
Un Tipo de dato abstracto (en adelante TDA) es un conjunto de datos u objetos al cual se le asocian operaciones. El TDA provee de una interfaz con la cual es posible realizar las operaciones permitidas, abstrayéndose de la manera en como estén implementadas dichas operaciones. Esto quiere decir que un mismo TDA puede ser implementado utilizando distintas estructuras de datos y proveer la misma funcionalidad.
El paradigma de orientación a objetos permite el encapsulamiento de los datos y las operaciones mediante la definición de clases e interfaces, lo cual permite ocultar la manera en cómo ha sido implementado el TDA y solo permite el acceso a los datos a través de las operaciones provistas por la interfaz.
En este capítulo se estudiarán TDA básicos como lo son las listas, pilas y colas, y se mostrarán algunos usos prácticos de estos TDA.
Una lista se define como una serie de N elementos E1, E2, ..., EN, ordenados de manera consecutiva, es decir, el elemento Ek (que se denomina elemento k-ésimo) es previo al elemento Ek+1. Si la lista contiene 0 elementos se denomina como lista vacía.
Las operaciones que se pueden realizar en la lista son: insertar un elemento en la posición k, borrar el k-ésimo elemento, buscar un elemento dentro de la lista y preguntar si la lista esta vacía.
Una manera simple de implementar una lista es utilizando un arreglo. Sin embargo, las operaciones de inserción y borrado de elementos en arreglos son ineficientes, puesto que para insertar un elemento en la parte media del arreglo es necesario mover todos los elementos que se encuentren delante de él, para hacer espacio, y al borrar un elemento es necesario mover todos los elementos para ocupar el espacio desocupado. Una implementación más eficiente del TDA se logra utilizando listas enlazadas.
A continuación se presenta una implementación en Java del TDA utilizando listas enlazadas y sus operaciones asociadas:
En la implementación con listas enlazadas es necesario tener en cuenta algunos detalles importantes: si solamente se dispone de la referencia al primer elemento, el ańadir o remover en la primera posición es un caso especial, puesto que la referencia a la lista enlazada debe modificarse según la operación realizada. Además, para eliminar un elemento en particular es necesario conocer el elemento que lo antecede, y en este caso, żqué pasa con el primer elemento, que no tiene un predecesor?
Para solucionar estos inconvenientes se utiliza la implementación de lista enlazada con nodo cabecera. Con esto, todos los elementos de la lista tendrán un elemento previo, puesto que el previo del primer elemento es la cabecera. Una lista vacía corresponde, en este caso, a una cabecera cuya referencia siguiente es null.
Los archivos NodoLista.java, IteradorLista.java y Lista.java contienen una implementación completa del TDA lista. La clase NodoLista implementa los nodos de la lista enlazada, la clase Lista implementa las operaciones de la lista propiamente tal, y la clase IteradorLista implementa objetos que permiten recorrer la lista y posee la siguiente interfaz:
Costo de las operaciones en tiempo:
Una pila (stack o pushdown en inglés) es una lista de elementos de la cual sólo se puede extraer el último elemento insertado. La posición en donde se encuentra dicho elemento se denomina tope de la pila. También se conoce a las pilas como listas LIFO (LAST IN - FIRST OUT: el último que entra es el primero que sale).
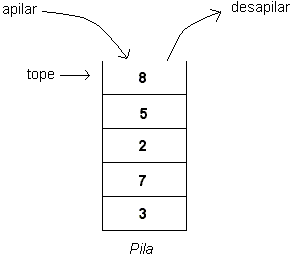
La interfaz de este TDA provee las siguientes operaciones:
Nota: algunos autores definen desapilar como sacar el elemento del tope de la pila sin retornarlo.
A continuación se muestran dos maneras de implementar una pila: utilizando un arreglo y utilizando una lista enlazada. En ambos casos el costo de las operaciones es de O(1).
Para implementar una pila utilizando un arreglo, basta con definir el arreglo del tipo de dato que se almacenará en la pila. Una variable de instancia indicará la posición del tope de la pila, lo cual permitirá realizar las operaciones de inserción y borrado, y también permitirá saber si la pila esta vacía, definiendo que dicha variable vale -1 cuando no hay elementos en el arreglo.
class PilaArreglo
{
private Object[] arreglo;
private int tope;
private int MAX_ELEM=100; // maximo numero de elementos en la pila
public PilaArreglo()
{
arreglo=new Object[MAX_ELEM];
tope=-1; // inicialmente la pila esta vacía
}
public void apilar(Object x)
{
if (tope+1<MAX_ELEM) // si esta llena se produce OVERFLOW
{
tope++;
arreglo[tope]=x;
}
}
public Object desapilar()
{
if (!estaVacia()) // si esta vacia se produce UNDERFLOW
{
Object x=arreglo[tope];
tope--;
return x;
}
}
public Object tope()
{
if (!estaVacia()) // si esta vacia es un error
{
Object x=arreglo[tope];
return x;
}
}
public boolean estaVacia()
{
return tope==-1;
}
}
El inconveniente de esta implementación es que es necesario fijar de antemano el número máximo de elementos que puede contener la pila, MAX_ELEM, y por lo tanto al apilar un elemento es necesario controlar que no se inserte un elemento si la pila esta llena. Sin embargo, en Java es posible solucionar este problema creando un nuevo arreglo más grande que el anterior, el doble por ejemplo, y copiando los elementos de un arreglo a otro:
public void apilar(Object x)
{
if (tope+1<MAX_ELEM) // si esta llena se produce OVERFLOW
{
tope++;
arreglo[tope]=x;
}
else
{
MAX_ELEM=MAX_ELEM*2;
Object[] nuevo_arreglo=new Object[MAX_ELEM];
for (int i=0; i<arreglo.length; i++)
{
nuevo_arreglo[i]=arreglo[i];
}
tope++;
nuevo_arreglo[tope]=x;
arreglo=nuevo_arreglo;
}
}
En este caso no existe el problema de tener que fijar el tamańo máximo de la pila (pero está acotado por la cantidad de memoria disponible). La implementación es bastante simple: los elementos se insertan al principio de la lista (apilar) y siempre se extrae el primer elemento de la lista (desapilar y tope), por lo que basta con tener una referencia al principio de la lista enlazada. Si dicha referencia es null, entonces la pila esta vacía.
class PilaLista
{
private NodoLista lista;
public PilaLista()
{
lista=null;
}
public void apilar(Object x)
{
lista=new NodoLista(x, lista);
}
public Object desapilar() // si esta vacia se produce UNDERFLOW
{
if (!estaVacia())
{
Object x=lista.elemento;
lista=lista.siguiente;
return x;
}
}
public Object tope()
{
if (!estaVacia()) // si esta vacia es un error
{
Object x=lista.elemento;
return x;
}
}
public boolean estaVacia()
{
return lista==null;
}
}
Dependiendo de la aplicación que se le de a la pila es necesario definir que acción realizar en caso de que ocurra overflow (rebalse de la pila) o underflow (intentar desapilar cuando la pila esta vacía). Java posee un mecanismo denominado excepciones, que permite realizar acciones cuando se producen ciertos eventos específicos (como por ejemplo overflow o underflow en una pila).
En ambas implementaciones el costo de las operaciones que provee el TDA tienen costo O(1).
Suponga que una función F realiza un llamado recursivo dentro de su código, lo que se ilustra en la siguiente figura:
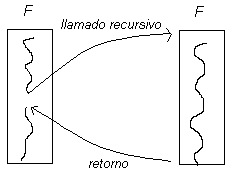
Si la llamada recursiva es lo último que hace la función F, entonces dicha llamada se puede substituir por un ciclo while. Este caso es conocido como tail recursion y en lo posible hay que evitarlo en la programación, ya que cada llamada recursiva ocupa espacio en la memoria del computador, y en el caso del tail recursion es muy simple eliminarla. Por ejemplo:
void imprimir(int[] a, int j) // versión recursiva
{
if (j<a.length)
{
System.out.println(a[j]);
imprimir(a, j+1); // tail recursion
}
}
void imprimir(int[] a, int j) // versión iterativa
{
while (j<a.length)
{
System.out.println(a[j]);
j=j+1;
}
}
En el caso general, cuando el llamado recursivo se realiza en medio de la función F, la recursión se puede eliminar utilizando una pila.
Por ejemplo: recorrido en preorden de un arbol binario.
// "raiz" es la referencia a la raiz del arbol
// llamado inicial: preorden(raiz)
// version recursiva
void preorden(Nodo nodo)
{
if (nodo!=null)
{
System.out.print(nodo.elemento);
preorden(nodo.izq);
preorden(nodo.der);
}
}
// primera version iterativa
void preorden(Nodo nodo)
{
Nodo aux;
Pila pila=new Pila(); // pila de nodos
pila.apilar(nodo);
while(!pila.estaVacia()) // mientras la pila no este vacia
{
aux=pila.desapilar();
if (aux!=null)
{
System.out.print(aux.elemento);
// primero se apila el nodo derecho y luego el izquierdo
// para mantener el orden correcto del recorrido
// al desapilar los nodos
pila.apilar(aux.der);
pila.apilar(aux.izq);
}
}
}
// segunda version iterativa
// dado que siempre el ultimo nodo apilado dentro del bloque if es
// aux.izq podemos asignarlo directamente a aux hasta que éste sea
// null, es decir, el bloque if se convierte en un bloque while
// y se cambia el segundo apilar por una asignacion de la referencia
void preorden(Nodo nodo)
{
Nodo aux;
Pila pila=new Pila(); // pila de nodos
pila.apilar(nodo);
while(!pila.estaVacia()) // mientras la pila no este vacia
{
aux=pila.desapilar();
while (aux!=null)
{
System.out.print(aux.elemento);
pila.apilar(aux.der);
aux=aux.izq;
}
}
}
Si bien los programas no recursivos son más eficientes que los recursivos, la eliminación de recursividad (excepto en el caso de tail recursion) le quita claridad al código del programa. Por lo tanto:
Una cola (queue en inglés) es una lista de elementos en donde siempre se insertan nuevos elementos al final de la lista y se extraen elementos desde el inicio de la lista. También se conoce a las colas como listas FIFO (FIRST IN - FIRST OUT: el primero que entra es el primero que sale).

Las operaciones básicas en una cola son:
Al igual que con el TDA pila, una cola se puede implementar tanto con arreglos como con listas enlazadas. A continuación se verá la implementación usando un arreglo.
Las variables de instancia necesarias en la implementación son:
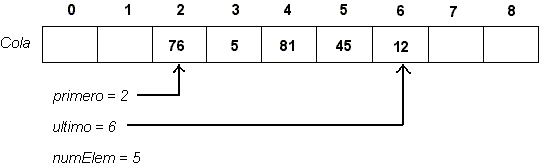
Un detalle faltante es el siguiente: żqué pasa si la variable ultimo sobrepasa el rango de índices del arreglo? Esto se soluciona definiendo que si después de insertar un elemento el índice ultimo == MAX_ELEM, entonces se asigna ultimo = 0 , y los siguientes elementos serán insertados al comienzo del arreglo. Esto no produce ningún efecto en la lógica de las operaciones del TDA, pues siempre se saca el elemento referenciado por el índice primero, aunque en valor absoluto primero > ultimo. Este enfoque es conocido como implementación con arreglo circular, y la forma más fácil de implementarlo es haciendo la aritmética de subíndices módulo MAX_ELEM.
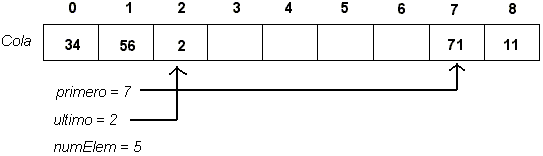
class ColaArreglo
{
private Object[] arreglo;
private int primero, ultimo, numElem;
private int MAX_ELEM=100; // maximo numero de elementos en la cola
public ColaArreglo()
{
arreglo=new Object[MAX_ELEM];
primero=0;
ultimo=-1;
numElem=0;
}
public void encolar(Object x)
{
if (numElem<=MAX_ELEM) // si esta llena se produce OVERFLOW
{
ultimo=(ultimo+1)%MAX_ELEM;
arreglo[ultimo]=x;
numElem++;
}
}
public Object sacar()
{
if (!estaVacia()) // si esta vacia se produce UNDERFLOW
{
Object x=arreglo[primero];
primero=(primero+1)%MAX_ELEM;
numElem--;
return x;
}
}
public boolean estaVacia()
{
return numElem==0;
}
}
Nuevamente en este caso, dependiendo de la aplicación, se debe definir qué hacer en caso de producirse OVERFLOW o UNDERFLOW.
Con esta implementación, todas las operaciones del TDA cola tienen costo O(1).
Una cola de prioridad es un tipo de datos abstracto que almacena un conjunto de datos que poseen una llave perteneciente a algún conjunto ordenado, y permite insertar nuevos elementos y extraer el máximo (o el mínimo, en caso de que la estructura se organice con un criterio de orden inverso).
Es frecuente interpretar los valores de las llaves como prioridades, con lo cual la estructura permite insertar elementos de prioridad cualquiera, y extraer el de mejor prioridad.
Dos formas simples de implementar colas de prioridad son:
Un heap es un árbol binario de una forma especial, que permite su almacenamiento en un arreglo sin usar punteros.
Un heap tiene todos sus niveles llenos, excepto posiblemente el de más abajo, y en este último los nodos están lo más a la izquierda posible.
Ejemplo:
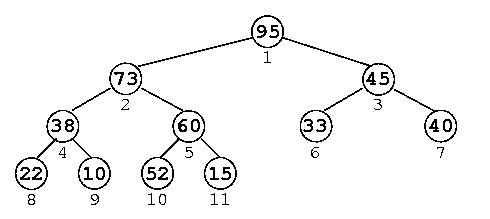
La numeración por niveles (indicada bajo cada nodo) son los subíndices en donde cada elemento sería almacenado en el arreglo. En el caso del ejemplo, el arreglo sería:

La característica que permite que un heap se pueda almacenar sin punteros es que, si se utiliza la numeración por niveles indicada, entonces la relación entre padres e hijos es:
Hijos del nodo j = {2*j, 2*j+1}
Padre del nodo k = floor(k/2)
Un heap puede utilizarse para implementar una cola de prioridad almacenando los datos de modo que las llaves estén siempre ordenadas de arriba a abajo (a diferencia de un árbol de búsqueda binaria, que ordena sus llaves de izquierda a derecha). En otras palabras, el padre debe tener siempre mayor prioridad que sus hijos (ver ejemplo).
Implementación de las operaciones básicas
Inserción:
La inserción se realiza agregando el nuevo elemento en la primera posición libre del heap, esto es, el próximo nodo que debería aparecer en el recorrido por niveles o, equivalentemente, un casillero que se agrega al final del arreglo.
Después de agregar este elemento, la forma del heap se preserva, pero la restricción de orden no tiene por qué cumplirse. Para resolver este problema, si el nuevo elemento es mayor que su padre, se intercambia con él, y ese proceso se repite mientras sea necesario. Una forma de describir esto es diciendo que el nuevo elemento "trepa" en el árbol hasta alcanzar el nivel correcto según su prioridad.
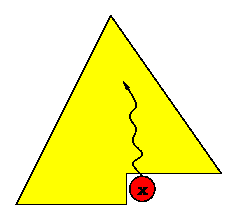
El siguiente trozo de programa muestra el proceso de inserción de un nuevo elemento x:
a[++n]=x;
for(j=n; j>1 && a[j]>a[j/2]; j/=2)
{ # intercambiamos con el padre
t=a[j];
a[j]=a[j/2];
a[j/2]=t;
}
El proceso de inserción, en el peor caso, toma un tiempo proporcional a la altura del árbol, esto es, O(log n).
Extracción del máximo
El máximo evidentemente está en la raíz del árbol (casillero 1 del arreglo). Al sacarlo de ahí, podemos imaginar que ese lugar queda vacante. Para llenarlo, tomamos al último elemento del heap y lo trasladamos al lugar vacante. En caso de que no esté bien ahí de acuerdo a su prioridad (ˇque es lo más probable!), lo hacemos descender intercambiándolo siempre con el mayor de sus hijos. Decimos que este elemento "se hunde" hasta su nivel de prioridad.
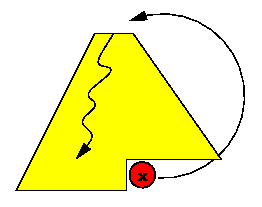
El siguiente trozo de programa implementa este algoritmo:
m=a[1]; # La variable m lleva el máximo
a[1]=a[n--]; # Movemos el último a la raíz y achicamos el heap
j=1;
while(2*j<=n) # mientras tenga algún hijo
{
k=2*j; # el hijo izquierdo
if(k+1<=n && a[k+1]>a[k])
k=k+1; # el hijo derecho es el mayor
if(a[j]>a[k])
break; # es mayor que ambos hijos
t=a[j];
a[j]=a[k];
a[k]=t;
j=k; # lo intercambiamos con el mayor hijo
}
Este algoritmo también demora un tiempo proporcional a la altura del árbol en el peor caso, esto es, O(log n).