por Ricardo Baeza-Yates y Karma Peiró
El futuro se está creando a partir de la inteligencia artificial, ya que buena parte de las decisiones que tomamos en nuestras vidas están influenciadas por la acción de algoritmos de aprendizaje automático, que nos ahorran tiempo y facilitan la vida. Sin embargo, los sistemas automatizados tienen sesgos que pueden convertir nuestra cotidianidad en una burbuja de felicidad, mostrándonos sólo lo que nos gusta. Si no hacemos algo para cambiar esta situación, quizás un día descubriremos que —como el protagonista del Show de Truman— no sabremos distinguir la realidad de la ficción. ¿Estamos todavía a tiempo de cambiar nuestra sociedad?
¿Ciencia Ficción?
Imagínese que busca un empleo en una empresa de gran prestigio, con unas condiciones más que aceptables. La compañía a la cual aspira tiene muchos postulantes y no hace entrevistas personalizadas, ni tests. Considera que las habilidades que se destacan en currículos son, a menudo, exageradas. A cambio, pide la contraseña del correo electrónico del aspirante para que un algoritmo analice sus mensajes personales y genere un perfil del candidato. ¿Daría usted el consentimiento para que un sistema de inteligencia artificial (IA) revisara su buzón de correo, a cambio de optar al trabajo de su vida?
El ejemplo que acabamos de describir es real. La agencia de recolocación finlandesa Digital Minds [1] tiene una veintena de grandes corporaciones como clientes. Al recibir muchas demandas de posibles candidatos, necesita ahorrar tiempo y prefiere que un algoritmo haga la selección de manera automática.
Las innovaciones tecnológicas en el sector del reclutamiento de personal no son ninguna novedad: los primeros formularios test aparecieron en la década de los 40 del siglo pasado; en los 90, ya se usaban técnicas digitales y, ahora, es el turno de la inteligencia artificial. Digital Minds empezó en 2017 a usar algoritmos “inteligentes” para la selección de personal. También los utiliza para escudriñar el Facebook y Twitter personal de los aspirantes. El sistema analiza la actividad del candidato y cómo reacciona. Con los resultados se puede saber si una persona es introvertida o si se expresa correctamente, además de otros aspectos de la personalidad.
 La IA es buena para establecer patrones y relaciones ingentes, así como para agilizar procesos y operaciones con datos masivos (big data). Sin embargo, el problema es que los algoritmos no son neutros. Tampoco los datos que sirven para entrenarlos, porque tienen sesgos. Y esto no es nada nuevo.
La IA es buena para establecer patrones y relaciones ingentes, así como para agilizar procesos y operaciones con datos masivos (big data). Sin embargo, el problema es que los algoritmos no son neutros. Tampoco los datos que sirven para entrenarlos, porque tienen sesgos. Y esto no es nada nuevo.
En los años 80, el vicedecano de la Escuela de Medicina del Hospital St. George de Londres, Geoffrey Franglen, tenía que evaluar cada año unas 2.500 solicitudes. Para automatizar el proceso escribió un algoritmo que lo ayudara a revisar, basándose en el comportamiento de evaluación de solicitudes anteriores [2]. Así, aquel año, los candidatos se sometieron a una doble prueba antes de ser admitidos: la del algoritmo, y la de los profesores. Franglen se dio cuenta de que las calificaciones coincidían en un 90-95%, lo que demostraba que el algoritmo podía reemplazar los humanos en esta fase tan tediosa. Pero en 1984, la dirección del centro mostró su preocupación por la poca diversidad de los candidatos. Y la Comisión para la Igualdad Racial del Reino Unido denunció a la Escuela por discriminación xenófoba y de género. Cada año se habían dejado fuera de la selección unas 60 persones que el algoritmo discriminaba porque tenían apellidos no europeos o porque eran mujeres.
Pero no todos los sesgos son perjudiciales. Por ejemplo, que haya más enfermeras que enfermeros puede ser positivo por cualidades empáticas en el trato de los pacientes. Pero que los políticos sean mayoría no lo es tanto, porque un punto de vista de la población (el femenino) no está igualmente representado. Los resultados de los algoritmos pueden dar lugar a discriminaciones por razones de género, raza, edad o clase social, por mencionar los más importantes. La pregunta sería… ¿por qué se aplican?
Cuestión de justicia
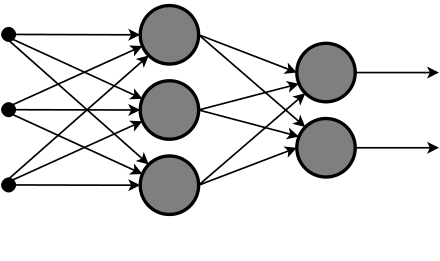 La mayoría de los algoritmos que operan hoy están basados en lo que se conoce como aprendizaje profundo (deep learning): una técnica de procesamiento de datos basada en redes neuronales artificiales que funcionan por capas y que permiten aprender. Está inspirado en el funcionamiento básico de las neuronas del cerebro. Esta técnica existe hace más de 50 años, pero es ahora que tenemos el suficiente volumen de datos y la capacidad de computación para aplicarla en una multitud de casos prácticos.
La mayoría de los algoritmos que operan hoy están basados en lo que se conoce como aprendizaje profundo (deep learning): una técnica de procesamiento de datos basada en redes neuronales artificiales que funcionan por capas y que permiten aprender. Está inspirado en el funcionamiento básico de las neuronas del cerebro. Esta técnica existe hace más de 50 años, pero es ahora que tenemos el suficiente volumen de datos y la capacidad de computación para aplicarla en una multitud de casos prácticos.
Actualmente, muchos de los dispositivos que reconocen las huellas digitales, la voz, la cara, el iris, usan estas redes neuronales. Este reconocimiento se consigue introduciendo al sistema millones de elementos etiquetados que entrenan la máquina. Pero volviendo a nuestra pregunta: Si se sabe que los algoritmos tienen sesgos ¿por qué los usamos? Una respuesta podría ser que el beneficio o acierto de los resultados es considerablemente superior (más de un 90%) que el perjuicio o error. ¿Es esto justo para los que salen perjudicados? En este punto se podría comenzar una larga discusión sobre qué es o no es justo en la vida.
Primero, resulta muy difícil ser justo con todo el mundo. Un algoritmo puede serlo con un colectivo de mujeres pero discriminar a un hombre. En este sentido, el investigador Andrew Selbst [3] —del Data & Society Research Institute [4]— explica que decidir la discriminación en inteligencia artificial es muy complicado. “Es un proceso en constante evolución, igual que cualquier aspecto de la sociedad”.
Los sesgos son parecidos a los prejuicios: todos los tenemos, en menor o mayor grado. Muchos los heredamos de nuestro entorno social o familiar sin darnos cuenta. El sesgo más grande es creer que no tenemos ningún prejuicio. Pero… atención: si los sesgos no se corrigen, hay el riesgo de habitar un futuro donde cada vez sea más difícil el progreso social porque los prejuicios se perpetúen.
¿Como estar seguros, pues, que todos los datos que introducimos al sistema representan el universo que queremos predecir? Éste es uno de los principales dilemas de hoy en día. No podemos estar seguros. Para ser rigurosos también hay que decir que los algoritmos bien diseñados —a pesar de tener sesgos— son justos de acuerdo con los parámetros que se les han dado. A diferencia de los humanos -que pueden variar su decisión en función de un estado de ánimo o del estado de cansancio físico y mental-, los algoritmos siempre funcionan igual.
Humans decisions and machine predictions [5] es un interesante estudio estadounidense que demuestra cómo al decidir otorgar una fianza en un proceso judicial, el aprendizaje automático puede funcionar mejor que las decisiones de un juez, incluso cuando podrían discriminar a los negros o hispanos. Los resultados dieron que, cuando era muy evidente que la persona tenía muy bajo riesgo a reincidir, tanto los jueces como el algoritmo coincidían en liberarlo bajo fianza antes del juicio. Pero el algoritmo era más justo que el juez al predecir casos de mayor riesgo de reincidencia de crimen. Y esto es porque las máquinas son sistemáticas, incluso cuando son tan o incluso más racistas que los jueces.
¿Cuántos tipos de sesgos existen?
Hay tres tipos de sesgos clásicos: el estadístico, el cultural y el cognitivo. El estadístico procede de cómo obtenemos los datos, de errores de medida o similares. Por ejemplo, si la policía está presente en algunos barrios más que en otros, no será extraño que la tasa de criminalidad sea más alta donde tenga mayor presencia (o en otras palabras, mediremos más donde está uno de los instrumentos de medida). El sesgo cultural es aquel que deriva de la sociedad, del lenguaje que hablamos o de todo lo que hemos aprendido a lo largo de la vida. Los estereotipos de las personas de un país son un ejemplo claro. Por último, el sesgo cognitivo es aquel que nos identifica y que depende de nuestra personalidad, de nuestros gustos y miedos. Por ejemplo, si leemos una noticia que está alineada con lo que pensamos, nuestra tendencia será validarla aunque sea falsa. Esta última desviación se conoce como ‘sesgo de confirmación’. Buena parte de las noticias falsas (fake news) se alimentan de este razonamiento para difundirse más rápidamente. Por este motivo, si no nos cuestionamos lo que leemos o vemos, corremos el riesgo de avanzar hacia una involución humana.
El historiador Yuval Noah Harari alerta en su último libro 21 Lecciones para el siglo XXI [6] que “con la tecnología actual, es muy fácil manipular a las masas”. Y si seguimos lo que piensa la mayoría de la gente, ¿qué pasa cuando moralmente la masa esté equivocada?
Y todavía más sesgos…
Las máquinas pueden trabajar con muchos más sesgos, todos derivados de los principales que acabamos de mencionar. Los datos que usa un algoritmo tienen rasgos culturales y cognitivos de sus usuarios. Y los datos usados tienen sesgos estadísticos. De igual manera, el diseño de estos algoritmos pueden reflejar aspectos de sus creadores.
Encontramos el sesgo de orden (ranking) cuando buscamos en la Web, puesto que los personas tienden a hacer clics en las primeras posiciones, y el buscador podría interpretar que estas respuestas son mejores que las siguientes. Por esta razón, los buscadores adaptan los números de clics para mitigar el efecto del orden de los resultados.
Los sesgos de presentación los encontramos en las recomendaciones en el ámbito del comercio electrónico. Solo aquello que se muestra al usuario podrá tener clics. Todo lo que no salga en la página de resultados no puede ser escogida. Es un círculo vicioso, como el del huevo y la gallina. Y la única manera de romperlo es mostrar el universo total de resultados.
 Esto tiene que ver con lo que se conoce como “filtro burbuja [7]: el sistema muestra únicamente aquello que te gusta. Como se basa en las acciones del pasado, no es posible ver aquello que se desconoce. En caso de continuar así, llegará un momento que nos podemos sentir como el personaje principal de la película El show de Truman, que un buen día se da cuenta que todo su mundo es un engaño, y que se ha perdido saber qué hay más allá del horizonte. El filtro burbuja no es solo para los usuarios, también lo es para el software: las personas solo elegirán los elementos que les han presentado en primer lugar. Así que el software también está en una burbuja creada por él mismo.
Esto tiene que ver con lo que se conoce como “filtro burbuja [7]: el sistema muestra únicamente aquello que te gusta. Como se basa en las acciones del pasado, no es posible ver aquello que se desconoce. En caso de continuar así, llegará un momento que nos podemos sentir como el personaje principal de la película El show de Truman, que un buen día se da cuenta que todo su mundo es un engaño, y que se ha perdido saber qué hay más allá del horizonte. El filtro burbuja no es solo para los usuarios, también lo es para el software: las personas solo elegirán los elementos que les han presentado en primer lugar. Así que el software también está en una burbuja creada por él mismo.
El problema es que las empresas optimizan los costes de estos sistemas automatizados a corto plazo y lo que se tendría que hacer es invertir en conocer mejor el mundo. En esta lógica, si una red social sólo muestra noticias falsas, desaparecerá. Si un sitio de comercio digital sólo destaca los productos vendidos a corto plazo, desaparecerá porque habrá otra empresa que lo hará mejor. Pero entretanto también estará destruyendo muchos negocios que no fueron mostrados, por el sesgo de presentación. Las multinacionales tecnológicas ya hace tiempo que estudian el sesgo y la justicia de los resultados porque afecta gravemente a la sociedad.
El sesgo de género lo vemos cuando buscamos en redes sociales directivos de empresas. Los primeros resultados serán perfiles masculinos, porque hay menos mujeres en posiciones directivas. Una posible solución sería introducir en el sistema datos nuevos para que en los veinte primeros resultados hubiera la misma proporción de género. Pero antes habría que decidir para cada profesión cuál tendría que ser la proporción correcta. Porque por distintas razones—por ejemplo físicas— siempre habrá mayoría de hombres en ciertas profesiones. Y otras—por ejemplo empatía— estarán dominadas por mujeres.
¡Existen también sesgos de segundo orden! Un ejemplo es cuando una persona usa la información de los primeros resultados de un buscador y la reutiliza para escribir nuevos artículos. Una investigación publicada en 2008 sobre la genealogía de páginas web demostró que el 35% de las páginas tenía contenido de otras páginas ya existentes [8]. Este problema se agrava con el funcionamiento actual de los buscadores, porqué cuando son recolectadas están ya sesgadas y el buscador cree que son aún más relevantes.
Sesgos para dar y regalar
Hay decenas de sesgos culturales y aún más cognitivos. Se han llegado a clasificar hasta un centenar, pero serían unos 25 los más importantes, empezando por el de ‘confirmación’, que ya hemos mencionado. En el artículo The Ultimate List of Cognitive Biases: Why Humans Make Irrational Decisions [9] se enumeran 49 sesgos cognitivos. Y en otro de la revista Forbes, se mencionan 8 como los principales para el marketing [10].
Todos estos sesgos forman un círculo vicioso, particularmente en la Web [11]. En todo caso, los sesgos más peligrosos son los cognitivos porque están arraigados a cada persona. La única manera de resolverlos es cambiar a cada persona, pero esa parece una proeza imposible. Habrá que dar la razón a Harari cuando dice que es muy fácil manipular a las personas y muy complicado eliminar los sesgos.

¿Realidad o ficción?
Como decíamos, sesgos hay para dar y regalar. Sobre todo culturales y cognitivos. Siendo conscientes de esta situación, ¿cómo saber qué es realidad y qué es ficción? Si colectiva e individualmente hacemos un esfuerzo continuado, todavía estamos a tiempo de construir un futuro más diverso y justo.
Karen Hao -periodista especializada en inteligencia artificial de MIT Technology Review- escribió recientemente el artículo This is how AI bias really happens, dedicado a detectar por fases los problemas que nos plantean los sesgos de los algoritmos. Con la intención de dar un paso más a su aportación, proponemos posibles soluciones para minimizar la discriminación de los algoritmos.
1. Situar el problema lo mejor posible
Lo primero que hacen los informáticos cuando crean un modelo de aprendizaje automático es decidir qué quieren conseguir. Una compañía de tarjetas de crédito puede predecir la solvencia crediticia de un cliente, pero esto es un concepto ambiguo. Para calcularlo, quizás se tienen en cuenta variables comerciales que no responden a parámetros imparciales o que discriminan. Una manera de evitar este sesgo sería invitar a expertos externos, verificar las hipótesis, consultar posibles afectados, etc.
2. Recolectar mejores datos
Hay dos motivos por los cuales los datos de entrenamiento de un algoritmo tienen sesgo: porque la información recopilada no es representativa de la realidad o porque reflejan prejuicios existentes en la sociedad, comunidad o grupo. Por ejemplo, si usa más fotos de caras blancas que de negras; o si en un proceso de selección de trabajo se descartan mujeres. Al sistema de Amazon le pasó esto: como históricamente siempre se habían contratado más trabajadores que trabajadoras, el sistema las excluía. Una solución sería recolectar una muestra, analizarla y decidir qué tipo de datos recoger más o menos.
3. Extraer mejores atributos
Una etapa importante consiste en definir atributos (o rasgos) para que el algoritmo los tenga en cuenta. Por ejemplo, en el caso de la solvencia crediticia podría ser la edad, el ingreso o la cantidad de préstamos pagados por el cliente. Para el algoritmo sexista de Amazon, un atributo sería el género, los estudios o los años de experiencia del candidato. “Que atributos se usan o ignoran puede influir significativamente en la calidad de la predicción de un algoritmo. Sin embargo, mientras que el impacto en la calidad es fácil de medir, el impacto en los sesgos del algoritmo no lo es”, explica la especialista Karen Hao.
Estas tres soluciones están pensadas para los técnicos que crean algoritmos, pero individualmente también podemos contribuir a eliminar los sesgos de los algoritmos. ¿Cómo? Potenciando lo que se conoce como ‘filtrado colaborativo’. Es decir, podemos agregar personas y productos nuevos que no son afines a nosotros o que nunca consumiríamos, pero que nos pueden aportar visiones diferentes. Por ejemplo, en Twitter, Instagram o Facebook podríamos seguir a gente que no nos interesa o con la que no compartimos ideologías. Los sistemas de inteligencia artificial se nutrirían también de otros contenidos y mostrarían nuevas realidades.
4. Devolver el control al usuario
Si el usuario tiene más control sobre la interacción con el sistema, puede ayudarlo a ser menos sesgado. Al mismo tiempo, el sistema puede contribuir al hecho que la persona se dé cuenta de sus propios sesgos cognitivos. En este sentido, sería ideal que las redes sociales o los buscadores -cuando la persona elige un resultado- dieran una valoración de si escoge como la mayoría o es una rara avis. También se podría mostrar más de una opinión y diferentes puntos de vista. Y, de paso, nos ayudaría a entender mejor el contexto en que cada cual se mueve.
Ahora que tenemos detectados los sesgos y sabemos cómo se producen, ¿podemos corregir la realidad y dejar de sufrir? Todavía no, porque las desviaciones no siempre son obvias. Y cuando se descubren, resulta muy complicado averiguar donde está el sesgo. Ante esto, nuestra propuesta es hacer muchas muestras y analizarlas, antes de poner el algoritmo en práctica. Y analizar los resultados para ver si son parecidos o heterogéneos. En otros casos, habrá que determinar mejor el contexto social correcto.
No todo es tan fácil como parece
Desde el punto de vista individual todavía queda otra cuestión a resolver: ¿qué pasa si no somos conscientes que un algoritmo está tomando una decisión por nosotros? Entonces, ni siquiera puedes discutir si es justo o no. Suponga que sabemos que el banco, empresa, hospital o servicio público han decidido a partir de un algoritmo denegarnos un crédito, dejarnos sin trabajo o ponernos en una lista de espera para una operación quirúrgica urgente. ¿Hay alguna legislación que nos de el derecho de saber por qué el algoritmo nos ha discriminado?

El informe Automatizando la sociedad: Inventario de los algoritmos de toma de decisiones automáticas en la UE [12] fue elaborado por un grupo de expertos, y coordinado por las organizaciones AlgorithmWatch y Bertelsmann Stiftung. En él se evalúan una amplia variedad de usos de procesos automatizados y se pone énfasis en “las brechas reglamentarias”, a la vez que sugiere una mejor coordinación europea sobre el tema. En concreto, se menciona que la Ley europea de Protección de Datos (GDPR, en sus siglas en inglés) muestra deficiencias para abordar los desafíos planteados por los sistemas de decisión automática inteligentes.
El artículo 22 de la GDPR define tres condiciones: 1) Cuando la toma de decisiones sea completamente automatizada, 2) cuando se basa en datos personales y 3) cuando las decisiones tienen consecuencias legales significativas en personas. Pero los expertos señalan que en la ley no queda clara la definición de ‘decisión’ ni en qué circunstancias y qué ‘efectos legales’ tienen que darse para que se aplique la prohibición de uso de un algoritmo de decisión automática. Por lo tanto, críticos y defensores de los derechos ven poco margen de maniobra cuando se trata de proteger los derechos sociales.
Por otro lado, parece que hay cierta preocupación por el uso que se pueda hacer de la aplicación de ciertas tecnologías, incluso en los Estados Unidos donde siempre han estado menos preocupados por la privacidad, o donde sus leyes han sido más laxas. Este mes de mayo se ha presentado un proyecto de ley (todavía por validar) para que el ayuntamiento de San Francisco prohíba la vigilancia facial, además de los lectores automáticos de matrículas, el software predictivo o las torres de vigilancia de teléfonos móviles, entre otros. En caso de aprobarse sería el primer municipio estadounidense en aplicar una medida de este tipo. Lo más interesante de esta decisión es que San Francisco no usa el reconocimiento facial, así que sólo sentaría jurisprudencia.
En el ámbito internacional se tiene que mencionar también que la Organización para la Cooperación y Desarrollo Económico (OCDE) subscribió -a finales de mayo- los Principios sobre la IA, a la que se adhirieron los 36 países miembros además de Argentina, Brasil, Colombia, Costa Rica, Perú y Rumanía [13]. Estos principios mencionan que la IA tiene que respetar los derechos humanos, la diversidad y estar encabezada por la transparencia y una divulgación responsable. Igualmente mencionan que los sistemas tienen que ser robustos y seguros, a la vez que hace responsables a las organizaciones que las gestionan de su funcionamiento. Su objetivo es guiar a los gobiernos, organizaciones y ciudadanos para que el diseño y la gestión de la IA prioricen los intereses de las personas.
Igualmente hay que mencionar que la Unión Europea presentó a finales del 2018 una guía ética sobre la ![]() [14], donde parte del concepto ‘confianza’ para poner sobre la mesa lo que nos jugamos en este proceso tecnológico. “La IA confiable está basada en tres pilares, que se tienen que cumplir a lo largo de todo el ciclo de vida del sistema: 1. Tiene que ser legal, según las leyes aplicables; 2. Tiene que ser ético, garantizando los principios y valores éticos; y 3. Tiene que ser robusto, ya que aún con buenas intenciones los sistemas de inteligencia artificial pueden causar daños involuntarios”.
[14], donde parte del concepto ‘confianza’ para poner sobre la mesa lo que nos jugamos en este proceso tecnológico. “La IA confiable está basada en tres pilares, que se tienen que cumplir a lo largo de todo el ciclo de vida del sistema: 1. Tiene que ser legal, según las leyes aplicables; 2. Tiene que ser ético, garantizando los principios y valores éticos; y 3. Tiene que ser robusto, ya que aún con buenas intenciones los sistemas de inteligencia artificial pueden causar daños involuntarios”.
Todo lo anterior es un voto a la esperanza, en el sentido del respeto ético con el desarrollo de la IA porque van en la misma sintonía.
Conservar la privacidad
¿Recuerdan el primer ejemplo que encabezaba la primera parte de este artículo? El de la compañía finlandesa que recluta su personal a partir de escrutar tu correo electrónico. ¿Si le asegurasen que no almacena ningún dato para realizar la prueba de accesibilidad, accedería? ¿Y si añadimos que el proceso está controlado por un inspector de protección de datos? ¿Quizás sí, verdad? Sin embargo, el sistema plantea un problema ético y de exclusión: ¿qué pasa con todos aquellos que igualmente rechacen el acceso a sus cuentas, ya no optan al trabajo? ¿Y los que no tienen correo electrónico?
Como conclusión, solo podemos añadir que tener conciencia de la existencia de los sesgos de los algoritmos es el principal paso para cambiar la situación actual. Y cuando decimos ‘tener conciencia’ queremos decir hacerse cuestionamientos de los valores y prejuicios que nos mueven cada día. Porque muchas personas aseguran no ser racistas, pero a la vez no se dan cuenta de los comportamientos discriminatorios que tienen hacia un colectivo de otra comunidad.
 Tal como se menciona en el estudio Discriminating systems. Gender, Race and Power [15], nos encontramos en un momento muy crítico para que la industria de la inteligencia artificial decida qué hará con los sesgos y sus consecuencias. Los sistemas de AI ya están integrados plenamente en la sociedad e influyen de manera muy predominante en los aspectos más íntimos de nuestras vidas: en la salud, la seguridad, educación y oportunidades laborales, por poner sólo unos ejemplos. “Es imprescindible, pues, evaluar las formas cómo estos sistemas inteligentes tratan la diferencia. Es decir, a aquellas personas que por su género, raza, edad, estado social o lugar de nacimiento no forman parte de la mayoría que se está tratando”.
Tal como se menciona en el estudio Discriminating systems. Gender, Race and Power [15], nos encontramos en un momento muy crítico para que la industria de la inteligencia artificial decida qué hará con los sesgos y sus consecuencias. Los sistemas de AI ya están integrados plenamente en la sociedad e influyen de manera muy predominante en los aspectos más íntimos de nuestras vidas: en la salud, la seguridad, educación y oportunidades laborales, por poner sólo unos ejemplos. “Es imprescindible, pues, evaluar las formas cómo estos sistemas inteligentes tratan la diferencia. Es decir, a aquellas personas que por su género, raza, edad, estado social o lugar de nacimiento no forman parte de la mayoría que se está tratando”.
Finalmente, respondiendo a la pregunta inicial de este artículo, sobre si es posible acabar con los sesgos de los algoritmos se tiene que decir —sin ánimo de desmoralizar a nadie— que no, pues son parte de nuestra vida. Pero sí que podemos ser más conscientes de lo que suponen e intentar reducirlos usando soluciones como las mencionadas. Después de todo lo expuesto, la mejor propuesta es tener gente más formada y educada, con una buena base para tomar decisiones. De lo contrario, viviremos en burbujas cognitivas hechas a nuestra medida. Y perderemos de vista la realidad.
———————————————————
[1] Digital Minds, empresa finlandesa: https://digitalminds.fi/
[2] Untold History of AI: Algorithmic Bias Was Born in the 1980s: https://spectrum.ieee.org/tech-talk/tech-history/dawn-of-electronics/untold-history-of-ai-the-birth-of-machine-bias
[3] Andrew Selbst: https://andrewselbst.com/
[4] Data & Society Research Institute: https://datasociety.net
[5] Jon Kleinberg et al., Humans decisions and machine predictions: https://www.nber.org/papers/w23180.pdf
[6] Yuval Noah Harari, 21 lecciones para el siglo XXI, 2018 (Capítulo3): https://www.ynharari.com/
[7] Eli Pariser. The Filter Bubble: What the Internet Is Hiding from You, Penguin Press, New York, 2011.
[8] Ricardo Baeza-Yates, Álvaro R. Pereira Jr., Nivio Ziviani. Genealogical trees on the Web: a search engine user perspective. In WWW 2008, Pekin, China, Abril 2008, 367-376.
[9] Tomer Hochma, The Ultimate List of Cognitive Biases: Why Humans Make Irrational Decisions en Human How: https://humanhow.com/en/list-of-cognitive-biases-with-examples/
[10] Jayson DeMers. 8 Cognitive Biases That Will Drive The Future of Marketing en Forbes: https://www.forbes.com/sites/jaysondemers/2016/12/16/8-cognitive-biases-that-will-drive-the-future-of-marketing/
[11] Ricardo Baeza-Yates. Bias on the Web. Communications of ACM 61(6), pp. 54–61, 2018.
[12] Karma Peiró (Capítulo: España). Automatizando la sociedad: sesgos de los algoritmos de decisión automática, de Algorithm Watch y Bertelsman Stiftung: https://algorithmwatch.org/en/automating-society/
[13] 42 países adoptan los principios de la ‘OCDE sobre la Inteligencia Artificial: http://www.oecd.org/centrodemexico/medios/cuarentaydospaisesadoptanlosprincipiosdelaocdesobreinteligenciaartificial.htm
[14] Guía ética sobre la Inteligencia Artificial Confiable: https://ec.europa.eu/digital-single-market/en/news/have-your-say-european-expert-group-seeks-feedback-draft-ethics-guidelines-trustworthy
[15] Sarah Myers West, Meredith Whittaker y Kate Crawford. Discriminating systems: Gender, Race and Power in AI, AI Now Institute, New York University, Google Open Research y Microsoft Research. Abril 2019: https://ainowinstitute.org/discriminatingsystems.pdf