Este método garantiza que no se necesitan más de dos accesos de disco para realizar una búsqueda. Los registros almacenados se guardan en páginas que cuando se llenan se dividen en dos nuevas páginas, las que son indexadas de acuerdo al valor de los bits de mayor precedencia de las claves de búsqueda y la profundidad del descenso.
Una clave (valor entero, string, u otra) se puede codificar ("escribir") en binario, con lo cual tenemos una clave binaria, ejemplo:
|
|
|
|
|
|
|
|
|
El objetivo es mantener en memoria, o en una pagina, el conjunto de nodos que al menos contienen la clave de búsqueda y un puntero a la página donde esta el dato, y varias páginas que contengan los datos buscados. Los procesamientos de las páginas en disco y en memoria "no cuentan" para el tiempo, ya que se supone que serán en pocas oportunidades, queremos minimizar los accesos!!.
El ejemplo que se mostrará fue tomado de Algorithms de Robert Sedgewick, páginas 231 a 235.
Concideremos la inserción de las claves: E X T E R N A L S E A R C H I N G E X A M P L E, (el libro esta escrito en inglés :) ), y la codificación en binario de las letras, partiendo con la A = 1. También consideremos que en una página de disco se contiene la información de hasta 4 claves.
Por simplicidad, en el disco 1 guardamos la estructura de las claves, y en el disco 2 las páginas, numeradas desde 0 en adelante.
Inicialmente la estructura parte así:
| Disco 1: | Sin claves |
| Disco 2: | Sin datos |
Insertando las primeras cuatro letras (la capacidad es 4 así
que forzosamente todas caben en la misma página)
|
clave enpleada para discriminar |
clave |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Disco 1: | 2.0 |
| Disco 2: | E E T X |
OJO1: El 2.0 significa disco 2, página 0.
OJO2: Noten que la inserción es ordenada !!, esto hace más
fácil dividir las páginas
Al insertar la R = 10010 superamos la capacidad de la página, luego hay que dividirla de acuerdo al criterio "valor de los bits de mayor precedencia de las claves de búsqueda y la profundidad del descenso".
la profunidad actual es 0, luego dividimos por el primer bit de las
claves (bit 0)
|
clave enpleada para discriminar |
clave |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Con esto la estructura se ve así:
| Disco 1: | 2.0 | 2.1 |
| Disco 2: | E E | R T X |
Ahora se puede agregar la N = 01110 y la A = 00001, y cuando agreguemos
la L = 01100 hay que hacer la siguiente división
|
clave enpleada para discriminar |
clave |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Con esto la estructura se ve así:
| Disco 1: | 2.0 | 2.1 | 2.2 |
| Disco 2: | A E E | L N | R T X |
Agregamos S = 10011, E = 00101, y para agregar la A = 00001 hacemos
otra división.
|
clave enpleada para discriminar |
clave |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Con esto la estructura se ve así:
| Disco 1: | 2.0 | 2.1 | 2.2 | 2.3 |
| Disco 2: | A A | E E E | L N | R S T X |
Para hacer el cuento corto, agregamos lo que falta: R C H I N G
E X A M P L E. La estructura se ve:
| Disco 1: | 2.0 | 2.1 | 2.2 | 2.3 | 2.4 | 2.5 | 2.6 | 2.7 | 2.8 |
| Disco 2: | A A A C | E E E E | G | H I | L L M | N N | P R R S | T | X X |
La estructura de búsqueda se puede guardar como un arreglo de punteros o como un árbol digital, analicemos hasta la iteración anterior:
Guardada como un arreglo de punteros, se debe considerar lo siguiente:
|
clave enpleada para discriminar |
entero |
clave |
|
de disco |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Noten la diferencia, la porción de la clave empleada para discriminar
es del tamaño de la mayor, en este caso 3 bits, con lo cual tomando
la columna Número entero y Página de disco se construye el
siguiente arreglo:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Lo malo de esto es que se generan claves ficticias (cada vez que alguna clave crece se duplica el tamaño del arreglo, todas las claves crecen y aparecen claves que no existen :( )
La opción árbol digital es más simpática, sólo en las hojas se guardan los punteros, en los nodos interiores el valor del puntero es NULL:
La estructura del nodo es
struct nodo {
struct nodo * hijo0;
struct nodo * hijo1;
hojaDisco * puntero;
}
Con lo cual se ve el siguiente árbol
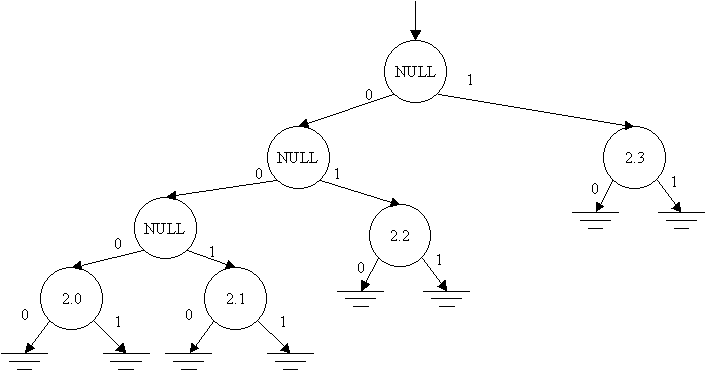
Esto es mejor puesto que no pierde espacio, pero lo malo es que es más
complicado de implementar.