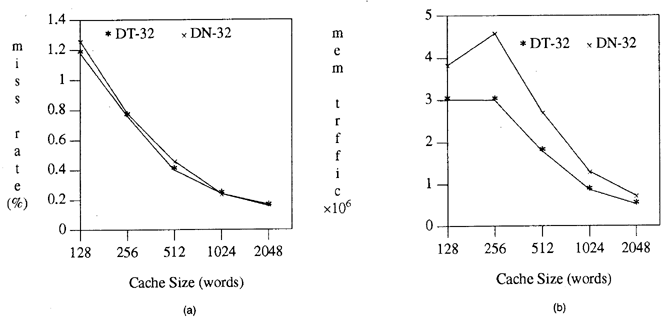
| Desempeño para prefetching con método
fall-through: con una distancia fetchahead igual a 8:
(a) tasa de faltas para caché full associative (b) tasa de faltas para caché con mapeo directo |
 |
| Mejor desempeño para el método Target: caché full associative (a) Tasa de Faltas (b) Tráfico de Memoria |
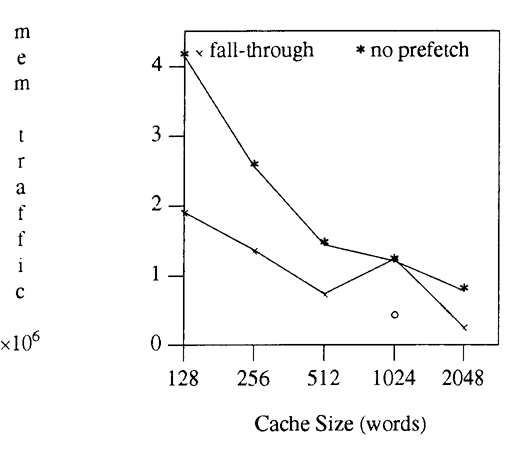 |
| Tráfico de Memoria para las cachés full associative de mejor rendimiento |
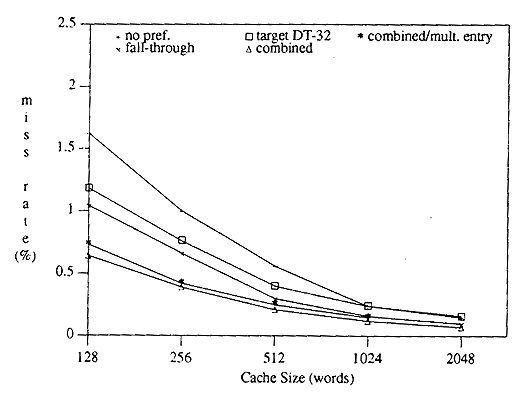 |
| Resumen de Desempeño para todos los métodos estudiados |
Bibliografía:
IEEE Transactions
on Computers, volumen 47, numero 5, mayo 1998