|
Tarjeta perforada |
Cinta de papel |
|
Perforadora de tarjetas |
Lectora de tarjetas |
Al comienzo sólo había hardware y aplicaciones. Un programa en ROM lee el binario de una aplicación a partir de una lectora de tarjetas perforadas o una lectora de cintas de papel perforado. Los datos también vienen de la misma forma. La salida se imprime y/o se genera por medio de una perforadora de tarjetas o cintas de papel.
|
Tarjeta perforada |
Cinta de papel |
|
Perforadora de tarjetas |
Lectora de tarjetas |
La aplicación debe incluir todo, incluso debe saber como manejar cada dispositivo. Es decir no hay read ni write, sino que la aplicación debe comandar directamente el medio de entrada/salida, a través de puertas de E/S en el espacio de direcciones. El medio se ve como una secuencia finita de líneas de caracteres sin ninguna estructura en archivos y directorios. La aplicación es responsable de dar alguna estructura al medio.
Si se desea lanzar otra aplicación hay que presionar el botón reset en la consola del computador.
Durante el desarrollo de una aplicación la depuración se lleva a cabo observando las luces de la consola del computador. Dado que sólo un programador puede usar el computador en un instante, los programadores deben reservar hora.
El computador pasa la mayor parte del tiempo ocioso, esperando instrucciones del programador.
El tiempo de computador es mucho más caro que los programadores.
¿Cómo mejorar el rendimiento del computador?
En un sistema batch el procesamiento se hace en lotes de tarjetas perforadas, los que se denominan jobs. El programador no interactúa directamente con el computador. Un job es un lote de tarjetas perforadas por el programador mediante máquinas perforadoras. Estas tarjetas contienen el programa y los datos delimitados por tarjetas de control.
Un operador del computador se encarga de recibir los jobs de varios programadores e introducirlos en una lectora de tarjetas para que sean procesados.
Un programa denominado monitor residente se encarga de leer las tarjetas, interpretar las tarjetas de control y lanzar los programas. Si el programa termina en un error, el monitor residente imprime un dump, que consiste en una imagen hexadecimal de la memoria del computador al momento de ocurrir el error. El operador entrega el dump al programador para que éste determine la causa del error y solucione el problema rehaciendo algunas de las tarjetas.
Mientras el programador piensa, el computador puede procesar otros jobs.
El computador pasa casi el 100% del tiempo ocupado, puesto que el operador es mucho mas diestro en el manejo de las tarjetas que los programadores.
Aunque el computador está ocupado, su componente más costosa, el procesador o CPU pasa gran parte del tiempo ocioso porque la lectura de las tarjetas y la impresión de los resultados son muy lentas.
El término off-line significa fuera de la línea de producción. Aplicado a los sistemas batch, operación off-line significa que la lectura de las tarjetas y la impresión de los resultados no las realiza el computador. Estas actividades se realizan a cabo en procesadores satélites de bajo costo y especializados en una sola actividad.
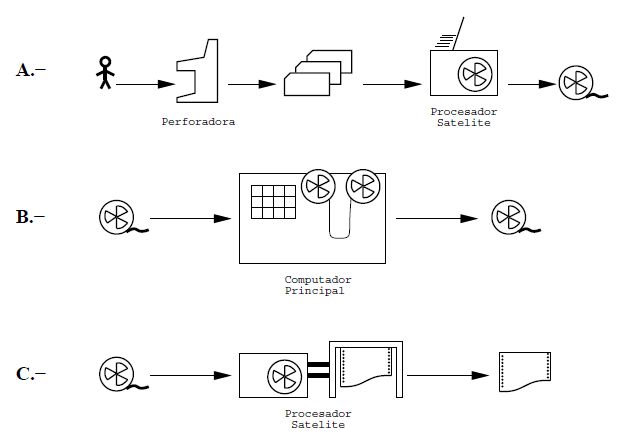
Figura: Componentes de un sistema computacional
Las tarjetas de varios jobs son leídas por un procesador satélite, el que genera una cinta (parte A en la figura) que el operador transporta hacia la unidad de cintas del computador principal. El computador lee estas cintas mucho más rápidamente que las tarjetas (parte B en la figura).
De igual forma, el resultado de los jobs se graba en una o más cintas que son desmontadas por el operador y llevadas a un procesador satélite dedicado a la impresión (parte C en la figura).
Como la lectura de cintas es mucho más rápida que la de tarjetas, se puede lograr un mejor rendimiento del procesador principal asociando varios satélites de lectura y varios satélites de impresión.
En efecto, el costo de los procesadores satélites es marginal frente al costo del procesador principal. Cada vez que se agrega un procesador satélite se aumenta la capacidad de proceso sin comprar un nuevo procesador principal, sólo se aumenta el porcentaje de tiempo de utilización del procesador principal. Por supuesto esto tiene un límite, puesto que llega un momento en que el computador principal no es capaz de leer más cintas. Por lo tanto se agregan procesadores satélites mientras exista capacidad ociosa en el computador principal.
Las técnicas que veremos a continuación apuntan hacia ese mismo objetivo: aumentar el porcentaje de tiempo de utilización del procesador principal agregando otros procesadores dedicados de bajo costo.
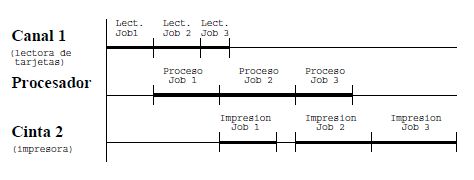
Mientras se lee o escribe una línea (equivalente a una tarjeta), la CPU debe hacer busy-waiting, es decir no realiza ningún trabajo útil. En la figura se observa el típico job que alterna entre lectura de una línea de datos (E), procesamiento de esa línea (P) y escritura del resultado (S). En ella se observa que durante las fases E y S el procesador está ocioso.

Figura:
Alternancia entre lectura, proceso y escritura de un job típico.
Normalmente se entiende por buffering una técnica que consiste en leer/escribir bloques de varias líneas en una sola operación de entrada/salida. Esto disminuye el tiempo total requerido para la entrada/salida, ya que leer/escribir 10 líneas toma en la práctica casi el mismo tiempo que leer/escribir una línea. Esto se debe a que el tiempo de lectura o escritura de una cinta magnética está sobretodo dominado por el tiempo que toma frenar la cinta, retrocederla, acelerarla y esperar a que el cabezal se posicione en el lugar en donde se encuetran los datos. Dada la alta densidad de grabación, el tiempo que toma pasar el cabezal por la porción de cinta que contiene los datos es marginal.
Por ejemplo si en el esquema original el tiempo de proceso estaba dominado por 10000 lecturas de una línea cada una, con buffering factor 10 el tiempo se reduciría drásticamente ya que se realizarían sólo 1000 operaciones de lectura de a 10 líneas que tomarían poco más de un décimo del tiempo sin buffering.
La técnica de buffering es un poco más compleja que lo descrito anteriormente, puesto que también se usan canales para realizar las operaciones de lectura/escritura de bloques en paralelo con el proceso del job. Los canales son procesadores especializados en el movimiento de datos entre memoria y dispositivos. Son ellos los que interactúan con las cintas con mínima intervención de la CPU. La CPU sólo necesita intervenir al comienzo y al final de cada operación de E/S.
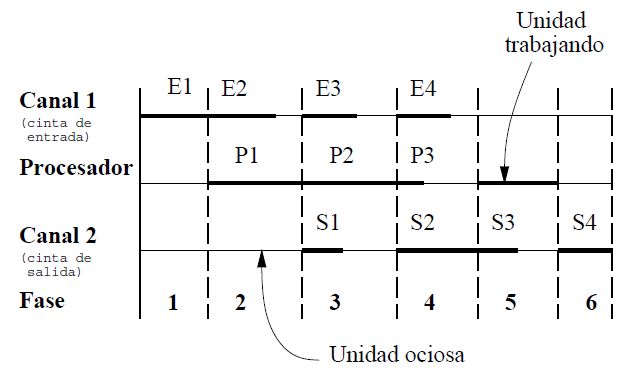
Figure:
Uso de canales para leer, grabar y procesar en paralelo
La figura muestra la técnica de buffering. En ella se observa que en la fase i se superponen las siguientes actividades:
Lectura del bloque Ei+1.
Proceso del bloque que tiene como entrada Ei y salida Si.
Escritura del bloque de salida Si-1
Observe que la fase i+1 sólo puede comenzar cuando todas las partes de la fase i han concluido.
El rendimiento de esta técnica depende de la naturaleza del job que se procesa.
Jobs que usan intensivamente la CPU: En este tipo de jobs el tiempo de proceso de un bloque de datos es muy superior al tiempo de lectura y escritura de un bloque. En este tipo de jobs se alcanza un 100% de utilización de la CPU.
Jobs intensivos en E/S: En este tipo de jobs el tiempo de proceso de un bloque es ínfimo y por lo tanto muy inferior a su tiempo de lectura/escritura. En este tipo de jobs el tiempo de utilización de la CPU puede ser muy bajo.
Con la técnica de buffering se logra un mejor rendimiento del procesador, ya que ahora aumenta su porcentaje de utilización. El aumento del costo es marginal, ya que los canales son mucho mas económicos que el procesador.
El inconveniente con los sistemas off-line es que aumenta el tiempo mínimo transcurrido desde la entrega del job en ventanilla hasta la obtención de los resultados (tiempo de despacho). Este aumento se debe a la demora que significa todo el transporte de cintas entre procesadores satélites y procesador principal. Esta demora se paga aun cuando la cola de jobs esperando proceso es pequeña.
El término On-Line significa que la lectura de tarjetas e impresión de resultados ya no se realizan en procesadores satélites. Las lectoras e impresoras vuelven a conectarse directamente al computador aprovechando los canales de E/S que éste posee (ver figura). La aparición de los sistemas On-Line ocurre gracias a la aparición de los discos magnéticos.
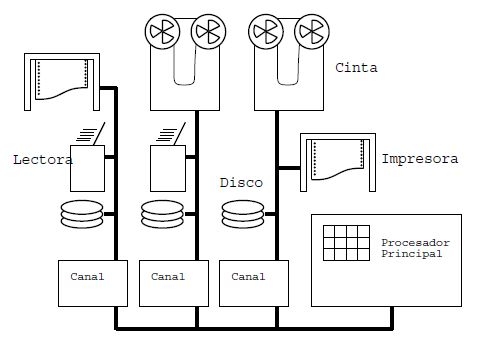
Figura:
Utilización de canales para la conexión de dispositivos
Al igual que los sistemas Off-Line, los sistemas On-Line también permiten lograr un mejor grado de utilización del procesador principal. La idea es que un job nunca lee sus datos directamente de la lectora de tarjetas o imprime directamente sus resultados. Un job obtiene su entrada del disco en un área que se llama el spool y graba su salida también en el spool. Es el monitor residente el que se encarga de leer las tarjetas antes del inicio del job (dejándolas en el disco) e imprimir los resultados después del término del job. Para mejorar el grado de utilización del procesador principal, el monitor residente superpone las siguientes actividades:
Procesamiento del job que corresponde procesar,
Lectura de las tarjetas de uno o más jobs que esperan ser procesados.
Impresión de los resultados de uno o más jobs que ya fueron procesados.
Este esquema se muestra en figura. En ella se observa que la única restricción para procesar el i-ésimo job es que éste haya sido leído por algún canal. Del mismo modo, la única restricción para imprimir el resultado de un job es que ya se haya concluido su proceso.
Al desaparecer los procesadores satélites (off-line) se disminuye la labor del operador en lo que respecta a transportar cintas. Esto disminuye el tiempo de despacho de un job, especialmente cuando la cola de jobs esperando proceso se mantiene pequeña.
El monitor residente logra llevar a cabo todas estas actividades concurrentes, lectura y escritura de muchos dispositivos, por medio de interrupciones. Por supuesto la programación de todas estas rutinas de atención de interrupciones es delicada porque, al igual que los threads modernos, se puede incurrir en data-races. Nótese que programar todo esto con threads sería más simple, pero el problema es que en esa epoca no se habían inventado ni los procesos ni los threads.
Los discos -aunque más rápidos que las cintas- siguen siendo más lentos que la CPU. En procesos intensivos en E/S, la utilización de la CPU sigue siendo baja. Por lo tanto el próximo adelanto sigue apuntando a ocupar esa capacidad ociosa evitando la compra de una nueva CPU.
En un sistema On-Line en un instante dado pueden haber varios procesos listos para ejecutarse (en el spool). En un sistema de multiprogramación (fines de los '60) el monitor residente aprovecha los intervalos de espera de E/S para hacer avanzar otros jobs. Es en esta época en que el monitor residente puede comenzar a llamarse un Sistema Operativo. El sistema operativo debe decidir qué jobs hace avanzar y cuales no, tratando de maximizar el rendimiento del computador. Esto se llama Job scheduling.
Si se lanza un programa defectuoso, su caída provoca la caída de todo el computador. Surge la necesidad de tener un mecanismo de protección entre jobs.
Aparecen las arquitecturas de computadores que son capaces de emular varias máquinas o procesadores virtuales a partir de un solo procesador real. Cada procesador virtual posee:
Un espacio de direcciones virtuales independiente.
Dispositivos virtuales de E/S independientes.
Espacios de almacenamiento de información compartidos.
Tiempo de CPU obtenido en forma de tajadas de tiempo del procesador real.
En los sistemas de multiprogramación se alcanza el mayor rendimiento de un computador.
Desde la aparición de los sistemas batch los programadores tienen muchas dificultades para depurar sus programas. El tiempo de despacho de cada prueba que realizan es bastante prolongado, aún en los sistemas de multiprogramación. A medida que los costos de los computadores bajan, el costo de los programadores y el tiempo de desarrollo se convierten en una componente importante para el usuario. Es decir, por primera vez el problema se centra en mejorar la productividad de los programadores y no la del computador.
A principio de los '70 aparecen los primeros sistemas de tiempo compartido. En estos sistemas varios programadores o usuarios pueden trabajar interactivamente con el computador a través de terminales. Es decir recuperan aquella capacidad de trabajar directamente con el computador, capacidad que habían perdido con la aparición de los sistemas batch.
Ahora cada programador tiene su propia consola en donde puede realizar una depuración más cómoda. Además los usuarios disponen de un sistema de archivos en línea que pueden compartir. Ya no se habla de tiempo de despacho de un job, sino que mas bien tiempo de respuesta de un comando, el que se reduce drásticamente.
En los sistemas de tiempo compartido los usuarios comparten recursos e información -abaratando el costo del sistema- pero manteniendo una relativa independencia entre programadores o usuarios -sin que se molesten entre ellos.
A medida que crece el número de usuarios, el desempeño del sistema se degrada, ya sea por escasez de CPU o escasez de memoria.
A fines de los '70, gracias al progreso en la miniaturización es posible incluir todas las funciones de una CPU en un solo chip, el que se llamó un microprocesador. Con ellos se pueden construir computadores no muy rápidos (comparados con los sistemas de tiempo compartido de esa época), pero que por su bajo costo es posible destinar a un solo programador o usuario, sin necesidad de compartirlo. De ahí su nombre de computador personal.
Los computadores personales no tienen necesidad de incorporar las características de los sistemas batch o de tiempo compartido. Por ello, en un comienzo sólo incorporan un monitor residente (como CP/M-80 o su sucesor MS-DOS) y no un verdadero sistema operativo que soporte multiprogramación o máquinas virtuales. Tampoco necesita canales de E/S (sin embargo los computadores personales de hoy en día sí incorporan todas estas características).
La atracción que ejercen en esa época los computadores personales se debe a que son sistemas interactivos con un tiempo de respuesta predecible y son de bajo costo. Es decir 10 computadores personales son mucho más baratos que un sistema de tiempo compartido para 10 usuarios.
Cada computador personal tiene que tener su propia impresora y disco. Estos recursos continúan siendo caros, pero no pueden ser compartidos. Por otra parte los programadores y usuarios no pueden compartir información, algo que sí pueden hacer en los sistemas de tiempo compartido para desarrollar un proyecto en grupo.
Es así como a mediados de los '80 surgen las redes de computadores personales (como la red Novell). La idea es mantener la visión que tiene un usuario de un computador personal, pero la red le permite compartir el espacio en disco y la impresora con el fin de economizar recursos.
El esquema funciona dedicando uno de los computadores personales a la función de servidor de disco e impresora. Los demás computadores se conectan vía una red al servidor. Una capa en el monitor residente hace ver el disco del servidor como si fuese un disco local en cada computador personal de la red. Lo mismo ocurre con la impresora.
Aunque potencialmente un usuario también podría usar el servidor para sus propios fines, esto no es recomendado, ya que el monitor residente no tiene mecanismo de protección. Si el usuario lanza una aplicación defectuosa, la caída de esta aplicación significará la caída de todos los computadores personales, puesto que el servidor dejará de responder las peticiones de disco o impresión.
La desventaja de este tipo de redes es que no resuelve el problema de compartir información. En efecto, las primeras redes permiten compartir directorios de programas en modo lectura, pero no permiten compartir directorios en modo escritura lo que impide el desarrollo en grupo.
La otra solución surge como respuesta al problema de compartir información. En las estaciones de trabajo se trata de emular un sistema de tiempo compartido, ya que este tipo de sistemas sí permite compartir fácilmente la información. La idea es que el usuario se conecte a un terminal inteligente (estación o puesto de trabajo), es decir que contiene un procesador en donde corren sus programas. Pero la visión que el usuario tiene es la de un sistema de tiempo compartido. El computador es la red, los discos que se ven en este computador pueden estar físicamente en cualquiera de las estaciones de trabajo, es decir el sistema computacional de tiempo compartido está físicamente distribuido en varias estaciones de trabajo. De ahí la apelación de sistemas distribuidos.
Este esquema se implementa interconectando computadores de costo mediano a través de una red. Estos computadores son de costo medio porque incorporan todas las características de un sistema de tiempo compartido (sistema operativo, canales, procesadores virtuales), aunque no son tan rápidos como los computadores de tiempo compartido avanzados de la época.
La desventaja de los sistemas distribuidos y de las redes de PCs está en su alto costo de administración. En efecto, estos sistemas requieren atención continua de operadores que intervienen cuando hay momentos de desconexión de la red. Esto se debe a que en la práctica los sistemas distribuidos se implementan en base a parches al sistema operativo de tiempo compartido que corre en cada estación. Por lo tanto la mayor parte del software no está diseñado para tolerar desconexiones de la red aunque sean momentáneas.
Del mismo modo, las redes de PCs se implementan como parches al monitor residente de los PCs y por lo tanto adolecen del mismo problema. Hoy en día los sistemas operativos se diseñan para ser tolerantes a fallas en la red.
La tercera forma de resolver el problema de los sistemas de tiempo compartido es agregar más procesadores al computador central. Un sistema multiprocesador posee de 2 a 16 procesadores (Intel los denota como cores) de alto desempeño que comparten una misma memoria real.
El sistema multiprocesador se comporte como un sistema de tiempo compartido pero que es capaz de ejecutar efectivamente varios procesos en paralelo, uno en cada procesador. Sin embargo, en los primeros multiprocesadores un proceso nunca se ejecuta al mismo tiempo en más de un procesador. Cuando la cantidad de procesos en ejecución supera al número de procesadores reales, se recurre a la repartición del tiempo de CPU en tajadas, al igual que en los sistemas de tiempo compartido.
Esto significa que el modelo conceptual del proceso no cambió. Un proceso sigue siendo un solo procesador virtual con su propia memoria no compartida. Los threads que comparten el espacio de direcciones aparecieron más tarde.
El problema de los sistemas multiprocesadores es doble. Por el lado del software es difícil implementar sistemas operativos que aprovechen eficientemente todos los procesadores disponibles. Y por lado del hardware, el aumento del costo de un multiprocesador es cuadrático con respecto al número de procesadores que comparten la misma memoria. Hoy en día existen multiprocesadores con 16 cores a precio razonable, pero doblar el número de cores significa cuadruplicar el costo.
Los computadores personales están en el mismo rango de velocidades de las estaciones de trabajo y ambos términos se confunden. Las nuevas implementaciones de los sistemas de tiempo compartido de los '80 han sido ampliamente superadas en rapidez por las estaciones y computadores personales. Sin embargo, estos sistemas de tiempo compartido siguen existiendo debido a la amplia base de aplicaciones que aún necesitan estos computadores para poder correr.
Los computadores personales más veloces se convierten en servidores de disco o bases de datos. Las estaciones de trabajo más veloces se convierten en servidores de disco o aplicación en donde los usuarios pueden correr aquellos programas que necesitan mucha memoria. En algunas instalaciones se usan para ambos fines haciendo que los programas voraces en CPU y memoria degraden el servicio de disco degradando el tiempo de respuesta de todas las estaciones de trabajo.
 +
+