|
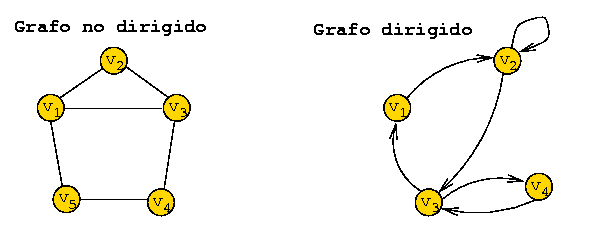
V = {v1,v2,v3,v4,v5}
E = { {v1,v2}, {v1,v3}, {v1,v5}, {v2,v3}, {v3,v4}, {v4,v5} } |
V = {v1,v2,v3,v4}
E = { (v1,v2), (v2,v2), (v2,v3), (v3,v1), (v3,v4), (v4,v3) } |
Un grafo consiste de un conjunto V de vértices (o nodos) y un conjunto E de arcos que conectan a esos vértices.
Ejemplos:
|
V = {v1,v2,v3,v4,v5}
E = { {v1,v2}, {v1,v3}, {v1,v5}, {v2,v3}, {v3,v4}, {v4,v5} } |
V = {v1,v2,v3,v4}
E = { (v1,v2), (v2,v2), (v2,v3), (v3,v1), (v3,v4), (v4,v3) } |
Además de esto, los grafos pueden ser extendidos mediante la adición de rótulos (labels) a los arcos. Estos rótulos pueden representar costos, longitudes, distancias, pesos, etc.
Representaciones de grafos en memoria
Matriz de adyacencia
Un grafo se puede representar mediante una matriz A tal que A[i,j]=1 si hay un arco que conecta vi con vj, y 0 si no. La matriz de adyacencia de un grafo no dirigido es simétrica.
Una matriz de adyacencia permite determinar si dos vértices están conectados o no en tiempo constante, pero requieren O(n2) bits de memoria. Esto puede ser demasiado para muchos grafos que aparecen en aplicaciones reales, en donde |E|<<n2. Otro problema es que se requiere tiempo O(n) para encontrar la lista de vecinos de un vértice dado.
Listas de adyacencia
Esta representación consiste en almacenar, para cada nodo, la lista de los nodos adyacentes a él. Para el segundo ejemplo anterior,
v1: v2
v2: v2, v3
v3: v1, v4
v4: v3
Esto utiliza espacio O(|E|) y permite acceso eficiente a los vecinos, pero no hay acceso aleatorio a los arcos.
Caminos, ciclos y árboles
Un camino es una secuencia de arcos en que el extremo final de cada arco coincide con el extremo inicial del siguiente en la secuencia.
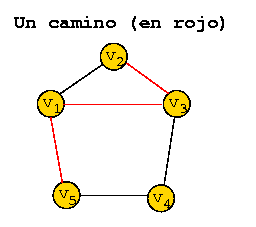
Un camino es simple si no se repiten vértices, excepto posiblemente el primero y el último.
Un ciclo es un camino simple y cerrado.
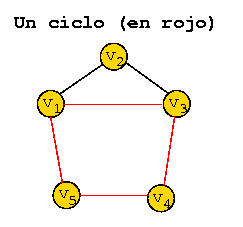
Un grafo es conexo si desde cualquier vértice existe un camino hasta cualquier otro vértice del grafo.
Se dice que un grafo no dirigido es un árbol si es conexo y acíclico.
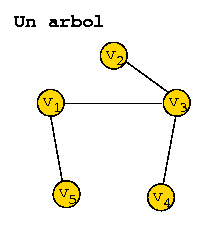
En muchas aplicaciones es necesario visitar todos los vértices del grafo a partir de un nodo dado. Algunas aplicaciones son:
Hay dos enfoque básicos:
Recorrido en Profundidad (DFS)
A medida que recorremos el grafo, iremos numerando correlativamente los nodos encontrados (1,2,...). Suponemos que todos estos números son cero inicialmente, y utilizamos un contador global n, también inicializado en cero.
El siguiente algoritmo en seudo-código muestra cómo se puede hacer este tipo de recorrido recursivamente:
DFS(v) // recorre en profundidad a partir del vértice v
{
++n;
DFN[v]=n;
for(todo w tal que {v,w} está en E y DFN[w]==0)
DFS(w);
}
Para hacer un recorrido en profundidad a partir del nodo v, utilizamos el siguiente programa principal:
n=0;
for(todo w)
DFN[w]=0;
DFS(v);
Si hubiera más de una componente conexa, esto no llegaría a todos los nodos. Para esto podemos hacer:
n=0;
ncc=0; // número de componentes conexas
for(todo w)
DFN[w]=0;
while(existe v en V con DFN[v]==0)
{
++ncc;
DFS(v);
}
Ejercicio: żCómo utilizar este algoritmo para detectar si un grafo es acíclico?
También es posible implementar un recorrido no recursivo utilizando una pila:
Pila pila=new Pila();
n=0;
for(todo w)
DFN[w]=0;
pila.apilar(v); // para recorrer a partir de v
while(!pila.estaVacia())
{
v=pila.desapilar();
if(DFN[v]==0) // primera vez que se visita este nodo
{
++n;
DFN[v]=n;
for(todo w tal que {v,w} esta en E)
pila.apilar(w);
}
}
Recorrido en amplitud (BFS)
La implementación es similar a la de DFS, pero se utiliza una cola en lugar de una pila.
El resultado es que los nodos se visitan en orden creciente en relación a su distancia al nodo origen.
Árboles cobertores
Dado un grafo G no dirigido, conexo, se dice que un subgrafo T de G es un árbol cobertor si es un árbol y contiene el mismo conjunto de nodos que G.
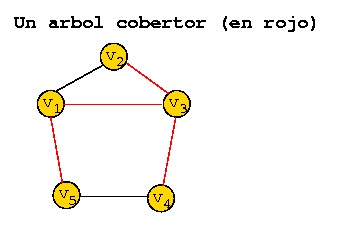
Todo recorrido de un grafo conexo genera un árbol cobertor, consistente del conjunto de los arcos utilizados para llegar por primera vez a cada nodo.
Para un grafo dado pueden existir muchos árboles cobertores.
Si introducimos un concepto de "peso" (o "costo") sobre los arcos,
es interesante tratar de encontrar un árbol cobertor que tenga costo mínimo.
Árbol Cobertor Mínimo
En esta sección veremos dos algoritmos para encontrar un árbol cobertor mínimo para un grafo no dirigido dado, conexo y con costos asociados a los arcos. El costo de un árbol es la suma de los costos de sus arcos.
Algoritmo de Kruskal
Este es un algoritmo del tipo "avaro" ("greedy"). Comienza inicialmente con un grafo que contiene sólo los nodos del grafo original, sin arcos. Luego, en cada iteración, se agrega al grafo el arco más barato que no introduzca un ciclo. El proceso termina cuando el grafo está completamente conectado.
En general, la estrategia "avara" no garantiza que se encuentre un óptimo global, porque es un método "miope", que sólo optimiza las decisiones de corto plazo. Por otra parte, a menudo este tipo de métodos proveen buenas heurísticas, que se acercan al óptimo global.
En este caso, afortunadamente, se puede demostrar que el método "avaro" logra siempre encontrar el óptimo global, por lo cual un árbol cobertor encontrado por esta vía está garantizado que es un árbol cobertor mínimo.
Una forma de ver este algoritmo es diciendo que al principio cada nodo constituye su propia componente conexa, aislado de todos los demás nodos. Durante el proceso de construcción del árbol, se agrega un arco sólo si sus dos extremos se encuentran en componentes conexas distintas, y luego de agregarlo esas dos componentes conexas se fusionan en una sola.
Para la operatoria con componentes conexas supondremos que cada componente conexa se identifica mediante un representante canónico (el "lider" del conjunto), y que se dispone de las siguientes operaciones:
Union(a,b): Se fusionan las componentes canónicas representadas por a y b, respectivamente.
Find(x): Encuentra al representante canónico de la componente conexa a la cual pertenece x.
Con estas operaciones, el algoritmo de Kruskal se puede escribir así:
Ordenar los arcos de E en orden creciente de costo;
C = { {v} | v está en V }; // El conjunto de las componentes conexas
while( |C| > 1 )
{
Sea e={v,w} el siguiente arco en orden de costo creciente;
if(Find(v)!=Find(w))
{
Agregar e al árbol;
Union(Find(v), Find(w));
}
}
El tiempo que demora este algoritmo está dominado por lo que demora la ordenación de los arcos. Si |V|=n y |E|=m, el tiempo es O(m log m) más lo que demora realizar m operaciones Find más n operaciones Union.
Es posible implementar Union-Find de modo que las operaciones Union demoran tiempo constante, y las operaciones Find un tiempo casi constante. Más precisamente, el costo amortizado de un Find está acotado por log* n, donde log* n es una función definida como el número de veces que es necesario tomar el logaritmo de un número para que el resultado sea menor que 1.
Por lo tanto, el costo total es O(m log m) o, lo que es lo mismo, O(m log n) (żpor qué?).
Ejemplo:
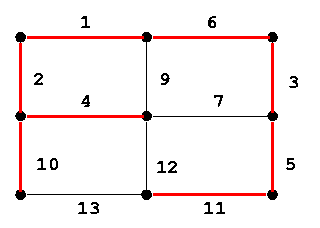
La correctitud del algoritmo de Kruskal viene del siguiente lema:
LemaSea V' subconjunto propio de V, y sea e={v,w} un arco de costo mínimo tal que v está en V' y w está en V-V'. Entonces existe un árbol cobertor mínimo que incluye a e.
Este lema permite muchas estrategias distintas para escoger los arcos del árbol. Veamos por ejemplo la siguiente:
Algoritmo de Prim
Comenzamos con el arco más barato, y marcamos sus dos extremos como "alcanzables". Luego, a cada paso, intentamos extender nuestro conjunto de nodos alcanzables agregando el arco más barato que tenga uno de sus extremos dentro del conjunto alcanzable y el otro fuera de él.
De esta manera, el conjunto alcanzable se va extendiendo como una "mancha de aceite".
Sea e={v,w} un arco de costo mínimo en E;
Agregar e al árbol;
A={v,w}; // conjunto alcanzable
while(A!=V)
{
Encontrar el arco e={v,w} más barato con v en A y w en V-A;
Agregar e al árbol;
Agregar w al conjunto alcanzable A;
}
Para implementar este algoritmo eficientemente, podemos mantener una tabla donde, para cada nodo de V-A, almacenamos el costo del arco más barato que lo conecta al conjunto A. Estos costos pueden cambiar en cada iteración.
Si se organiza la tabla como una cola de prioridad, el tiempo total es
O(m log n).
Si se deja la tabla desordenada y se busca linealmente en cada iteración,
el costo es O(n2).
Esto último es mejor que lo anterior si el grafo es denso.
Distancias Mínimas en un Grafo Dirigido
En este problema los rótulos de los arcos se interpretan como distancias. La distancia (o largo) de un camino es la suma de los largos de los arcos que lo componen.
El problema de encontrar los caminos más cortos tiene dos variantes:
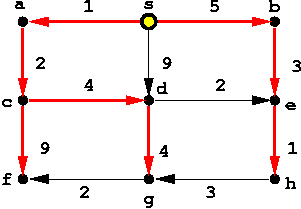
Algoritmo de Dijkstra para los caminos más cortos desde un nodo "origen"
La idea del algoritmo es mantener un conjunto A de nodos "alcanzables" desde el nodo origen e ir extendiendo este conjunto en cada iteración.
Los nodos alcanzables son aquellos para los cuales ya se ha encontrado su camino óptimo desde el nodo origen. Para esos nodos su distancia óptima al origen es conocida. Inicialmente A={s}.
Para los nodos que no están en A se puede conocer el camino óptimo desde s que pasa sólo por nodos de A. Esto es, caminos en que todos los nodos intermedios son nodos de A. Llamemos a esto su camino óptimo tentativo.
En cada iteración, el algoritmo encuentra el nodo que no está en A y cuyo camino óptimo tentativo tiene largo mínimo. Este nodo se agrega a A y su camino óptimo tentativo se convierte en su camino óptimo. Luego se actualizan los caminos óptimos tentativos para los demás nodos.
El algoritmo es el siguiente:
A={s};
D[s]=0;
D[v]=cost(s,v) para todo v en V-A; // infinito si el arco no existe
while(A!=V)
{
Encontrar v en V-A tal que D[v] es mínimo;
Agregar v a A;
for(todo w tal que (v,w) está en E)
D[w]=min(D[w],D[v]+cost(v,w));
}
Implementaciones:
Algoritmo de Floyd para todas las distancias más cortas
Para aplicar este algoritmo, los nodos se numeran arbitrariamente 1,2,...n. Al comenzar la iteración k-ésima se supone que una matriz D[i,j] contiene la distancia mínima entre i y j medida a través de caminos que pasen sólo por nodos intermedios de numeración <k.
Estas distancias se comparan con las que se obtendrían si se pasara una vez por el nodo k, y si de esta manera se obtendría un camino más corto entonces se prefiere este nuevo camino, de lo contrario nos quedamos con el nodo antiguo.
Al terminar esta iteración, las distancias calculadas ahora incluyen la posibilidad de pasar por nodos intermedios de numeración <=k, con lo cual estamos listos para ir a la iteración siguiente.
Para inicializar la matriz de distancias, se utilizan las distancias obtenidas a través de un arco directo entre los pares de nodos (o infinito si no existe tal arco). La distancia inicial entre un nodo y sí mismo es cero.
for(1<=i,j<=n)
D[i,j]=cost(i,j); // infinito si no hay arco entre i y j
for(1<=i<=n)
D[i,i]=0;
for(k=1,...,n)
for(1<=i,j<=n)
D[i,j]=min(D[i,j], D[i,k]+D[k,j]);
El tiempo total que demora este algoritmo es O(n3).
Algoritmo de Warshall para cerradura transitiva
Dada la matriz de adyacencia de un grafo (con D[i,j]=1 si hay un arco entre i y j, y 0 si no), resulta útil calcular la matriz de conectividad, en que el casillero respectivo contiene un 1 si y sólo si existe un camino (de largo >=0) entre i y j. Esta matriz se llama también la cerradura transitiva de la matriz original.
La matriz de conectividad se puede construir de la siguiente manera:
Mejor todavía, podríamos modificar el algoritmo de Floyd para que vaya calculando con ceros y unos directamente, usando las correspondencias siguientes:
|
|
|
|
El resultado se denomina Algoritmo de Warshall:
for(1<=i,j<=n)
D[i,j]=adyacente(i,j); // 1 si existe, 0 si no
for(1<=i<=n)
D[i,i]=1;
for(k=1,...,n)
for(1<=i,j<=n)
D[i,j]=D[i,j] or (D[i,k] and D[k,j]);