El algoritmo para inducir un árbol de decisiones es el conocido ID3 [20]. Lo que se pretende con el algoritmo, es llegar a un árbol que describe a los datos entrantes. Como ejemplo se muestra el siguiente árbol de decisión:
A partir de uno de estos gráficos, es muy sencillo ver las reglas asociadas, como por ejemplo:
En términos algebraicos esto sería
SOLEADO Ù ØHUMEDO Þ SÍ
LLUVIOSOÙ (VIENTO = BAJO) Þ NO
El problema principal es como se puede llegar de un conjunto de datos, a un árbol de decisión. El árbol en la ilustración 10 es obtenido desde la tabla siguiente
|
Day |
Outlook |
Temp |
Humidity |
Wind |
PlayTennis |
|
1 |
Sunny |
Hot |
High |
Weak |
No |
|
2 |
Sunny |
Hot |
High |
Strong |
No |
|
3 |
Overcast |
Hot |
High |
Weak |
Yes |
|
4 |
Rainy |
Mild |
High |
Weak |
Yes |
|
5 |
Rainy |
Cool |
Normal |
Weak |
Yes |
|
6 |
Rainy |
Cool |
Normal |
Strong |
No |
|
7 |
Overcast |
Cool |
Normal |
Strong |
Yes |
|
8 |
Sunny |
Mild |
High |
Weak |
No |
|
9 |
Sunny |
Cool |
Normal |
Weak |
Yes |
|
10 |
Rainy |
Mild |
Normal |
Weak |
Yes |
|
11 |
Sunny |
Mild |
Normal |
Strong |
Yes |
|
12 |
Overcast |
Mild |
High |
Strong |
Yes |
|
13 |
Overcast |
Hot |
Normal |
Weak |
Yes |
|
14 |
Rainy |
Mild |
High |
Strong |
No |
El algoritmo para producir un árbol de esta naturaleza es:
Dado los atributos Ai y un conjunto de Datos D
El problema con este algoritmo, es que se llega a un árbol bastante grande, y quizás con muchas clasificaciones redundantes. Unas maneras de mejorar el algoritmo sería mediante:
Dado que los arboles de decisión son utilizados para la clasificación de información, son mas aptos para los siguiente escenarios:
Existen varios problemas asociado a la creación de los árboles de decisión. Generalmente, como se evidencio anteriormente se puede llegar al sobre-calce, o "overfitting" , de la información. Esto implica que el árbol resultante será de tamaño enorme, y con muchas hipótesis redundantes.
Existe un conjunto de heurísticas que permite evitar el overfitting. Tales incluyen a:
El overfitting no es un problema hasta que es identificado como tal. Para ver si el árbol está sobre entrenado, existen algunas medidas que se pueden efectuar, una vez que el árbol esta listo.
El ID3 se basa, en que el conocimiento reduce incertidumbre, y por lo tanto entrega información. Este concepto se asociará con el termino entropía. Mientras más información se tiene, menos entropía existe, por lo que definiremos a
El valor de la entropía se puede calcular mediante la siguiente función
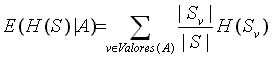
Donde
![]() Es la Entropía de la Fuente Original S
Es la Entropía de la Fuente Original S
![]() Es un atributo que puede tomar Valores(A), valores
distintos
Es un atributo que puede tomar Valores(A), valores
distintos
![]() Es un subconjunto de S, donde A = v
Es un subconjunto de S, donde A = v
![]() Es la Entropía de
Es la Entropía de ![]()
Por lo que podemos definir la ganancia obtenida, de saber el valor de A, mediante la siguiente función
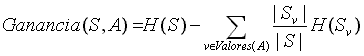
Cuyo valor corresponde al espacio recuperado por el conocimiento de A.
El fundamento detrás de este algoritmo es el teorema de Bayes.
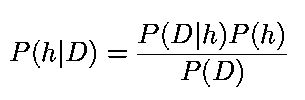
D : Datos de Entrenamiento
h : Hipótesis
El teorema se utiliza para encontrar la hipótesis más probable dado la información de entrenamiento. Para esto, se elige la probabilidad más alta mediante la maximización de la función. Reduciendo Max P(h/D) se llega a:
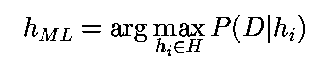
Suponiendo que P(hi)=P(hj)
Suponiendo que existe una función
objetivo: ¦
:X V donde existe un conjunto de
atributos {a1,a2, ... ,an} asociado
a X. El valor mas probable para ¦
(x), (vMAP),
es:
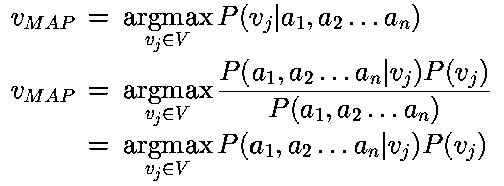
Naive Bayes hace el supuesto de que existe independencia condicional entre los atributos:
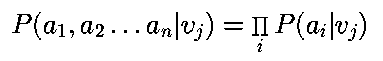
Por lo que se tiene que el clasificador de Naive Bayes es:
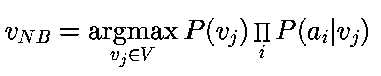
El algoritmo de aprendizaje de Naive Bayes sería entonces:
Aprendizaje_Naive_Bayes(Ejemplos)
{
Para Cada Valor vj
Estimar P(vj)
Para cada valor de atributo ai
Estimar P(ai/vj)
}
Clasificar_nuvea_instancia(x)
VNB = arg MAX P(vj) Õ P(ai/vj)
vjeV aiex
Copyright Nelson Flores 2001™.
Departamento de Ciencias de la Computacion, Universidad de Chile.