La idea en la base es simple. Cada documento tiene un identificador (o localizador) que se conoce como URL. Este identificador incluye el servicio usado (ftp, http, etc), la máquina donde se encuentra y un nombre de archivo en esa máquina. Ahora se está tratando de incorporar un identificador de nivel superior, que no incorpore la máquina en la que se encuentra, de modo de poder tener réplicas de los documentos más populares en forma transparente para el usuario.
Usando un URL, el cliente se contacta con la m'aquina servidora y pide que le transfiera el documento. En el caso del servicio http, el documento puede contener otros URLs adentro, los cuales son links a otros documentos, potencialmente en otros servidores. De ahí el nombre de telarańa (de hecho uno de los problemas por resolver es la enorme cantidad de links colgantes, o punteros a documentos inexistentes).
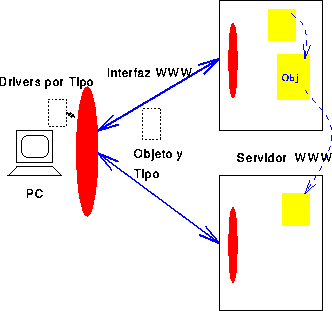
Un principio básico del protocolo, es que los documentos sólo tienen el contenido, no el cómo mostrarlo, que es dependiente del cliente. De esta forma, se independiza el contenido (en el servidor) de la presentación (en el cliente), permitiendo clientes para plataformas tan diversas como Windows, Mac, X-Windows o terminales ASCII (ver Figura 2).
Un documento se compone de múltiples objetos, como texto, URLs, imágenes, etc. Cada objeto tiene un tipo asociado (que se transmite junto con el objeto). Si el cliente tiene un driver asociado a ese tipo (en otras palabras, sabe como mostrarlo), entonces lo usa para ello. Si no tiene el driver, ignora el contenido de ese objeto.
Un tipo especial de objeto es el formulario, que permite pedirle al usuario que complete con texto ciertas zonas del documento, de modo de transmitirlo de vuelta al servidor. Esto permite hacer búsquedas, completar datos, etc.