Tuples and Memory Allocation
Based on these notes by Ben Lerner. Small edits, bug fix regarding heap initialization, changes related to concrete syntax, ANF, and simplified to skip static typing.
1 Computing with arbitrary-sized data
So far, our compiler supports a language with arbitrarily complex arithmetic and logical expressions, function definitions, and function applications. However, our only values are two primitives: integers and booleans. To make our language more fully-featured, we need the ability to handle structured, arbitrarily sized data.
At a high level, we know that there are three kinds of composite data:
Enumerated data types, with a finite set of distinct values
Structured data types, comprised of a finite set of pieces (either named as in structures, or positional as in arrays), where each piece is itself a value
Potentially-recursive union data, with a finite set of distinct categories of values, where each category of value could itself be structured, and where the pieces of those structures could themselves be union data.
The first kind of composite data really only manifests itself in the type system, where we need to be able to say, “These values are part of this enumeration, while those values are not.” Since enumerated data is merely a finite set of constants, we can simulate them merely by using some distinct set of integers.
Since union data is essentially an enumeration of structured data, if we had the ability to create structured data types, then we could encode union data types by adding a field to each value identifying which variant of the union this value belongs to.
But structured data does not admit such a simple encoding. It requires the ability to group several values into one, and use that compound thing as a value: it should be created by some expressions, used by others, and passed to and returned from functions. In other words, structured data is a fundamentally new thing in our language.
We can consider various kinds of structured data such as records with named fields (as
in C structs or Racket define-structs), or indexed data like
arrays. But the simplest form of structured data is the humble pair,
and its bigger cousins the tuples.
Standard reminder: Every time we enhance our source language, we need to consider several things:
Its impact on the concrete syntax of the language
Examples using the new enhancements, so we build intuition of them
Its impact on the abstract syntax and semantics of the language
Any new or changed transformations needed to process the new forms
Executable tests to confirm the enhancement works as intended
2 Adding pairs to our language
2.1 Syntax and examples
We’ll write pairs as
For example, (cons 4 5) is a pair consisting of two numbers. The
flexibility of our grammar, though, allows us to nest pairs inside one another,
as in (cons 3 (cons (or true false) false)) or (cons (cons (cons 1 2) 3) (+ 4 5)),
or any other combination we might attempt. However, in order to use our
pairs, we need to be able to access their components. We’ll do so with two new
primitive operators
The intended semantics are that these two primitives project out the first or
second components of the pairs: (fst (cons 3 4)) == 3 and
(snd (cons 4 (cons true 5))) == (cons true 5).
We can add these expression forms to our AST easily enough, modelling the new accessors as unary primitives:
type expr = ...
| Pair of expr * expr
type prim1 = ... | Fst | Snd2.2 Representing pairs
Introducing pairs into our language is a much more invasive change than it
might appear. For the first time, we have values in our language that are too
big to fit into a register—
If we want to be able to use pairs as arguments to functions, we’d have to communicate to the callee that some of its arguments aren’t uniformly sized, so its initial environment can’t simply map the ith argument to
RBP + 8 * (i + 2). Perhaps we could convey this information via static types, but it certainly would complicate passing pairs to runtime functions likeprint! This starts to break the calling convention, which breaks interoperability and therefore is not something to be done lightly.If we want to be able to return pairs from functions, we have to figure out how to do without using
RAXas the entirety of our answer. Likewise, if we use the X86-64 calling convention, the first arguments are supposed to be in registers. So this breaks the calling convention, and so we should reconsider.If we want to nest pairs inside each other, as in our examples above, then we immediately fail: In
(cons (cons 1 2) 3), there simply is no way to put both1and2at consecutive stack slots (because they’re part of a pair), and also put that entire pair and3at consecutive stack slots —we need at least three slots!
Instead, we’re going to have to look elsewhere to store our pairs: we’re going to use the heap.
2.2.1 Introducing pointers
The heap is another region of memory, at numerically-smaller addresses than our stack, where we can potentially allocate space for whatever values we want. We’ll defer for a moment how exactly to do that, but suppose that we can. Then for each pair we have to evaluate, we can request space for two consecutive words of memory, and store the two halves of the pair in those two words. Crucially for us, the address of (the first of) those two words is unique: no other pair will exist at that exact address. And, even better, one address is small enough to fit into a register. We can use this address as the representation of pairs: it is small enough to pass into and out of functions, and small enough to be placed into the components of another pair. By adding this indirection, we’ve solved all three of the failings above.
2.2.2 Tagging pair values
Of course, now that we have a new kind of value, we need a tag to go with it
to distinguish pairs from booleans or integers.
If we use three bits for tagging, we have 4 tags available (recall that all
even numbers are encoding integers), of which we use one for booleans, so
we have three tags remaining for marking pairs.
We can arbitrarily choose one of them, say 0x1, to mark our
pointers as pairs. This seems risky, though —
The easiest set of known bits to work with is 0b000. Can we ensure that
every memory address we allocate always ends in three zero bits? Yes! “Ends
with three zero bits” is the same thing as saying “multiple of 8”
Conveniently, our pairs are two words wide, which means they’re exactly 16 bytes
long. If we can ensure that every allocation we make is aligned to an
8-byte boundary, then all our addresses will end in 0x000, which means we
are free to use those three bits for whatever tag we need.
2.2.3 Allocating space on the heap
Where can we actually obtain memory from? One possibility is “just use
malloc”, but that just defers the problem. Besides, we have no guarantees
that malloc will enforce our 8-byte-alignment constraint. Instead, we’ll
use malloc once, to obtain a big buffer of space to use, and we’ll
manipulate that buffer directly from our assembly. (See below for how
malloc actually gets itself started.)
Here is one possible strategy for handling memory; there are many others.
Let’s devote one register, R15, to always store a pointer to the next
available heap location. Then “allocating a pair” amounts to storing two
values into [R15] and [R15 + 8], and then incrementing
R15 by 16. (We’ll ignore out-of-memory errors and garbage collection, for
now.) Once again, if R15 started off as a multiple of 8, then after this
process it remains a multiple of 8, so our alignment invariant still holds.
All that remains is to initialize R15 appropriately, which requires
collaboration between main and our_code_starts_here. We need to
allocate a buffer of memory from main, using calloc to
allocate-and-clear the memory, and then pass that pointer in to our code.
In other words, our_code_starts_here now really is a function that takes
in arguments—
int main() {
uint64_t* HEAP = calloc(1024, sizeof(uint64_t)); // Allocate 8KB of memory for now
uint64_t result = our_code_starts_here(HEAP);
print(result);
free(HEAP);
return 0;
}Do Now!
Why must the call to
free(HEAP)happen after the call toprint(result)?
On the callee side, in our_code_starts_here, we need to store this
provided address into R15, but we first need to ensure that it is a
multiple of 8.1Multiples of 8 are actually
guaranteed
for us, but it is worthwhile to ensure this for ourselves, especially if for
some reason we need a more stringent alignment guarantee later on. In
particular, we need to round the address up to the nearest multiple of 8
(because rounding down might give us an unallocated address). The easiest way
to achive this is to add 7 to the address, then round down to the nearest
multiple of 8:
our_code_starts_here:
... ;; basic function prologue as usual
mov R15, RDI ;; Load R15 with the passed-in pointer
add R15, 7 ;; \ add 7 to get above the next multiple of 8
mov R11, 0xfffffffffffffff8L ;; | (R11 is just some scratch register)
and R15, R11 ;; / then round back down.
...2.3 ANF transformations
If you are using ANF, you need to update the transformation to account for pairs.
Given that evaluating a pair actually performs a memory allocation, we cannot treat pairs as immediate values: the value simply isn’t immediately ready. Obviously we do want to be able to bind them to variables, so they must be compound expressions. This leads to a simple design:
type 'a cexpr =
...
| CPair of 'a immexpr * 'a immexpr * 'aWe force the two components of the pair to be immediate, so that the only computational step happening here is the memory allocation itself.
2.4 Compiling pairs and pair accesses
We now have all the tools we need to generate code for all our pair-related expressions. To construct a pair,
... assume the two parts of the pair are already evaluated ...
mov [R15], <first part of pair>
mov [R15 + 8], <second part of pair>
mov RAX, R15 ;; Start creating the pair value itself
add RAX, 0x1 ;; tag the pair
add R15, 16 ;; bump the heap pointerThe order of execution here is important: we must fully evaluate the two
parts of the pair prior to creating the pair, or else the evaluation of each
component might modify R15, leading to non-consecutive memory addresses
for our pair. (ANF conversion ensures this for us; if you don’t use ANF, then
make sure to fully evaluate the pair component expresssions first.) Next we
must save the current value of R15 as our result RAX, so
that we can tag it correctly.
To access the first element of a pair,
mov RAX, <the pair value>
<check that RAX is indeed a pair>
sub RAX, 0x1 ;; untag it
mov RAX, [RAX + 0] ;; treat RAX as a pointer, and get its first wordAccessing the second element uses mov RAX, [RAX + 8] instead.
3 Generalizing to tuples
Tuples are simply longer pairs. We could consider representing tuples as a linked-list of pairs, but that would be quite inefficient. Instead, we’ll generalize everything above that hard-coded “two elements” to become a list of elements. This has some consequences for our representation, but it mostly goes through smoothly.
3.1 Syntax and examples
We’ll write tuples as
A tuple can have zero or more fields, as in (tup 3 4), (tup),
or (tup true false 5). Accessing elements of a
tuple can’t be restricted to two unary primitive operators now, because we
don’t know in advance how large our tuples will be. Instead, we’ll add a more
general expression
The first expression must evaluate to a tuple, and the second to a number that denotes the position we want to access. Of course, in order to ensure safety, we’ll need to check at runtime that the index is a positive number no greater than the size of the tuple.
We’ll represent tuples and tuple accesses as
type expr =
...
| Tuple of expr list (* components of the tuple *)
| Get of expr * expr (* tuple, desired index *)3.2 Representing tuples
We can’t merely store all the items of the tuple consecutively in memory; we need to know how many items there are. Accordingly, we’ll add a header word at the beginning of our tuple in memory, that will store the size of the tuple:

Note carefully that the first word is an actual integer; it is not an encoded value in our language.
Again, we need to tag our tuple values, just as we did above for pairs. Since
tuples generalize pairs, the simplest approach is to eliminate pairs as a
special case, and just use tuples everywhere —0x1
tag to now mean tuples. It’s important to note that we could use both
representations in our compiler —
Do Now!
What are the possible tradeoffs of using just one representation for all tuples, vs using two representations for pairs and tuples separately?
3.3 Compiling tuples and tuple accesses
Again we generalize, assuming that all parts of the tuple have been evaluated.
... ;; assume the parts of the tuple are already evaluated
mov [R15 + 0], <size of the tuple>
mov [R15 + 8 * 1], <first part of tuple>
mov [R15 + 8 * 2], <second part of tuple>
...
mov [R15 + 8 * n], <last part of tuple>
mov RAX, R15 ;; Start creating the tuple value itself
add RAX, 0x1 ;; tag the tuple
add R15, 8 * (n + 1) ;; bump the heap pointerTo implement a tuple access, again we generalize, being careful to account for the header word:
mov RAX, <the tuple value>
<check that RAX is indeed a tuple>
sub RAX, 0x1 ;; untag it
cmp n, 0 ;; \ make sure the index
jl index_too_low ;; / is non-negative
cmp n, [RAX] ;; \ make sure the index is
jge index_too_high ;; / within the size of the tuple
mov RAX, [RAX + 8 * (n + 1)] ;; treat RAX as a pointer, and get its nth wordNote that the code above is only a sketch.
In particular the index n is not available statically, because it is a dynamically-computed value.
4 Memory Allocation
If we’re using R15 to store the memory address where our available heap
space begins, where do we get its initial value from?
main.cusesmalloc(orcalloc) to preallocate a large region of memory that we can use in our programs. But where doesmallocknow where available memory begins?The implementation of
mallocstores several pointers that maintain a clever structure of free and allocated chunks of memory, divided among arenas of allocations of similar sizes. But where can those pointers live? They can’t be on the heap itself, since they help manage the heap!Instead, we need to store those pointers in some well-known, statically known location.
Before, when introducing stacks, we had a simple memory-layout diagram that looked like this:
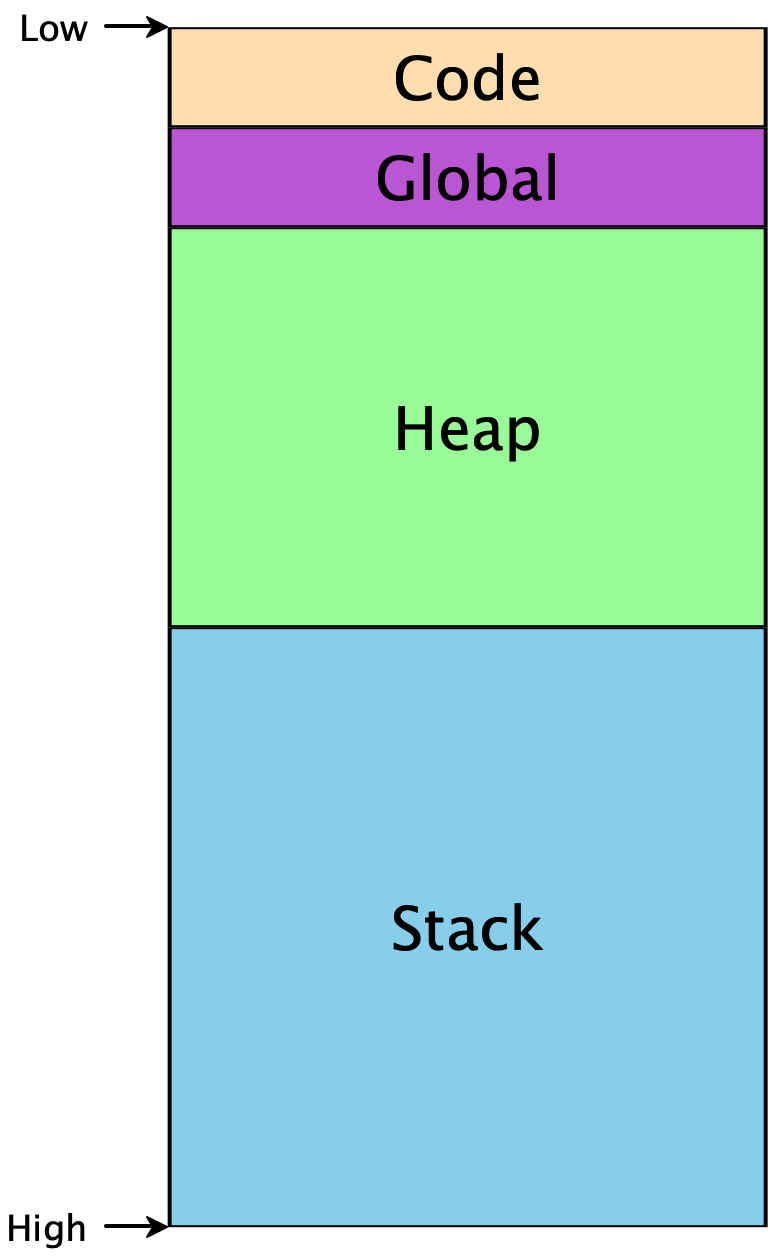
This is a bit simplistic – particularly that “Global” section. What goes in there? Among other things, that section breaks down into smaller sections, with various purposes:
The
.datasection includes global constants known at compile-timeThe
.bsssection includes global names whose values aren’t known (and so are initialized to zero)The
.tdataand.tbsssections are analogous to.dataand.bsssections, but are thread-local
Crucially, the addresses of these four sections are constant, determined by the linker when the executable is produced, and their sizes are known statically: they’re not part of the heap, and any variables stored within them are stored at predictable locations. So the implementation of
mallocultimately relies on a thread-local variable, stored in the.tbsssection and initialized as part of the startup of the program beforemain()ever gets called, to hold the pointer to the first arena.Walking our way back up the list above: since the address of the pointer to the first arena is statically known, it doesn’t need to be passed in via a function parameter, or via a register; it’s now possible for
mallocto correctly provide us with unique, newly-allocated regions of memory, which we can then use in our programs with impunity.
1Multiples of 8 are actually guaranteed for us, but it is worthwhile to ensure this for ourselves, especially if for some reason we need a more stringent alignment guarantee later on.