En esta sección veremos la aplicación de la teoría de árboles a la compresión de datos. Por compresión de datos entendemos cualquier algoritmo que reciba una cadena de datos de entrada y que sea capaz de generar una cadena de datos de salida cuya representación ocupa menos espacio de almacenamiento, y que permite -mediante un algoritmo de descompresión- recuperar total o parcialmente el mensaje recibido inicialmente. A nosotros nos interesa particularmente los algoritmos de compresión sin pérdida, es decir, aquellos algoritmos que permiten recuperar completamente la cadena de datos inicial.
Supongamos que estamos codificando mensajes en binario con un alfabeto
de tamaño ![]() . Para esto se necesitan
. Para esto se necesitan
![]() bits por símbolo, si todos los códigos son de la misma longitud.
bits por símbolo, si todos los códigos son de la misma longitud.
Ejemplo: para el alfabeto A,![]() ,Z de 26 letras se necesitan
códigos de
,Z de 26 letras se necesitan
códigos de
![]() bits
bits
Problema: Es posible disminuir el número promedio de bits por símbolo?
Solución: Asignar códigos más cortos a los símbolos más frecuentes.
Un ejemplo claro de aplicación de este principio es el código morse:
| A | . - |
|---|---|
| B | - . . . |
| E | . |
| Z | - - . . |
Se puede representar mediante un arbol binario:
![\includegraphics[ width=1.0\columnwidth,
keepaspectratio]{arbol-morse.eps}](img6.gif)
Podemos ver en el árbol que letras de mayor probabilidad de aparición (en idioma inglés) están más cerca de la raíz, y por lo tanto tienen una codificación más corta que letras de baja frecuencia.
Problema: este código no es auto-delimitante
Por ejemplo, SOS y IAMS tienen la misma codificación
Para eliminar estas ambigüedades, en morse se usa un tercer delimitador (espacio) para separar el código de cada letra. Se debe tener en cuenta que este problema se produce sólo cuando el código es de largo variable (como en morse), pues en otros códigos de largo fijo (por ejemplo el código ASCII, donde cada caracter se representa por 8 bits) es directo determinar cuales elementos componen cada caracter.
La condición que debe cumplir una codificación para no presentar ambigüedades, es que la codificación de ningun caracter sea prefijo de otra. Esto nos lleva a definir árboles que sólo tienen información en las hojas, como por ejemplo:
![\includegraphics[ width=0.40\columnwidth,
keepaspectratio]{arbol-prefijos.eps}](img8.gif)
Como nuestro objetivo es obtener la secuencia codificada más corta posible, entonces tenemos que encontrar la codificación que en promedio use el menor largo promedio del código de cada letra.
Problema: Dado un alfabeto
![]() tal que
la probabilidad de que la letra
tal que
la probabilidad de que la letra ![]() aparezca en un mensaje es
aparezca en un mensaje es
![]() , encontrar un código libre de prefijos que minimice el largo
promedio del código de una letra.
, encontrar un código libre de prefijos que minimice el largo
promedio del código de una letra.
Supongamos que a la letra ![]() se le asigna una codificación de
largo
se le asigna una codificación de
largo ![]() , entonces el largo esperado es:
, entonces el largo esperado es:
es decir, el promedio ponderado de todas las letras por su probabilidad de aparición.
Ejemplo:
| probabilidad | código | |
| A | 0.30 | 00 |
| B | 0.25 | 10 |
| C | 0.08 | 0110 |
| D | 0.20 | 11 |
| E | 0.05 | 0111 |
| F | 0.12 | 010 |
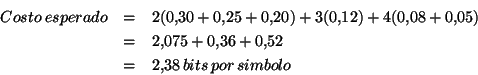
Shannon define la entropía del alfabeto como:
El teorema de Shannon dice que el número promedio de bits esperable para un conjunto de letras y probabilidades dadas se aproxima a la entropía del alfabeto. Podemos comprobar esto en nuestro ejemplo anterior donde la entropia de Shannon es:
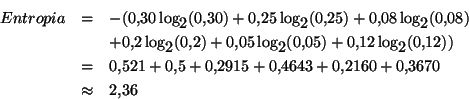
que es bastante cercano al costo esperado de 2.38 que calculamos anteriormente.
A continuación describiremos algoritmos que nos permitan encontrar representaciones que minimicen el costo total.
El algoritmo de Huffman permite construir un código libre de prefijos de costo esperado mínimo.
Inicialmente, comenzamos con ![]() hojas desconectadas, cada una rotulada
con una letra del alfabeto y con una probabilidad (ponderacion o peso).
hojas desconectadas, cada una rotulada
con una letra del alfabeto y con una probabilidad (ponderacion o peso).
Consideremos este conjunto de hojas como un bosque. El algoritmo es:
- Encontrar los 2 árboles de peso mínimo y
unirlos con una nueva raíz que se crea para esto.
- Arbitrariamente, rotulamos las dos
líneas como ´ 0´ y ´ 1´
- Darle a la nueva raíz un peso que es
la suma de los pesos de sus subárboles.
}
Si tenemos que las probabilidades de las letras en un mensaje son:
![\includegraphics[]{huffman-tab.eps}](img17.gif)
Entonces la construcción del árbol de Huffman es (los números en negrita indican los árboles con menor peso):
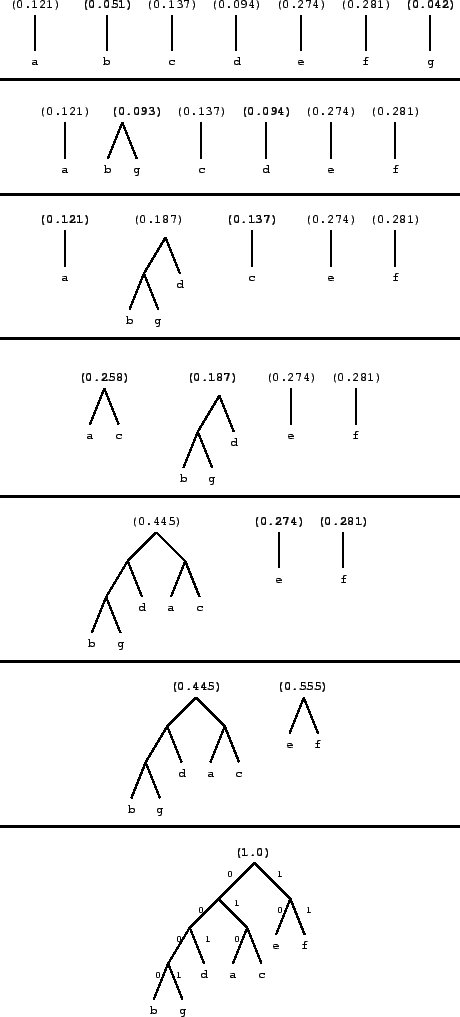
Se puede ver que el costo esperado es de 2,53 bits por letra, mientras que una codificación de largo fijo (igual número de bits para cada símbolo) entrega un costo de 3 bits/letra.
El algoritmo de codificación de Huffman se basa en dos supuestos que le restan eficiencia:
Una codificación que toma en cuenta los problemas de los supuestos enunciados anteriormente para la codificación de Huffman sería una donde no solo se consideraran caracteres uno a uno, sino que donde además se consideraran aquellas secuencias de alta probabilidad en el texto. Por ejemplo, en el texto:
Obtendríamos un mayor grado de eficiencia si además de considerar caracteres como a y b, también considerásemos la secuencia aa al momento de codificar.
Una generalización de esta idea es el algoritmo de Lempel-Ziv. Este algoritmo consiste en separar la secuencia de caracteres de entrada en bloques o secuencias de caracteres de distintos largos, manteniendo una diccionario de bloques ya vistos. Aplicando el algoritmo de Huffman para estos bloques y sus probabilidades, se puede sacar provecho de las secuencias que se repitan con más probabilidad en el texto. El algoritmo de codificación es el siguiente:
2.- Seleccionar el prefijo más largo del
mensaje que calce con alguna secuencia W
del diccionario y eliminar W del mensaje
3.- Codificar W con su índice en el diccionario
4.- Agregar W seguido del primer símbolo del
próximo bloque al diccionario.
5.- Repetir desde el paso 2.
Si el mensaje es
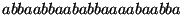
la codificación y los bloques agregados al diccionario serían (donde los bloques reconocidos son mostrados entre paréntesis y la secuencia agregada al diccionario en cada etapa es mostrada como un subíndice):
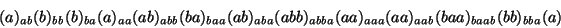
Teóricamente, el diccionario puede crecer indefinidamente, pero en la práctica se opta por tener un diccionario de tamaño limitado. Cuando se llega al límite del diccionario, no se agregan más bloques.
Lempel-Ziv es una de las alternativas a Huffman. Existen varias otras derivadas de estas dos primeras, como LZW (Lempel-Ziv-Welch), que es usado en programas de compresión como el compress de UNIX.