
Dado un conjunto de elementos {X1, X2, ..., XN}, todos distintos entre sí, se desea almacenarlos en una estructura de datos que permita la implementación eficiente de las operaciones:
Estas operaciones describen al TDA diccionario. En el presente capítulo se verán distintas implementaciones de este TDA y se estudiarán las consideraciones de eficiencia de cada una de dichas implementaciones.
Una manera simple de implementar el TDA diccionario es utilizando una lista, la cual permite implementar la inserción de nuevos elementos de manera muy eficiente, definiendo que siempre se realiza al comienzo de la lista. El problema que tiene esta implementación es que las operaciones de búsqueda y eliminación son ineficientes, puesto que como en la lista los elementos están desordenados es necesario realizar una búsqueda secuencial. Por lo tanto, los costos asociados a cada operación son:
Otra manera sencilla de implementar el TDA es utilizando un arreglo ordenado. En este caso, la operación de inserción y eliminación son ineficientes, puesto que para mantener el orden dentro del arreglo es necesario "correr" los elementos para dejar espacio al insertar un nuevo elemento. Sin embargo, la ventaja que tiene mantener el orden es que es posible realizar una búsqueda binaria para encontrar el elemento buscado.
Suponga que se dispone del arreglo a, de tamańo n, en donde se tiene almacenado el conjunto de elementos ordenados de menor a mayor. Para buscar un elemento x dentro del arreglo se debe:
Costo de la búsqueda binaria:
T(n) = 1 + T(n/2) (aproximadamente)
T(n) = 2 + T(n/4)
T(n) = 3 + T(n/8)
...
T(n) = k + T(n/2k) para todo k>=0
Escogiendo k = log2n:
=> T(n) = log2n + T(1) = 1 + log2n = O(log n).
La variable i representa el primer casillero del arreglo en donde es posible que se encuentre el elemento x, la variable j representa el último casillero del arreglo hasta donde x puede pertenecer, con j >= i.
Inicialmente: i = 0 y j = n-1.
En cada iteración:
Implementación:
public int busquedaBinaria(int []a, int x)
{
int i=0, j=a.length-1;
while (i<=j)
{
int m=(i+j)/2;
if (x==a[m])
{
return m;
}
else if (x<a[m])
{
j=m-1;
}
else
{
i=m+1;
}
}
return NO_ENCONTRADO; // NO_ENCONTRADO se define como -1
}
Si la única operación permitida entre los elementos del conjunto es la comparación, entonces żqué tan eficiente es la búsqueda binaria?.
Todo algoritmo de búsqueda basado en comparaciones corresponde a algún árbol de decisión. Cada nodo de dicho árbol corresponde al conjunto de elementos candidatos en donde se encuentra el elemento buscado, y que es consistente con las comparaciones realizadas entre los elementos. Los arcos del árbol corresponden a los resultados de las comparaciones, que en este caso pueden ser mayor que o menor que el elemento buscado, es decir, es un árbol de decisión binario.
El número de comparaciones realizadas por el algoritmo de búsqueda es igual a la altura del árbol de decisión (profundidad de la hoja más profunda).
Lema: sea D un árbol binario de altura h. D tiene a lo más 2h hojas.
Demostración: por inducción. Si h = 0 el árbol tiene un solo nodo que necesariamente es una hoja (no tiene hijos), con lo que se tiene el caso base. En el caso general, se tiene una raíz, que no puede ser una hoja, que posee un subárbol izquierdo y derecho, cada uno con una altura máxima de h-1. Por hipótesis de inducción, los subárboles pueden tener a lo más 2h-1 hojas, dando un total de a lo más 2h hojas entre ambos subárboles. Queda entonces demostrado.
Lema: si un árbol binario de altura h tiene t hojas, entonces h ≥ log2 t.
Demostración: directo del lema anterior.
Si n es el número de nodos de elementos del conjunto, el número de respuestas posibles (hojas del árbol de decisión) es de n+1, el lema anterior implica que el costo en el peor caso es mayor o igual que el logaritmo del número de respuestas posibles.
Corolario: cualquier algoritmo de búsqueda mediante comparaciones se demora al menos 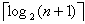 preguntas en el peor caso. Por lo tanto, la búsqueda binaria es óptima.
preguntas en el peor caso. Por lo tanto, la búsqueda binaria es óptima.
Se tiene un conjunto de elementos X1, X2, ..., XN, cuyas probabilidades de acceso son, respectivamente, P1, P2, ..., PN. Naturalmente:
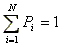
El costo esperado de la búsqueda secuencial es:
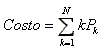
Este costo es mínimo cuando P1>=P2>=P3...>=PN.
żQué pasa si las probabilidades Pk no son conocidas de antemano? En este caso, no es posible ordenar a priori los elementos según su probabilidad de acceso de mayor a menor.
Idea: cada vez que se accesa un elemento Xk se modifica la lista para que los accesos futuros a Xk sean más eficientes. Algunas políticas de modificación de la lista son:
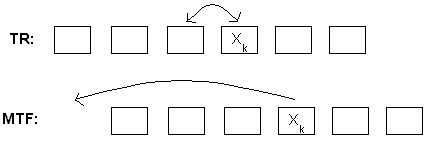
Se puede demostrar que Costooptimo<=CostoMTF<=2Costooptimo.
Un árbol de búsqueda binaria, en adelante ABB, es un árbol binario en donde todos los nodos cumplen la siguiente propiedad (sin perder generalidad se asumirá que los elementos almacenados son números enteros): si el valor del elemento almacenado en un nodo N es X, entonces todos los valores almacenados en el subárbol izquierdo de N son menores que X, y los valores almacenados en el subárbol derecho de N son mayores que X.
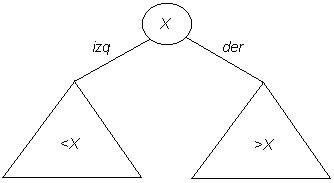
Los ABB permiten realizar de manera eficiente las operaciones provistas por el TDA diccionario, como se verá a continuación.
Esta operación retorna una referencia al nodo en donde se encuentra el elemento buscado, X, o null si dicho elemento no se encuentra en el árbol. La estructura del árbol facilita la búsqueda:
Nótese que el orden en los cuales se realizan los pasos anteriores es crucial para asegurar que la búsqueda en el ABB se lleve a cabo de manera correcta.
Peor caso
Para un árbol dado, el peor caso es igual a la longitud del camino más largo desde la raíz a una hoja, y el peor caso sobre todos los árboles posibles es O(n).
Caso promedio
Supuestos:
Costo de búsqueda exitosa:
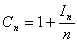
donde In es el largo de caminos internos.
Costo de búsqueda infructuosa:
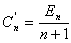
donde En es el largo de caminos externos.
Recordando que En=In+2n, se tiene:
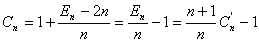
Por lo tanto, la ecuación que relaciona los costos de búsqueda exitosa e infructuosa es: (*)
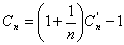
Esto muestra que a medida que se insertan más elementos en el ABB los costos de búsqueda exitosa e infructuosa se van haciendo cada vez más parecidos.
El costo de búsqueda de un elemento en un ABB es igual al costo de búsqueda infructuosa justo antes de insertarlo más 1. Esto quiere decir que si ya habían k elementos en el árbol y se inserta uno más, el costo esperado de búsqueda para este último es 1+C'k. Por lo tanto:
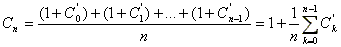
Esta última ecuación implica que:
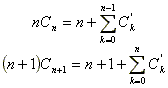
Restando ambas ecuaciones se obtiene: (**)
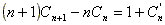
De la ecuación (*) se tiene:
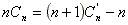
Reemplazando en (**):
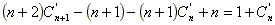
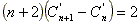
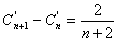
Obteniéndose la siguiente ecuación de recurrencia:
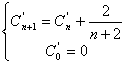
Desenrollando la ecuación: (***)
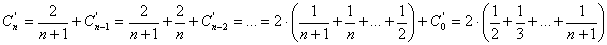
Se define Hn, conocido como números armónicos, como:
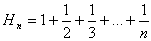
Se puede demostrar que:
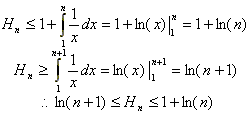
Reemplazando en (***) y recordando (*) se obtiene:
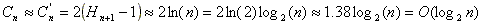
Por lo tanto, el costo promedio de búsqueda en un ABB es O(log(n)).
Para insertar un elemento X en un ABB, se realiza una búsqueda infructuosa de este elemento en el árbol, y en el lugar en donde debiera haberse encontrado se inserta. Como se vio en la sección anterior, el costo promedio de inserción en un ABB es O(log(n)).
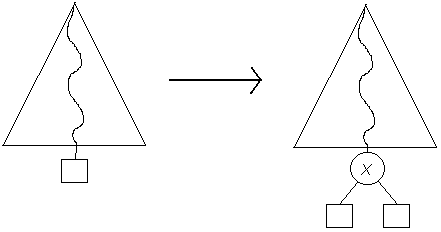
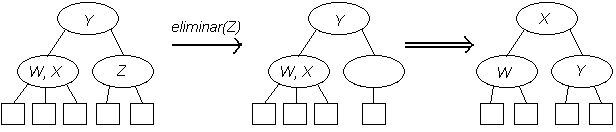
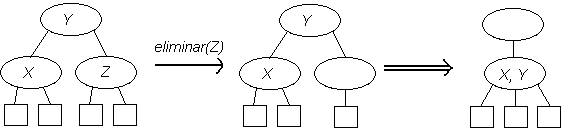
Primero se realiza una búsqueda del elemento a eliminar, digamos X. Si la búsqueda fue infructuosa no se hace nada, en caso contrario hay que considerar los siguientes casos posibles:
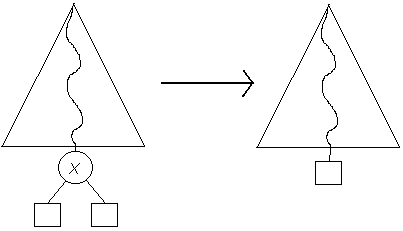
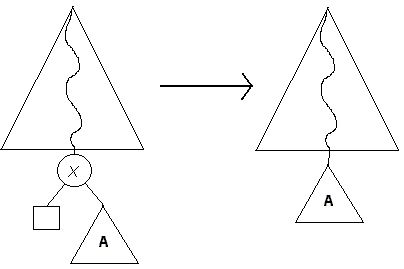
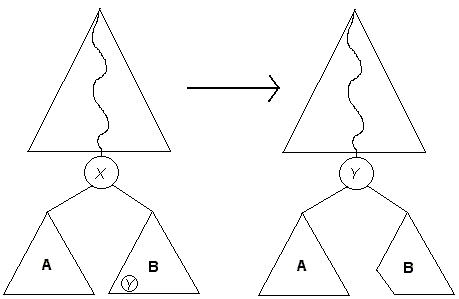
Nótese que el árbol sigue cumpliendo las propiedades de un ABB con este método de eliminación.
Si de antemano se sabe que el número de eliminaciones será pequeńo, entonces la eliminación se puede substituir por una marca que indique si un nodo fue eliminado o no. Esta estrategia es conocida como eliminación perezosa (lazy deletion).
Definición: un árbol balanceado es un árbol que garantiza costos de búsqueda, inserción y eliminación en tiempo O(log(n)) incluso en el peor caso.
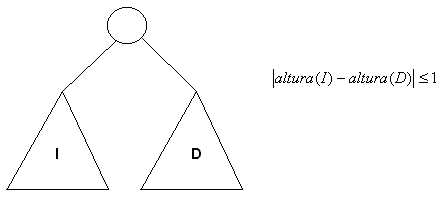
Un árbol AVL (Adelson-Velskii y Landis) es una árbol de búsqueda binaria que asegura un costo O(log(n)) en las operaciones de búsqueda, inserción y eliminación, es decir, posee una condición de balance.
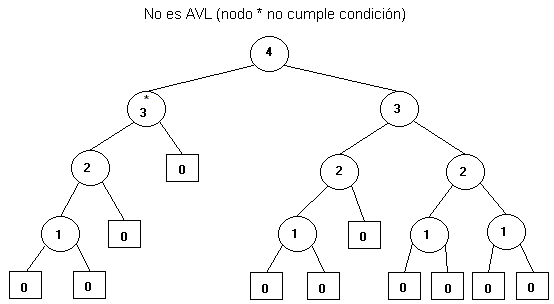
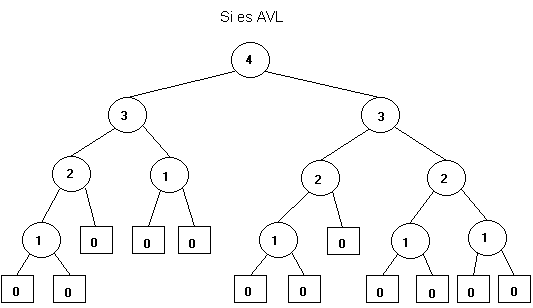
La condición de balance es: un árbol es AVL si para todo nodo interno la diferencia de altura de sus dos árboles hijos es menor o igual que 1.
Por ejemplo: (el número dentro de cada nodo indica su altura)
Problema: para una altura h dada, żcuál es el árbol AVL con mínimo número de nodos que alcanza esa altura?. Nótese que en dicho árbol AVL la diferencia de altura de sus hijos en todos los nodos tiene que ser 1 (demostrar por contradicción). Por lo tanto, si Ah representa al árbol AVL de altura h con mínimo número de nodos, entonces sus hijos deben ser Ah-1 y Ah-2.
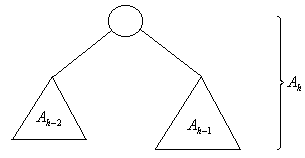
En la siguiente tabla nh representa el número de nodos externos del árbol AVL con mínimo número de nodos internos.
| h | Ah | nh |
|---|---|---|
| 0 |  | 1 |
| 1 | 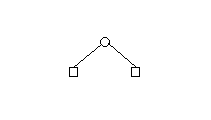 | 2 |
| 2 | 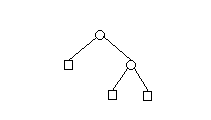 | 3 |
| 3 | 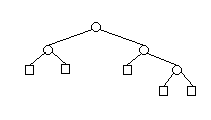 | 5 |
| 4 | 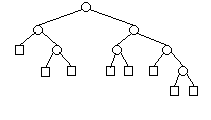 | 8 |
| 5 | 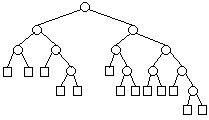 | 13 |
Por inspección: (Fh representa los números de Fibonacci)

Por lo tanto, la altura de un árbol AVL es 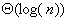 . Esto implica automáticamente que la búsqueda en un AVL tiene costo de en el peor caso.
. Esto implica automáticamente que la búsqueda en un AVL tiene costo de en el peor caso.
La inserción en un AVL se realiza de la misma forma que en un ABB, con la salvedad que hay que modificar la información de la altura de los nodos que se encuentran en el camino entre el nodo insertado y la raíz del árbol. El problema potencial que se puede producir después de una inserción es que el árbol con el nuevo nodo no sea AVL:
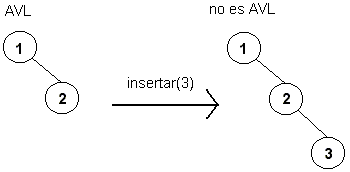
En el ejemplo de la figura, la condición de balance se pierde al insertar el número 3 en el árbol, por lo que es necesario restaurar de alguna forma dicha condición. Esto siempre es posible de hacer a través de una modificación simple en el árbol, conocida como rotación.
Suponga que después de la inserción de un elemento X el nodo desbalanceado más profundo en el árbol es N. Esto quiere decir que la diferencia de altura entre los dos hijos de N tiene que ser 2, puesto que antes de la inserción el árbol estaba balanceado. La violación del balance pudo ser ocasionada por alguno de los siguientes casos:
Dado que el primer y último caso son simétricos, asi como el segundo y el tercero, sólo hay que preocuparse de dos casos principales: una inserción "hacia afuera" con respecto a N (primer y último caso) o una inserción "hacia adentro" con respecto a N (segundo y tercer caso).
El desbalance por inserción "hacia afuera" con respecto a N se soluciona con una rotación simple.
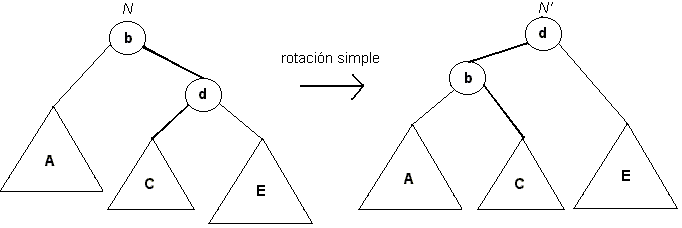
La figura muestra la situación antes y después de la rotación simple, y ejemplifica el cuarto caso anteriormente descrito, es decir, el elemento X fue insertado en E, y b corresponde al nodo N. Antes de la inserción, la altura de N es la altura de C+1. Idealmente, para recuperar la condición de balance se necesitaria bajar A en un nivel y subir E en un nivel, lo cual se logra cambiando las referencias derecha de b e izquierda de d, quedando este último como nueva raíz del árbol, N'. Nótese que ahora el nuevo árbol tiene la misma altura que antes de insertar el elemento, C+1, lo cual implica que no puede haber nodos desbalanceados más arriba en el árbol, por lo que es necesaria una sola rotación simple para devolver la condición de balance al árbol. Nótese también que el árbol sigue cumpliendo con la propiedad de ser ABB.
Claramente un desbalance producido por una inserción "hacia adentro" con respecto a N no es solucionado con una rotación simple, dado que ahora es C quien produce el desbalance y como se vio anteriormente este subárbol mantiene su posición relativa con una rotación simple.
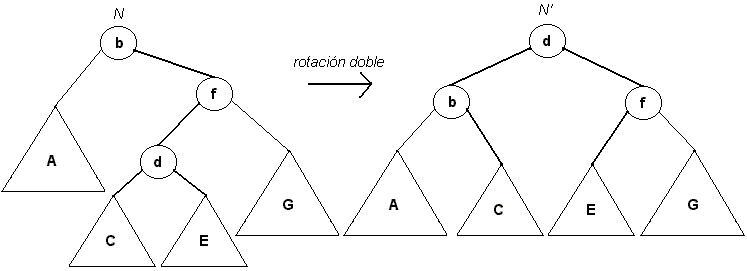
Para el caso de la figura (tercer caso), la altura de N antes de la inserción era G+1. Para recuperar el balance del árbol es necesario subir C y E y bajar A, lo cual se logra realizando dos rotaciones simples: la primera entre d y f, y la segunda entre d, ya rotado, y b, obteniéndose el resultado de la figura. A este proceso de dos rotaciones simples se le conoce como rotación doble, y como la altura del nuevo árbol N' es la misma que antes de la inserción del elemento, ningún elemento hacia arriba del árbol queda desbalanceado, por lo que solo es necesaria una rotación doble para recuperar el balance del árbol después de la inserción. Nótese que el nuevo árbol cumple con la propiedad de ser ABB después de la rotación doble.
La eliminación en árbol AVL se realiza de manera análoga a un ABB, pero también es necesario verificar que la condición de balance se mantenga una vez eliminado el elemento. En caso que dicha condición se pierda, será necesario realizar una rotación simple o doble dependiendo del caso, pero es posible que se requiera más de una rotación para reestablecer el balance del árbol.
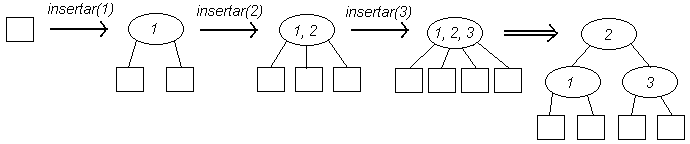
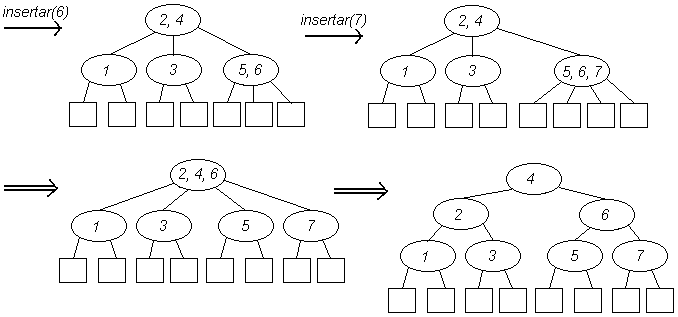
Los árboles 2-3 son árboles cuyos nodos internos pueden contener hasta 2 elementos (todos los árboles vistos con anterioridad pueden contener sólo un elemento por nodo), y por lo tanto un nodo interno puede tener 2 o 3 hijos, dependiendo de cuántos elementos posea el nodo. De este modo, un nodo de un árbol 2-3 puede tener una de las siguientes formas:
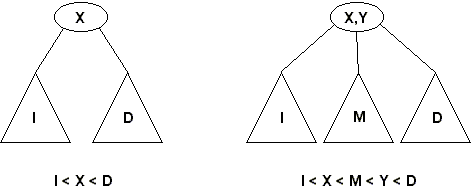
Un árbol 2-3 puede ser simulado utilizando árboles binarios:
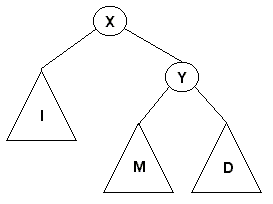
Una propiedad de los árboles 2-3 es que todas las hojas están a la misma profundidad, es decir, los árboles 2-3 son árboles perfectamente balanceados. La siguiente figura muestra un ejemplo de un árbol 2-3:
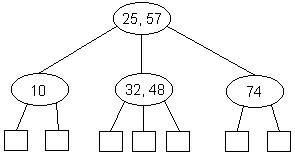
Nótese que se sigue cumpliendo la propiedad de los árboles binarios: nodos internos + 1 = nodos externos. Dado que el árbol 2-3 es perfectamente balanceado, la altura de éste esta acotada por:
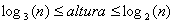
Para insertar un elemento X en un árbol 2-3 se realiza una búsqueda infructuosa y se inserta dicho elemento en el último nodo visitado durante la búsqueda, lo cual implica manejar dos casos distintos:
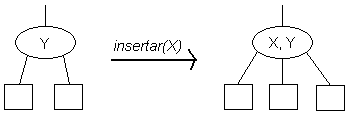
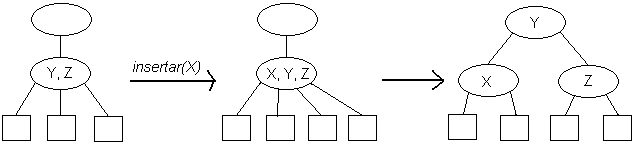
El problema se resuelve a nivel de X y Z, pero es posible que el nodo que contiene a Y ahora este saturado. En este caso, se repite el mismo prodecimiento anterior un nivel más arriba. Finalmente, si la raíz es el nodo saturado, éste se divide y se crea una nueva raíz un nivel más arriba. Esto implica que los árboles 2-3 crecen "hacia arriba".
Ejemplos de inserción en árboles 2-3:

Sin perder generalidad se supondrá que el elemento a eliminar, Z, se encuentra en el nivel más bajo del árbol. Si esto no es así, entonces el sucesor y el predecesor de Z se encuentran necesariamente en el nivel más bajo (żpor qué?); en este caso basta con borrar uno de ellos y luego escribir su valor sobre el almacenado en Z. La eliminación también presenta dos posibles casos:

Si el nodo hermano contiene solo una llave, se le quita un elemento al padre y se inserta en el nodo con underflow.
Si esta operación produce underflow en el nodo padre, se repite el procedimiento anterior un nivel más arriba. Finalmente, si la raíz queda vacía, ésta se elimina.
Costo de las operaciones de búsqueda, inserción y eliminación en el peor caso: .
La idea de los árboles 2-3 se puede generalizar a árboles t - (2t-1), donde t>=2 es un parámetro fijo, es decir, cada nodo del árbol posee entre t y 2t-1 hijos, excepto por la raíz que puede tener entre 2 y 2t-1 hijos. En la práctica, t puede ser bastante grande, por ejemplo t = 100 o más. Estos árboles son conocidos como árboles B (Bayer).
Suponga que los elementos de un conjunto se pueden representar como una secuencia de bits:
Además, suponga que ninguna representación de un elemento en particular es prefijo de otra. Un árbol digital es un árbol binario en donde la posición de inserción de un elemento ya no depende de su valor, sino de su representación binaria. Los elementos en un árbol digital se almacenan sólo en sus hojas, pero no necesariamente todas las hojas contienen elementos (ver ejemplo más abajo). Esta estructura de datos también es conocida como trie.
El siguiente ejemplo muestra un árbol digital con 5 elementos.
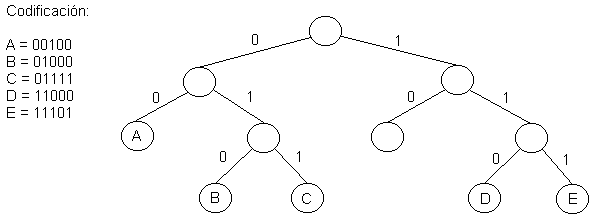
Para buscar un elemento X en un árbol digital se procede de la siguiente manera:
Suponga que se desea insertar el elemento X en el árbol digital. Se realiza una búsqueda infructuosa de X hasta llegar a una hoja, suponga que el último bit utilizado en la búsqueda fue bk. Si la hoja esta vacía, se almacena X en dicha hoja. En caso contrario, se divide la hoja utilizando el siguiente bit del elemento, bk+1, y se repite el procedimiento, si es necesario, hasta que quede sólo un elemento por hoja.
Con este proceso de inserción, la forma que obtiene el árbol digital es insensible al orden de inserción de los elementos.
Suponga que el elemento a eliminar es X. Se elimina el elemento de la hoja, y por lo tanto ésta queda vacía. Si la hoja vacía es hermana de otra hoja no vacía (i.e., una hoja con datos), entonces ambas se fusionan y se repite el procedimiento mientras sea posible.
El costo promedio de búsqueda en un árbol digital es mejor que en un ABB, ya que en un árbol digital la probabilidad que un elemento se encuentre en el subárbol izquierdo o derecho es la misma, 1/2, dado que sólo depende del valor de un bit (0 o 1). En cambio, en un ABB dicha probabilidad es proporcional al "peso" del subárbol respectivo.
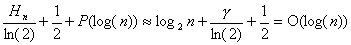
Hn son los números armónicos y P(n) es una función periódica de muy baja amplitud (O(10-6))
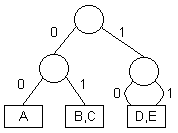
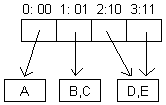
En este tipo de árboles los elementos se almacenan en los nodos internos, al igual que en un ABB, pero la ramificación del árbol es según los bits de las llaves. El siguiente ejemplo muestra un árbol de búsqueda digital (ABD), en donde el orden de inserción es B, A, C, D, E:
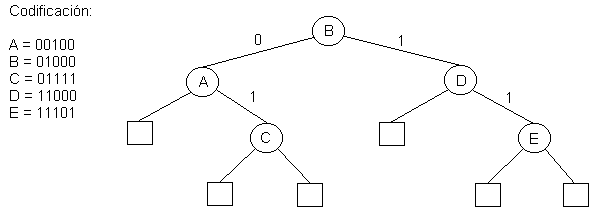
Los ABD poseen un mejor costo promedio de búsqueda que los ABB, pero tambien es O(log(n)).
Al principio del capítulo se vio que una de las maneras simples de implementar el TDA diccionario es utilizando una lista enlazada, pero también se vio que el tiempo de búsqueda promedio es O(n) cuando el diccionario posee n elementos. La figura muestra un ejemplo de lista enlazada simple con cabecera, donde los elementos están ordenados ascendentemente:
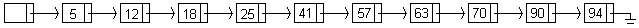
Sin embargo, es posible modificar la estructura de datos de la lista y así mejorar el tiempo de búsqueda promedio. La siguiente figura muestra una lista enlazada en donde a cada nodo par se le agrega una referencia al nodo ubicado dos posiciones más adelante en la lista. Modificando ligeramente el algoritmo de búsqueda, a lo más 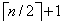 nodos son examinados en el peor caso.
nodos son examinados en el peor caso.
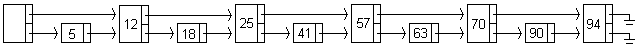
Esta idea se puede extender agregando una referencia cada cuatro nodos. En este caso, a lo más 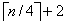 nodos son examinados:
nodos son examinados:

El caso límite para este argumento se muestra en la siguiente figura. Cada 2i nodo posee una referencia al nodo 2i posiciones más adelante en la lista. El número total de referencias solo ha sido doblado, pero ahora a lo más 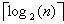 nodos son examinados durante la búsqueda. Note que la búsqueda en esta estructura de datos es básicamente una búsqueda binaria, por lo que el tiempo de búsqueda en el peor caso es O(log n).
nodos son examinados durante la búsqueda. Note que la búsqueda en esta estructura de datos es básicamente una búsqueda binaria, por lo que el tiempo de búsqueda en el peor caso es O(log n).

El problema que tiene esta estructura de datos es que es demasiado rígida para permitir inserciones de manera eficiente. Por lo tanto, es necesario relajar levemente las condiciones descritas anteriormente para permitir inserciones eficientes.
Se define un nodo de nivel k como aquel nodo que posee k referencias. Se observa de la figura anterior que, aproximadamente, la mitad de los nodos son de nivel 1, que un cuarto de los nodos son de nivel 2, etc. En general, aproximadamente n/2i nodos son de nivel i. Cada vez que se inserta un nodo, se elige el nivel que tendrá aleatoriamente en concordancia con la distribución de probabilidad descrita. Por ejemplo, se puede lanzar una moneda al aire, y mientras salga cara se aumenta el nivel del nodo a insertar en 1 (partiendo desde 1). Esta estructura de datos es denominada skip list. La siguiente figura muestra un ejemplo de una skip list:

Suponga que el elemento a buscar es X. Se comienza con la referencia superior de la cabecera. Se realiza un recorrido a través de este nivel (pasos horizontales) hasta que el siguiente nodo sea mayor que X o sea null. Cuando esto ocurra, se continúa con la búsqueda pero un nivel más abajo (paso vertical). Cuando no se pueda bajar de nivel, esto es, ya se está en el nivel inferior, entonces se realiza una comparación final para saber si el elemento X está en la lista o no.
Se procede como en la búsqueda, manteniendo una marca en los nodos donde se realizaron pasos verticales, hasta llegar al nivel inferior. El nuevo elemento se inserta en lo posición en donde debiera haberse encontrado, se calcula aleatoriamente su nivel y se actualizan las referencias de los nodos marcados dependiendo del nivel del nuevo nodo de la lista.
El análisis del costo de búsqueda promedio en una skip list es complicado, pero se puede demostrar que en promedio es O(log n). También se puede demostrar que si se usa una moneda cargada, es decir, que la probabilidad que salga cara es p y la probabilidad que salga sello es q = 1-p, entonces el costo de búsqueda es mínimo para p = 1/e (e = base del logaritmo natural).
Problema: dados n elementos X1 < X2 < ... < Xn, con probabilidades de acceso conocidas p1, p2, ..., pn, y con probabilidades de búsqueda infructuosa conocidas q0, q1, ..., qn, se desea encontrar el ABB que minimice el costo esperado de búsqueda.
Por ejemplo, para el siguiente ABB con 6 elementos:
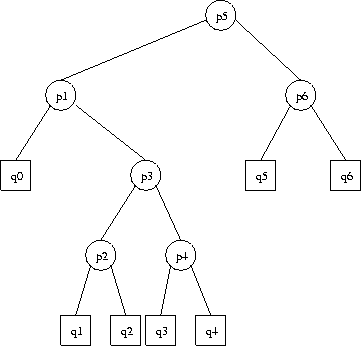
El costo esperado de búsqueda es:
C(q0,q6)=(2q0+2p1+4q1+4p2+4q2+3p3+4q3+4p4+4q4)+p5+(2q5+2p6+2q6)
=(q0+p1+q1+p2+q2+p3+q3+p4+q4+p5+q5+p6+q6)+
(1q0+1p1+3q1+3p2+3q2+2p3+3q3+3p4+3q4)+
(1q5+1p6+1q6)
=W(q0,q6)+C(q0,q4)+C(q5,q6)
Esto es, el costo del árbol completo es igual al "peso" del árbol más los costos de los subárboles. Si la raíz es k:
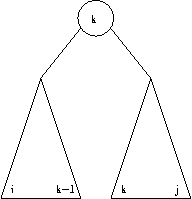
Ci,j = Wi,j + Ci,k-1 + Ck,j
Si el árbol completo es óptimo, entonces los subárboles también lo son, pero al revés no necesariamente es cierto, porque la raíz k puede haberse escogido mal. Luego, para encontrar el verdadero costo óptimo C_opti,j es necesario probar con todas las maneras posibles de elegir la raíz k.
C_opti,j = mini+1<=k<=j {Wi,j + C_opti,k-1 + C_optk,j}
C_opti,i = 0 para todo i=0..n
Note que el "peso" Wi,j no depende de la variable k.
for (i=0; i<=n; i++)
{
C[i,i]=0; // subarboles de tamaño 0
W[i,i]=qi;
}
for (l=1; l<=n; l++)
for (i=0; i<=n-l; i++)
{
j=i+l;
W[i,j]=W[i,j-1]+pj+qj;
C[i,j]=mini+1<=k<=j {W[i,j]+C[i,k-1]+C[k,j]}
}
Tiempo: O(n3).
Una mejora: se define ri,j como el k que minimiza mini+1<=k<=j {W[i,j]+C[i,k-1]+C[k,j]}. Intuitivamente ri,j-1 <= ri,j <= ri+1,j, y como ri,j-1 y ri+1,j ya son conocidos al momento de calcular ri,j, basta con calcular minri,j-1 <= k <= ri+1,j {W[i,j]+C[i,k-1]+C[k,j]}.
Con esta mejora, se puede demostrar que el método demora O(n2) (Ejercicio: demostrarlo).
Esta estructura garantiza que para cualquier secuencia de M operaciones en un árbol, empezando desde un árbol vacío, toma a lo más tiempo O(M log(N)). A pesar que esto no garantiza que alguna operación en particular tome tiempo O(N), si asegura que no existe ninguna secuencia de operaciones que sea mala. En general, cuando una secuencia de M operaciones toma tiempo O(M f(N)), se dice que el costo amortizado en tiempo de cada operación es O(f(N)). Por lo tanto, en un splay tree los costos amortizados por operación son de O(log(N)).
La idea básica de un splay tree es que después que un valor es insertado o buscado en el árbol, el nodo correspondiente a este valor se "sube" hasta la raíz del árbol a través de rotaciones (similares a las rotaciones en los árboles AVL). Una manera de realizar esto, que NO funciona, es realizar rotaciones simples entre el nodo accesado y su padre hasta dejar al nodo accesado como raíz del árbol. El problema que tiene este enfoque es que puede dejar otros nodos muy abajo en el árbol, y se puede probar que existe una secuencia de M operaciones que toma tiempo O(MN), por lo que esta idea no es muy buena.
La estrategia de "splaying" es similar a la idea de las rotaciones simples. Si el nodo k es accesado, se realizarán rotaciones para llevarlo hasta la raíz del árbol. Sea k un nodo distinto a la raíz del árbol. Si el padre de k es la raíz del árbol, entonces se realiza una rotación simple entre estos dos nodos. En caso contrario, el nodo k posee un nodo padre p y un nodo "abuelo" a. Para realizar las rotaciones se deben considerar dos casos posibles (más los casos simétricos).
El primer caso es una inserción zig-zag, en donde k es un hijo derecho y p es un hijo izquierdo (o viceversa). En este caso, se realiza una rotación doble estilo AVL:
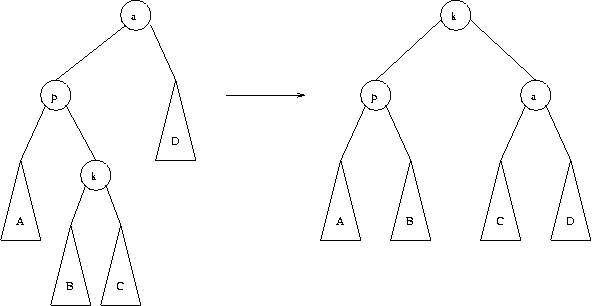
El otro caso es una inseción zig-zig, en donde k y p son ambos hijos izquierdo o derecho. En este caso, se realiza la transformación indicada en la figura siguiente:
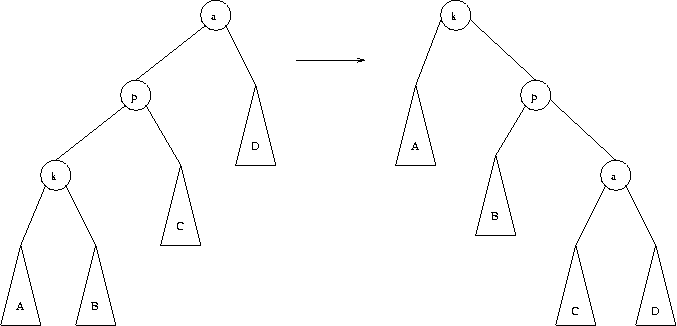
El efecto del splaying es no sólo de mover el nodo accesado a la raíz, sino que sube todos los nodos del camino desde la raíz hasta el nodo accesado aproximadamente a la mitad de su profundidad anterior, a costa que algunos pocos nodos bajen a lo más dos niveles en el árbol.
El siguiente ejemplo muestra como queda el splay tree luego de accesar al nodo d.
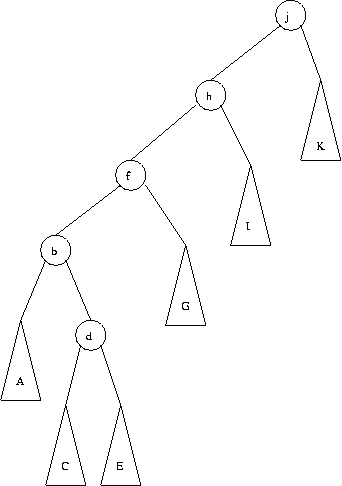
El primer paso es un zig-zag entre los nodos d, b y f.
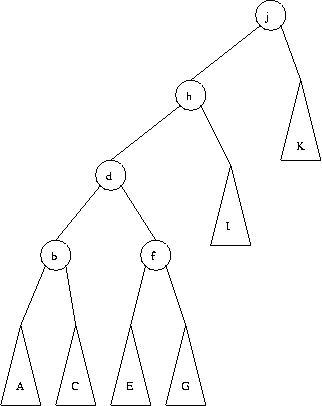
El último paso es un zig-zig entre los nodos d, h y j.
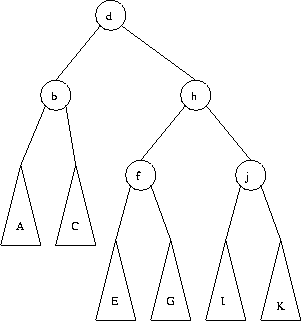
Para borrar un elemento de un splay tree se puede proceder de la siguiente forma: se realiza una búsqueda del nodo a eliminar, lo cual lo deja en la raíz del árbol. Si ésta es eliminada, se obtienen dos subárboles Sizq y Sder. Se busca el elemento mayor en Sizq, con lo cual dicho elemento pasa a ser su nueva raíz, y como era el elemento mayor Sizq ya no tiene hijo derecho, por lo que se cuelga Sder como subárbol derecho de Sizq, con lo que termina la operación de eliminación.
El análisis de los splay trees es complejo, porque debe considerar la estructura cambiante del árbol en cada acceso realizado. Por otra parte, los splay trees son más fáciles de implementar que un AVL dado que no hay que verificar una condición de balance.
Suponga que desea almacenar n números enteros, sabiendo de antemano que dichos números se encuentran en un rango conocido 0, ..., k-1. Para resolver este problema, basta con crear un arreglo de valores booleanos de tamańo k y marcar con valor true los casilleros del arreglo cuyo índice sea igual al valor de los elementos a almacenar. Es fácil ver que con esta estructura de datos el costo de búsqueda, inserción y eliminación es O(1).

Este enfoque tiene dos grandes problemas:
Una manera de resolver estos problemas es usando una función h, denominada función de hash, que transorme un elemento X, perteneciente al universo de elementos posibles, en un valor h(X) en el rango [0, ..., m-1], con m << k. En este caso, se marca el casillero cuyo índice es h(X) para indicar indicar que el elemento X pertenece al conjunto de elementos. Esta estructura de datos es conocida como tabla de hashing.
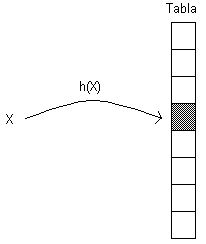
La función h debe ser de tipo pseudoaleatorio para distribuir las llaves uniformemente dentro de la tabla, es decir, Pr( h(X) = z) = 1/m para todo z en [0, ..., m-1]. La llave X se puede interpretar como un número entero, y las funciones h(X) típicas son de la forma:
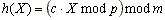
donde c es una constante, p es un número primo y m es el tamańo de la tabla de hashing. Distintos valores para estos parámetros producen distintas funciones de hash.
Problema de este nuevo enfoque: colisiones.
La paradoja de los cumpleańos
żCuál es el número n mínimo de personas que es necesario reunir en una sala para que la probabilidad que dos de ella tengan su cumpleańos en el mismo día sea mayor que 1/2?
Sea dn la probabilidad que no haya coincidencia en dos fechas de cumpleańos. Se tiene que:
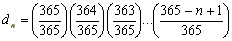
żCuál es el mínimo n tal que dn < 1/2?
Respuesta: n = 23 => dn = 0.4927. Note que 23 es una "pequeńa" fracción de 365.
Esto quiere decir que con una pequeńa fracción del conjunto de elementos es posible tener colisiones con alta probabilidad.
Para resolver el problema de las colisiones, existen dos grandes familias de métodos:
La idea de este método es que todos los elementos que caen en el mismo casillero se enlacen en una lista, en la cual se realiza una búsqueda secuencial.
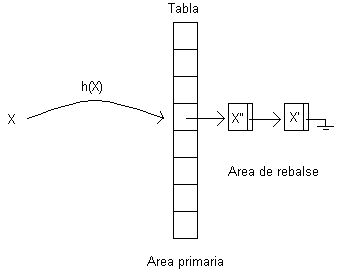
Se define para un conjunto con n elementos:
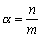 : factor de carga de la tabla.
: factor de carga de la tabla.
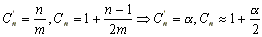
Esto implica que el costo esperado de búsqueda sólo depende del factor de carga 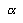 , y no del tamańo de la tabla.
, y no del tamańo de la tabla.
Hashing con listas mezcladas
En este caso no se usa área de rebalse, sino que los elementos se almacenan en cualquier lugar libre del área primaria.
Ejemplo: h(X)= X mod 10
Los costos esperados de búsqueda son:
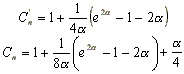
Eliminación en tablas de hashing con encadenamiento
Con listas separadas el algoritmo es simple, basta con eliminar el elemento de la lista enlazada correspondiente. En el caso de las lista mezcladas, el algoritmo es más complejo (ejercicio).
En general, esto puede ser visto como una sucesión de funciones de hash {h0(X), h1(X), ...}. Primero se intenta con tabla[h0(X)], si el casillero está ocupado se prueba con tabla[h1(X)], y así sucesivamente.
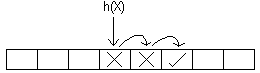
Linear probing
Es el método más simple de direccionamiento abierto, en donde las funciones de hash se definen como:
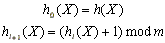
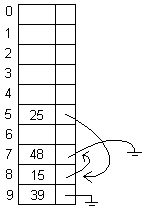
Costo esperado de búsqueda:
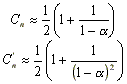
Para una tabla llena:
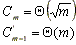
Cuando la tabla de hashing está muy llena, este método resulta ser muy lento.
| Cn | Cn' |
|---|---|---|
| .6 | 1.75 | 3.63 |
| .7 | 2.17 | 6.06 |
| .8 | 3 | 13 |
| .9 | 5.50 | 50.50 |
| .99 | 50.50 | 5,000.50 |
| .999 | 500.50 | 500,000.50 |
A medida que la tabla se va llenando, se observa que empiezan a aparecer clusters de casilleros ocupados consecutivos:

Si la función de hash distribuye los elementos uniformemente dentro de la tabla, la probabilidad que un cluster crezca es proporcional a su tamańo. Esto implica que una mala situación se vuelve peor cada vez con mayor probabilidad. Sin embargo, este no es todo el problema, puesto que lo mismo sucede en hashing con encadenamiento y no es tan malo. El verdadero problema ocurre cuando 2 clusters están separados solo por un casillero libre y ese casillero es ocupado por algún elemento: ambos clusters se unen en uno mucho más grande.
Otro problema que surge con linear probing es conocido como clustering secundario: si al realizar la búsqueda de dos elementos en la tabla se encuentran con el mismo casillero ocupado, entonces toda la búsqueda subsiguiente es la misma para ambos elementos.
Eliminación de elementos: no se puede eliminar un elemento y simplemente dejar su casillero vacío, puesto que las búsquedas terminarían en dicho casillero. Existen dos maneras para eliminar elementos de la tabla:
Hashing doble
En esta estrategia se usan dos funciones de hash: una función 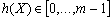 conocida como dirección inicial, y una función
conocida como dirección inicial, y una función 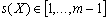 conocida como paso. Por lo tanto:
conocida como paso. Por lo tanto:
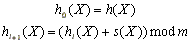
Elegir m primo asegura que se va a visitar toda la tabla antes que se empiecen a repetir los casilleros. Nota: sólo basta que m y s(X) sean primos relativos (ejercicio: demostralo por contradicción).
El análisis de eficiencia de esta estrategia es muy complicado, y se estudian modelos idealizados: muestreo sin reemplazo (uniform probing) y muestreo con reemplazo (random probing), de los cuales se obtiene que los costos de búsqueda esperado son:
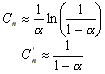
Para una tabla llena:
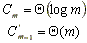
Si bien las secuencias de casilleros obtenidas con hashing doble no son aleatorias, en la práctica su rendimiento es parecido a los valores obtenidos con los muestreos con y sin reemplazo.
| Cn | Cn' |
|---|---|---|
| .6 | 1.53 | 2.5 |
| .7 | 1.72 | 3.33 |
| .8 | 2.01 | 5 |
| .9 | 2.56 | 10 |
| .99 | 4.65 | 100 |
| .999 | 6.91 | 1,000 |
Existen heurísticas para resolver el problema de las colisiones en hashing con direccionamiento abierto, como por ejemplo last-come-first-served hashing (el elemento que se mueve de casillero no es el que se inserta sino el que ya lo ocupaba) y Robin Hood hashing (el elemento que se queda en el casillero es aquel que se encuentre más lejos de su posición original), que si bien mantienen el promedio de búsqueda con respecto al método original (first-come-first-served) disminuyen dramáticamente su varianza.
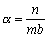 . Por ejemplo, utilizando hashing encadenado:
. Por ejemplo, utilizando hashing encadenado:
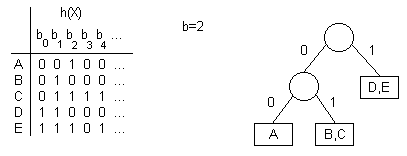
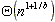 .
.