 |
Microprocesador UltraSPARC-IIi
|
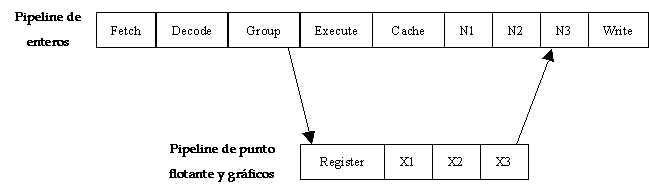
- Fetch.
Hasta cuatro instrucciones son leídas desde
la caché de instrucciones.
- Decode.
Después de la etapa fetch, las
instrucciones son predecodificadas y entonces
insertadas en el buffer de instrucciones.
- Group.
La tarea principal aquí es ensamblar un
grupo de hasta cuatro instrucciones y todas
ellas son despachadas en un solo ciclo. De
este grupo de cuatro, dos pueden ser de
enteros y dos pueden ser de punto flotante o
gráficas. El archivo de registro de enteros
es accesado en esta etapa.
- Execute.
Las dos ALU's de enteros procesan datos desde
el archivo de registro de enteros. Los
resultados son computados y, vía bypassing,
se ponen a disposición de otras
instrucciones dependientes en el siguiente
ciclo. En esta etapa también se calcula las
direcciones virtuales para las operaciones de
memoria, en paralelo con la computación de
la ALU. En cuanto a punto flotante y
gráficas, el archivo de registro de punto
flotante es accesado durante esta etapa.
- Cache.
La dirección virtual de las operaciones de
memoria calculadas en la etapa de execute
es enviada al tag de la RAM para determinar
si el acceso (load o store) es un acierto o
desacierto en el caché de datos. En forma
paralela, la dirección virtual es también
enviada a la unidad de administración de
memoria de datos (DMMU) para ser traducidas
en un dirección física. Las operaciones ALU
de la etapa execute generan códigos
de condiciones en esta etapa. Estos códigos
son enviados a la unidad de prefecth y
dispatch (PDU), el cual chequea si un salto
condicional en el grupo fue correctamente
predecido. En caso de una mala predicción,
las instrucciones en el pipeline son
limpiadas, y las instrucciones correctas son
traídas. Las instrucciones de punto flotante
y gráficas comienzan su ejecución durante
la etapa X1.
- N1. Un caché
de dato acertado o errado es determinado en
esta etapa. Si un load erra un caché de
dato, entra al load buffer. La dirección
física de un store es enviada al store
buffer en esta etapa.
- N2. El pipe de
enteros espera el pipe de punto flotante. La
mayoría de las instrucciones de punto
flotante y gráficas finalizan su ejecución
durante esta etapa. Después de N2, los datos
pueden ser desviados a otras etapas,
- N3. Los
bloqueos son resueltos en esta etapa.
- Write. En esta
etapa todos los resultados son escritos en
los archivos de registros de la arquitectura
(enteros y punto flotante). Una vez
completada esta etapa, las instrucciones son
consideradas terminadas.
|