Este esquema separa la implementación
del arreglo de tags y del arreglo de datos. Aunque guarda la memoria
de datos en un banco, organiza la memoria de tags en n bancos.
El sistema de la cache accesa el banco de datos secuencialmente, una palabra
a la vez, pero realiza el chequeo de tags en paralelo. Este desacoplamiento
hace posible despachar datos especulativamente hacia la CPU. No es necesaria
una operación multiplexada en los datos.
La cache multicolumna paralela usa una búsqueda
paralela, como se muestra en la figura 5.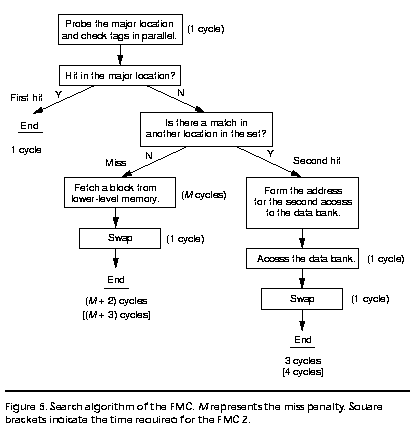 En una referencia, lee los datos en la posición principal desde
el banco de datos, de la misma forma que una cache directamente mapeada
lo hace, y los despacha a la CPU. Al mismo tiempo, lee y chequea n
tags en paralelo, usando un método similar al que realiza
una cache n-asociativa convencional.
Un acierto al primer intento ocurre si el tag para la posición
principal concuerda con el tag de la referencia. Si cualquiera de
los otros tags concuerda con el tag de referencia, un segundo
acierto ocurre, requiriendo otro ciclo para accesar el banco de datos nuevamente.
El sistema de la cache genera la dirección para este acceso usando
la salida del chequeo del tag. Si la referencia no se encuentra
en la cache, traera un nuevo bloque desde la memoria convencional.
Una operación de swap es necesaria
en caso de que la referencia falle o un segundo acierto.
En una referencia, lee los datos en la posición principal desde
el banco de datos, de la misma forma que una cache directamente mapeada
lo hace, y los despacha a la CPU. Al mismo tiempo, lee y chequea n
tags en paralelo, usando un método similar al que realiza
una cache n-asociativa convencional.
Un acierto al primer intento ocurre si el tag para la posición
principal concuerda con el tag de la referencia. Si cualquiera de
los otros tags concuerda con el tag de referencia, un segundo
acierto ocurre, requiriendo otro ciclo para accesar el banco de datos nuevamente.
El sistema de la cache genera la dirección para este acceso usando
la salida del chequeo del tag. Si la referencia no se encuentra
en la cache, traera un nuevo bloque desde la memoria convencional.
Una operación de swap es necesaria
en caso de que la referencia falle o un segundo acierto.
Esta estrategia genera la dirección para
el segundo acceso al banco de datos después del chequeo del tag
con una demora de una puerta OR. Esto aumenta un poco el tiempo de ciclo
en un procesador VLSI, que no implementa una ejecución optimista.
Si el procesador usa una ejecución optimista, el sistema de la cache
chequea los tags en el proximo ciclo. El hardware para generar la
dirección para el segundo acceso agrega una demora al ciclo de tiempo.
Para obtener el mismo ciclo de tiempo que en una cache directamente mapeada,
destinamos un ciclo completo para la generación de las direcciones
para el segundo acceso. En este caso, cuatro ciclos, y no tres, son necesarios
para un segundo acierto. La figura 5 muestra el tiempo requerido para este
caso entre paréntesis cuadrados.
Este esquema combina esencialmente la cache directamente
mapeada y la tradicional cache n-asociativa con la aplicación de
la técnica de bloque MRU multiple. Hereda de la cache directamente
mapeada el corto ciclo de tiempo y de la cache n-asociativa la búsqueda
paralela. En complejidad y costo de hardware, esta estrategia cae
entre la cache directamente mapeada y la cache asociativa tradicional.
Volver al índice